
Spring 声明式事务使用详解
一、揭秘什么是事务管理?
了解声明式事务就要从它的基本概念开始。那么什么是事务呢?
在JavaEE的大型项目开发中,面对规模庞大的数据,需要保证数据的完整性和一致性,因此就有了数据库事务的概念,因此它也是企业级项目应用开发必不可少的技术。
事务可以看做是一组由于逻辑上紧密相关而合并到一个整体(工作单元)的多个数据库操作。这些操作要么全执行,要么全不执行。
同时事务有四个非常关键的属性(ACID):
- 原子性(atomicity):“原子”的本意是“不可再分”,事务的原子性表现为一个事务中涉及到的多个操作在逻辑上缺一不可。事务的原子性要求事务中的所有操作要么都执行,要么都不执行。
- 一致性(consistency):“一致”指的是数据的一致,具体是指:所有数据都处于满足业务规则的一致性状态。一致性原则要求:一个事务中不管涉及到多少个操作,都必须保证事务执行之前数据是正确的,事务执行之后数据仍然是正确的。如果一个事务在执行的过程中,其中某一个或某几个操作失败了,则必须将其他所有操作撤销,将数据恢复到事务执行之前的状态,这就是回滚。
- 隔离性(isolation):在应用程序实际运行过程中,事务往往是并发执行的,所以很有可能有许多事务同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。隔离性原则要求多个事务在并发执行过程中不会互相干扰。
- 持久性(durability):持久性原则要求事务执行完成后,对数据的修改永久的保存下来,不会因各种系统错误或其他意外情况而受到影响。通常情况下,事务对数据的修改应该被写入到持久化存储器中。
所以进行事务控制就应该尽可能的满足这四个属性。既然进行事务控制的目的就是为了能够在数据处理发生意外的时候进行事务回滚,那么常见的错误类型有哪些、对于这种类型的错误又应该如何处理的呢?
二、声明式事务使用详解
相比于编程式事务,声明式事务具有更大的优点,它能够将事务管理代码从业务方法中分离出来,以声明的方式来实现业务管理。
事务管理代码的固定模式作为一种横切关注点,可以通过AOP方法模块化,进而借助Spring AOP框架实现声明式事务管理。
Spring在不同的事务管理API之上定义了一个抽象层,通过配置的方式使其生效,从而让应用程序开发人员不必了解事务管理API的底层实现细节,就可以使用Spring的事务管理机制。
同时Spring既支持编程式事务管理,也支持声明式的事务管理。
那么在Spring中应该如何使用声明式事务呢?
1、事务管理器的主要实现
Spring从不同的事务管理API中抽象出了一整套事务管理机制,让事务管理代码从特定的事务技术中独立出来。这样我们只需通过配置的方式进行事务管理,而不必了解其底层是如何实现的。这也是使用声明式事务的一大好处。
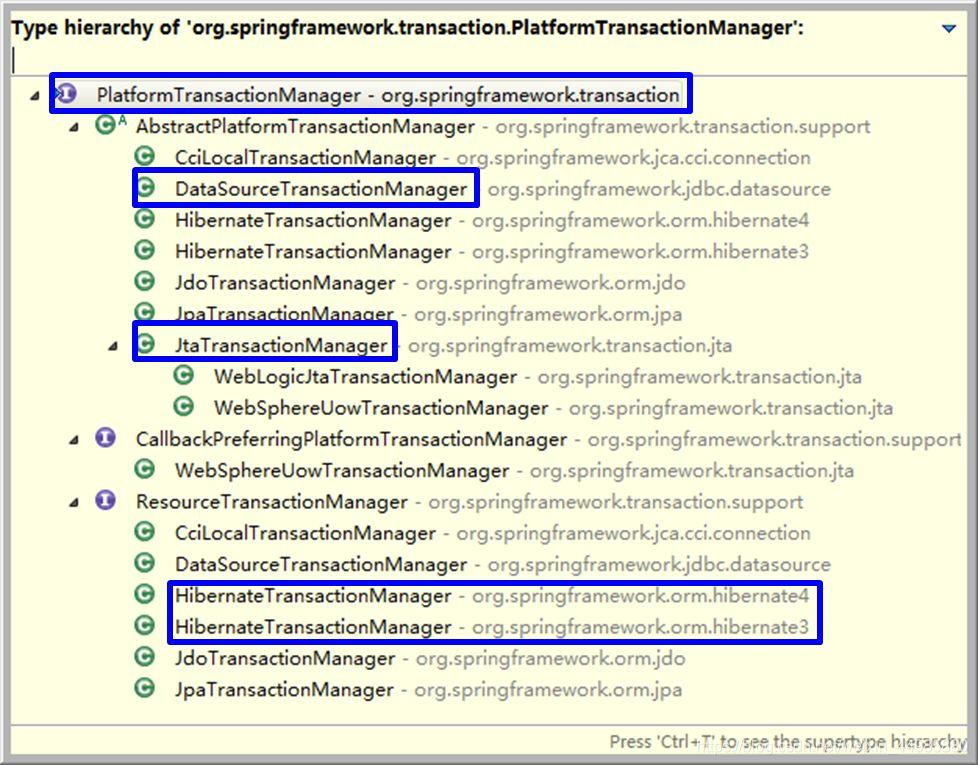
Spring的核心事务管理抽象是PlatformTransactionManager。它为事务管理封装了一组独立于技术的方法。无论使用Spring的哪种事务管理策略(编程式或声明式),事务管理器都是必须的。
事务管理器可以以普通的bean的形式声明在Spring IOC容器中。在Spring中我们常用的三种事务管理器是:
- DataSourceTransactionManager:在应用程序中只需要处理一个数据源,而且通过JDBC存取。
- JtaTransactionManager:在JavaEE应用服务器上用JTA(Java Transaction API)进行事务管理
- HibernateTransactionManager:用Hibernate框架存取数据库
它们都是PlatformTransactionManager的子类,继承关系图如下:
现在我们已经基本了解了声明式事务的实现原理和机制,百读不如一练,接下来我们就实际讲解一下如何配置使用Spring的声明式事务。
2、基于注解的声明式事务配置
我以DataSourceTransactionManager类为例来给大家讲一下声明式事务的实现过程,小伙伴们可以操作实现一下,有问题的话记得留言我一起交流。
(1)、配置数据源
既然是对数据库的操作,那么首先第一步一定就是配置数据源的,关于数据源的配置相信小伙伴们应该都不陌生了,还不太了解的小伙伴们可以看我的上一篇关于Spring的文章。《Spring JDBC持久化层框架“全家桶”教程丨【绽放吧!数据库】》
配置数据源我以引入外部数据配置文件为例,所以我这里需要使用<context></context>标签引入外部文件,并使用“${}”的方式为属性赋值:
代码如下:
<!-- 连接外部配置文件 -->
<context:property-placeholder location="classpath:jdbcconfig.properties"/>
<!-- 连接数据库 -->
<bean id="pooldataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${jdbc.user}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="jdbcUrl" value="${jdbc.jdbcurl}"></property>
<property name="driverClass" value="${jdbc.driverclass}"></property>
</bean>(2)、建立JdbcTemplate
既然是操作数据库,而且是在spring框架中,那么对于Spring中数据库操作框架的使用也一定是必不可少的,关于jdbcTemplate这个框架技术点的详细使用我也在上一篇文章中和大家讲解了,小伙伴们可以学起来了!
在这里我们直接在ioc的bean中声明jdbcTemplate类,并设置数据源为第一步的数据源。
代码如下:
<!-- 建立jdbcTemplate -->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="pooldataSource"></property>
</bean>(3)、进行事务控制
现在数据源也配置好了,数据库操作也整完了,那么接下来就是今天的主题事务控制了。
我们知道事务控制本身就是基于面向切面编程来实现的,所以配置事务控制时就需要导入相应的jar包:我把所需的jar包给大家罗列了出来:
- spring-aop-4.0.0.RELEASE.jar
- com.springsource.net.sf.cglib-2.2.0.jar
- com.springsource.org.aopalliance-1.0.0.jar
- com.springsource.org.aspectj.weaver-1.6.8.RELEASE.jar
在这里插入一个补充,也可以说是一道面试题:说一说使用事务管理器的优点?
使用事务控制能够节省平时进行事务控制是书写的代码量,进行事务控制时,若一个事务的执行过程中发生差错,则其他操作不会修改,保持事务的原子性。
我们在这里使用DataSourceTransactionManager类来配置事务管理器。
具体方法是在ioc中的bean标签中声明该类的实例,设置好id,并给DataSource属性赋上数据源,
代码如下:
<bean id="dataSourceTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- 2、控制住数据源 -->
<property name="dataSource" ref="pooldataSource"></property>
</bean>这样就已经配置好事务管理器了,是不是以为这样就完了,并没有噢!接下来也是最关键的一步!就是将事务管理器开启,因为不开启怎么使用呢?
(4)、开启基于注解的事务控制
开启基于注解的事务控制的主要作用就是对方法和类增加相应的注解,从而实现自动的包扫描。开启基于注解的事务控制需要引入tx表达式,使用其中的annotation-driven标签,即可对执行的事务管理器开启事务控制。
代码如下:
<!-- 3、开启基于注解的事务控制 -->
<tx:annotation-driven transaction-manager="dataSourceTransactionManager"/>
<!-- 4、给方法增加事务控制,添加相应的注解-->接下来的就是为方法添加相应的注解,增加事务控制了。
首先对数据库操作的类一般都属于业务逻辑层,所以我们要为该类添加@service注解,从而实现包扫描,之后为需要进行事务控制的方法添加事务控制专有的注解@Transactional来告诉Spring该方法是事务方法。当该方法中的操作发生错误的时候,该方法内其他对数据库的操作也都会回滚。
代码如下:
@Service
public class BookService {
@Autowired
BookDao bookDao;
/**
* 顾客买书
* */
// 开启基于注解的事务控制
@Transactional
public void buyBook(String username,String isbn) {
bookDao.updateStockFromBookStock(isbn);
int price = bookDao.getPriceFromBook(isbn);
bookDao.updateBalanceFromAccount(username, price);
System.out.println("【" +username + "】买书成功!");
}
}3、基于XML的声明式事务配置
上面我们讲解了使用注解如何配置声明式事务,那么配置声明式事务还有另一种方法,就是在XML文件中配置,而且他们在声明数据源的时候都是一样的,在这里我就不说了,我只说一下在配置完数据源之后,如何通过XML声明事务管理器和事务方法。
(1)、配置事务切面
Spring中有提供事务管理器(事务切面),所以首先我们需要配置这个事务切面。
<aop:config>
<aop:pointcut expression="execution(* com.spring.service.*.*(..))" id="txpoint"/>
<!-- 事务建议;advice-ref:指向事务管理器的配置 -->
<aop:advisor advice-ref="myAdvice" pointcut-ref="txpoint"/>
</aop:config>(2)、配置事务管理器
配置事务管理器使用tx:advice标签,其中的属性transaction-manager="transactionManager" 指定是配置哪个事务管理器,指定好之后我们就需要在该标签中配置出事务方法,
<!-- 配置事务管理器
transaction-manager="transactionManager" 指定是配置哪个事务管理器
-->
<tx:advice id="myAdvice" transaction-manager="dataSourceTransactionManager">
</tx:advice>(3)、指定事务方法
我们需要在tx:advice标签中增加tx:method标签告诉Spring哪些方法是事务方法(事务切面将按照我们的切入点表达式去切事务方法)。同时事务可以使用的各种参数可以在tx:method中声明,
代码如下:
<!-- 配置事务管理器
transaction-manager="transactionManager" 指定是配置哪个事务管理器
-->
<tx:advice id="myAdvice" transaction-manager="dataSourceTransactionManager">
<!-- 事务属性 -->
<tx:attributes>
<!-- 指明哪些方法是事务方法,
切入点表达式只是说,事务管理器要切入这些方法, -->
<!-- 指定所有的方法都是事务方法 -->
<tx:method name="*"/>
<!-- 仅仅指定一个方法是事务方法,并且指定事务的属性 -->
<tx:method name="buyBook" propagation="REQUIRED" timeout="-1"/>
<!-- 表示所有以get开头的方法 -->
<tx:method name="get*" read-only="true"/>
</tx:attributes>
</tx:advice>至此声明式事务的初步使用才算完成,那么到底什么时候使用基于注解的事务管理器,什么时候使用基于XML的呢,
注意:正确的应该是,基于注解的和基于注解的都用,重要的事务使用注解,不重要的事务使用配置。
你以为到这里就结束了嘛?但是这仅仅只是一个开始,因为事务的控制一定是伴随着多种情况一起执行的。
三、事务的传播行为
当一个事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
事务的传播行为可以在@Transactional注解的propagation属性中指定。Spring定义了7种类传播行为。
他们所对应的功能分别如下表所示:

这里我再对最常使用的两个传播行为说一下:
1)REQUIRED:当前事务和之前的大事务公用一个事务
当事务使用REQUIRED的时候,事务的属性都是集成于大事务的,所以对方法施加的属性不会单独生效如超时设置timeout。
当事务使用REQUIRES_NEW的时候,事务的属性是可以调整的,
2)REQUIRES_NEW:当前事务总是使用一个新的事务,如果已经有事务,事务将会被挂起,当前事务提交运行完之后会继续运行被挂起的事务
原理:REQUIRED,是将之前事务的connection传递给这个方法使用。
REQUIRES_NEW,是这个方法直接使用新的connection
四、事务的隔离级别
1、数据库事务并发问题
我们在对数据库中的数据进行操作的时候,往往不是只有一个人在操作的,也就是说可能会有事务的并发执行,那么既然存在并发执行,在这其中就一定会存在并发处理的问题。
那么都会有哪些常见的事务并发问题呢?我们以两个事务Transaction01和Transaction02并发执行为例来介绍一下:
(1)、脏读
所谓脏读就是读取到了一个脏的数据,通俗一点理解为就是读取到的数据无效。如下面的操作实例:
- Transaction01将某条记录的AGE值从20修改为30。
- Transaction02读取了Transaction01更新后的值:30。
- Transaction01回滚,AGE值恢复到了20。
- Transaction02读取到的30就是一个无效的值。
这时Transaction02的事务就发生了脏读,
(2)、不可重复读
从里面意思上我们应该也可以理解,就是同一个事务在对数据进行重复读取的时候,两次读取到的数据不一致。
看下面的案例:
- Transaction01读取了AGE值为20。
- Transaction02将AGE值修改为30。
- Transaction01再次读取AGE值为30,和第一次读取不一致。
这时Transaction01两次读取到的数据不一致,这就到之后Transaction01处理事务时会出现不知道使用哪个数据的情况,这就是不可重复读。
(3)、幻读
听到这个名字是不是觉得很神奇,怎么还会有幻读呢?其实幻读的意思还是两次读取到的数据不一致,
看下面的案例:
- Transaction01读取了STUDENT表中的一部分数据。
- Transaction02向STUDENT表中插入了新的行。
- Transaction01读取了STUDENT表时,多出了一些行。
在这里Transaction01在第二次读取数据表时,发现数据表中的数据和之前的相比多了,这就是发生了幻读。
2、事务的隔离级别分析
那么对于我们上面提到的那三种并发问题到底应该如何解决呢?这里就用到了事务的隔离级别,因为这些问题都是由于并发执行而引起的,因此数据库系统必须具备隔离并发运行各个事务的能力,使它们之间不会相互影响,避免各种并发问题。
一个事务与其他事务隔离的程度就称为隔离级别。SQL标准中规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
常见的隔离级别有以下四种:
- ①读未提交:READ UNCOMMITTED
允许Transaction01读取Transaction02未提交的修改。 - ②读已提交:READ COMMITTED
要求Transaction01只能读取Transaction02已提交的修改。 - ③可重复读:REPEATABLE READ
确保Transaction01可以多次从一个字段中读取到相同的值,即Transaction01执行期间禁止其它事务对这个字段进行更新。 - ④串行化:SERIALIZABLE
确保Transaction01可以多次从一个表中读取到相同的行,在Transaction01执行期间,禁止其它事务对这个表进行添加、更新、删除操作。可以避免任何并发问题,但性能十分低下。
但是这些个隔离级别并不是都能解决上面所有的并发问题的,他们解决并发问题的能力如下:

同时不同的数据库对不同隔离级别也是有不同的支持程度,就拿MySQL和Oracle为例:

3、为方法指定隔离级别
我们上面讲了事务并发的问题,也提到了应该使用隔离级别来解决,那么接下来就是如何在事务方法上增加隔离级别了。在这里有两种方法。
(1)、基于注解指定隔离级别
基于注解指定事务隔离级别可以在@Transactional注解声明式地管理事务时,在@Transactional的isolation属性中设置隔离级别。这样该事务方法就有了该隔离级别。
@Transactional(readOnly=true,isolation=Isolation.READ_UNCOMMITTED)
public int getPrice(String isbn) {
return bookDao.getPriceFromBook(isbn);
}(2)。基于XML指定隔离级别
这种方法是在如果不使用注解的情况下,可以在XML配置文件中为方法声明隔离级别,可以在Spring 2.x事务通知中,在<tx:method>元素中的isolation属性指定隔离级别。如下:
<tx:advice id="myAdvice" transaction-manager="dataSourceTransactionManager">
<!-- 事务属性 -->
<tx:attributes>
<tx:method name="buyBook" propagation="REQUIRED" isolation="READ_COMMITTED"/>
</tx:attributes>
</tx:advice>五、触发事务回滚的异常
我们上面只是说在发生错误时进行回滚,那么是否可以指定只有在发生特定错误的情况下才能发生回滚呢?当然是可以的。
1、默认回滚异常
在默认情况下:
系统捕获到RuntimeException或Error时回滚,而捕获到编译时异常不回滚。
但是现在我们可以通过某一个属性来指定只有在发生某一个或某多个错误时才回滚。
2、设置特定异常下回滚
设置特定异常下回滚同样是可以在注解中或者在XML中声明,
(1)、通过注解设置回滚
通过注解设置回滚的话,同样是在@Transactional注解下,有两个属性:
- rollbackFor属性:指定遇到时必须进行回滚的异常类型,可以为多个
- noRollbackFor属性:指定遇到时不回滚的异常类型,可以为多个
当设置多个的时候使用大括号{}扩住,使用逗号隔开。
如下:
@Transactional(propagation=Propagation.REQUIRED,rollbackFor={IOException.class,SQLException.class},
noRollbackFor={ArithmeticException.class,NullPointerException.class})
public void updatePrice(String isbn,int price) {
bookDao.updatePrice(isbn, price);
}(2)、通过XML设置回滚
在Spring 2.x事务通知中,可以在<tx:method>元素中指定回滚规则。如果有不止一种异常则用逗号分隔。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java