
PostgreSQL 数据目录深度揭秘
一 概述
PostgreSQL是一个功能非常强大的、源代码开放的客户/服务器关系型数据库管理系统(RDBMS),PostgreSQL被业界誉为“先进的开源数据库”,支持NoSQL数据类型(JSON/XML/hstore),主要面向企业复杂查询SQL的OLTP业务场景,提供PostGIS地理信息引擎、阿里云自研多维多模时空信息引擎等。
本文着重介绍PostgreSQL的数据目录,其中保存着配置文件、数据文件、事务日志和WAL日志等重要文件,所有客户创建的数据文件和初始配置文件都可以在数据目录中找到,因此数据目录是重要的客户价值所在。
二 名词
1 OID
数据库对象是数据库存储或引用的数据结构体,数据库本身也是数据库对象,同时包括表、索引、视图、序列和函数等。Object ID是数据库对象的唯一标识符,保存在无符号四字节的整形变量中,所有数据库对象各自对应一个OID。PostgreSQL有两个视图各司其职,分别保存着不同类别的OID,其中pg_database保存数据库本身对象的OID,pg_class保存表、索引和序列等对象的OID。
2 Relation
关系代表非数据库本身的数据库对象,包括表、视图、索引和toast等,不包括数据库本身。
3 MVCC
Multi-Version-Concurrency-Control是一种并发控制机制,数据库引擎根据不同的事务隔离级别,通过查询事务快照和事务提交日志来完成元组的可见性检查。如果希望理解数据库机制原理,MVCC是必不可少的学习知识。
4 Page
数据库文件在Linux平台被划分为默认8K固定长度的page进行管理,通过启动参数BLCKSZ可以预设page的大小。如果page设低了,相同数据量的文件需要分裂成更多的page,IO次数和索引分裂次数都会增加,性能会降低较多;如果page设高了,page内部的数据检索效率会降低,性能一样会降低不少,一般来说8K和16K对于数据库系统来说是最优解。
三 数据目录
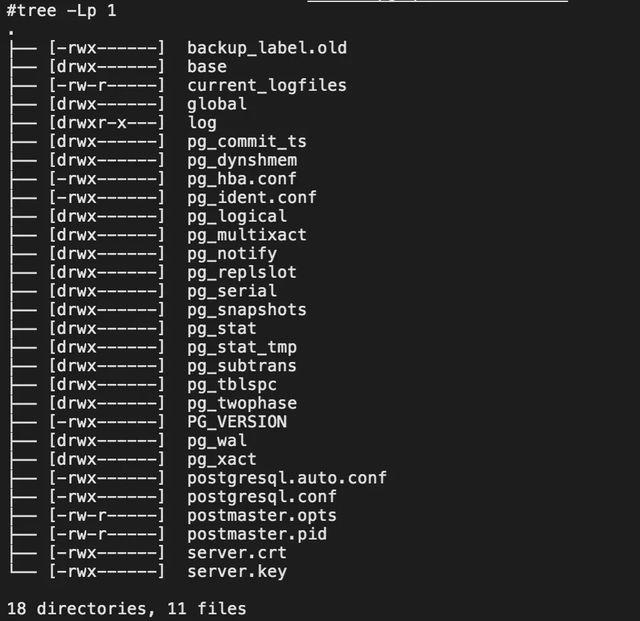
数据目录默认在/var/lib/pgsql/data下,支持使用环境变量$PG_DATA管理。下图所示是数据目录的一级结构,后续会重点介绍具有代表性的重要文件和目录,比如base、pg_xact等。
四 base
1 概述
base目录存储用户创建的数据库文件,及隶属于用户数据库的所有关系,比如表、索引等。
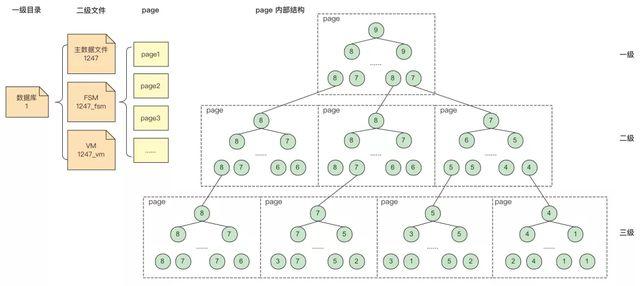
2 一级目录
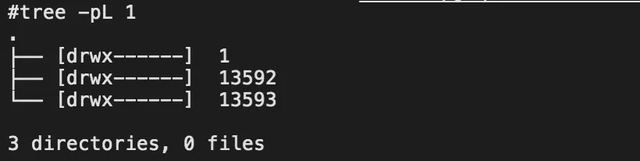
目录结构分为两级,第一级结构如下图所示,一级目录名是用户数据库对象的OID,1代表的是postgres数据库,一级目录内的二级子文件都是隶属于该数据库对象的关系,包括表、索引、视图等。
3 二级文件
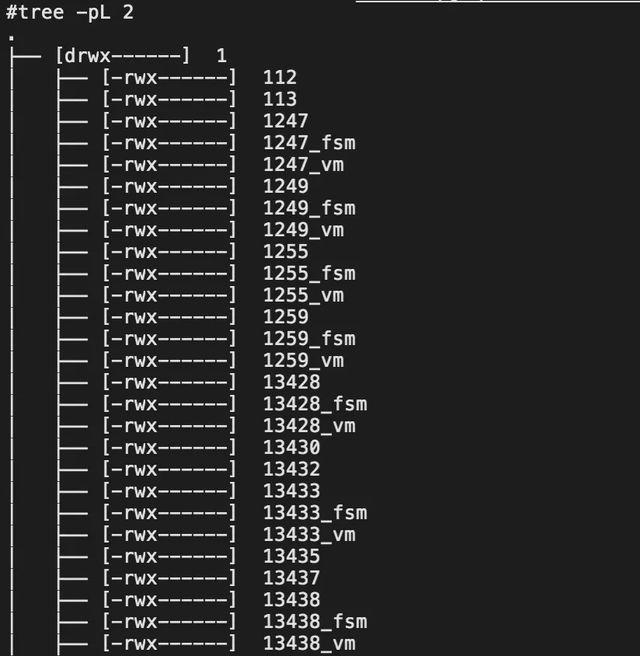
二级子文件如下图所示,存储着某个数据库内的所有关系,包括表、索引、视图等,这里以postgres数据库目录示例。二级子文件分为三大类,第一类是以关系OID命名的主数据文件,第二类是文件名以_fsm结尾的空闲空间映射文件,第三类是文件名以_vm结尾的可见性映射文件。
4 主数据文件
主数据文件存储隶属于对应数据库下的数据库关系文件,包括数据、索引等,客户最重要的业务数据便是存储在主数据文件中。
当关系文件大小低于RELSEG_SIZE × BLCKSZ时,数据库引擎创建名称为pg_class.relfilenode的单文件,反之会切分为名称如
pg_class.relfilenode.segno的多个文件。单个关系文件内部被划分为默认8K固定大小的多个page并存储在磁盘上,8K可以在initdb时通过BLCKSZ参数修改配置。主数据文件写入时,会先将元组数据从行指针数组的底部开始堆叠,直到空间耗尽。
用户通过SQL查询到的单行数据记录对应单个元组(tuple),因为MVCC机制的原因,元组可能是无法查询到旧版本数据,也可能是活跃的新版本数据,旧版本数据会在未来的某个时刻被清理。当查询没有命中索引触发顺序扫描时,数据库引擎顺序扫描page的行指针读取到元组,反之如果命中B树索引,引擎会通过索引文件的元组,通过索引键的TID值读取到元组。
下图是主数据文件的层级结构。
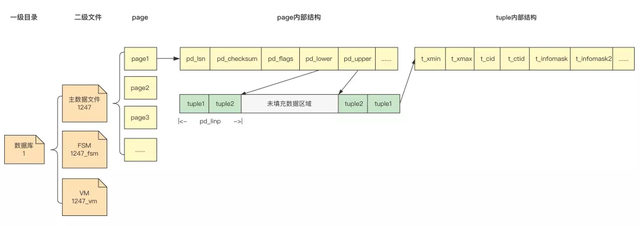
下表格是上图所示page内部结构的元数据信息。
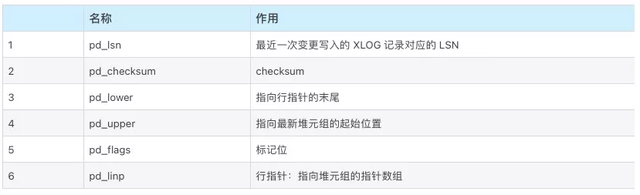
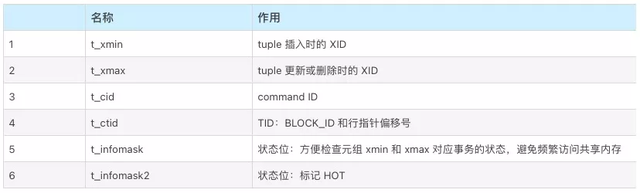
下表格是上图所示tuple内部结构的元数据信息。
5 FSM
FSM是空闲空间映射文件,记录着heap和index的每个page的空闲空间信息,有利于快速定位到有充足空闲空间的page以便存储tuple,如果没有定位到则需要扩展新page。除了Hash Index文件没有FSM文件,其他heap和index都需要FSM文件。
总体上,FSM采用3-4级多叉树的结构组织FSM page,单个FSM page内部采用完全二叉树的结构进行管理,高级别FSM page的叶子节点关联低级别的FSM page,低级别FSM Page的叶子节点存储着heap、index page的可用空间数目,而非叶子结点依次存储叶子节点的最大可用空间数目,每个节点占用1个字节。
6 VM
VM是可见性映射文件,记录着每个heap page的可见性信息,因此index page并没有vm文件。一方面它可以提高vacumn的执行效率,另一方面通过vm文件可以感知到page内的元组是否全部可见,如果全部可见的话,查询引擎查询索引元组直接获取到数据即可,不必再访问数据元组检查可见性,减少了回表次数,极大提升了查询的效率。
VM采用位图的结构存储可见性信息,每个heap page只在vm文件中存储2位,第一位代表元组是否全部可见,第二位代表元组是否全部被冻结。
#define VISIBILITYMAP_ALL_VISIBLE 0x01
#define VISIBILITYMAP_ALL_FROZEN 0x02五 global
1 概述
global目录存储pg_control及数据库集群维度的数据库及其关系,非客户维度的数据,例如pg_database、pg_class等。目录内的文件结构和base是一致的。
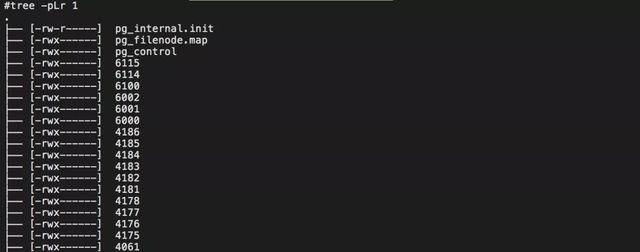
global目录文件结构如下图所示。
2 pg_control
pg_control文件记录数据库集群控制信息,包括initdb初始化、WAL和checkpoint的信息。
六 pg_wal
1 概述
pg_wal是WAL机制中的wal日志存储目录。PG10及之后的高版本改目录名为pg_wal,10之前目录名称是pg_xlog。
2 WAL机制
Write-Ahead-Logging:日志先行机制。数据变更优先写入日志文件,事务失败则变更记录被忽略,事务成功再选择合适时机写入数据文件,数据的刷盘速度慢于日志刷盘速度。当数据库系统崩溃后,引擎会从上一次成功的checkpoint点开始依次重放wal记录,如果LSN>pd_lsn则重放wal记录,反之跳过,确保数据记录恢复到崩溃前的状态。
3 文件结构

4 wal segment
wal段文件存储着数据库行记录明细,每一条记录明细都是服务于数据库恢复操作的,确保前后数据一致。首先针对数据的任意一次修改操作均被记录在wal段文件中,包括insert、update和delete,其次系统的一些管理行为也会被记录在wal段文件中,例如事务提交和vacuum等行为。
wal段文件命名形如00000001 00000001 00000092,文件名共24位,前8位是timeline,中间8位是logid,后8位是logseg,logseg的前6位始终是0,后2位是lsn的前2位。根据wal段文件名的最后2位,wal记录根据对应的LSN分别记录在不同的wal段文件中。

5 .history
.history文件内容包括原.history文件,当前时间线切换记录和切换原因,作用于数据库的时间点恢复行为。当数据库引擎从多个时间线的备份中恢复时,数据库从.history文件中找到从pg_control的start_timeline到指定的recovery_target_timeline间的所有wal段文件进行恢复。
6 archive_status
archive_status是wal段文件的备份目录,包括.ready和.done文件。超出wal_keep_segments数目限制的wal日志会在archive_status目录内被打标,归档操作完成后被进一步移除。
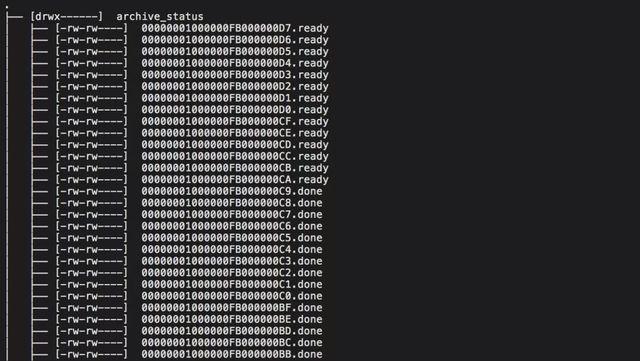
7 .ready
.ready是同名wal段文件在archive_status目录内的标记文件,代表该wal段文件可被归档。wal段文件在数据目录中的存储文件数量是有上限的,一般通过wal_keep_segments参数来约束,因此数据库引擎在wal段文件个数达到上限后会在archive_status目录内增加可移除的wal段文件的标记文件,文件名是原wal段文件名后增加.ready后缀,等待归档工具进行归档。
8 .done
.done是同名wal段文件在archive_status目录内的标记文件,代表该wal段文件已被归档,可以被清理。数据库引擎默认通过archive_command命令对.ready文件进行归档,归档成功与否取决于archive_command命令返回true还是false,当archive_command返回true时,代表与.ready文件同名的wal段文件已被归档,引擎再将该文件的扩展名重命名为.done,等待数据库引擎在下一次的checkpoint时进一步清理原wal段文件。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java