
Flink SQL 优化实战。
一、背景

目前,京东搜索推荐的数据处理流程如上图所示。可以看到实时和离线是分开的,离线数据处理大部分用的是 Hive / Spark,实时数据处理则大部分用 Flink / Storm。
这就造成了以下现象:在一个业务引擎里,用户需要维护两套环境、两套代码,许多共性不能复用,数据的质量和一致性很难得到保障。且因为流批底层数据模型不一致,导致需要做大量的拼凑逻辑;甚至为了数据一致性,需要做大量的同比、环比、二次加工等数据对比,效率极差,并且非常容易出错。
而支持批流一体的 Flink SQL 可以很大程度上解决这个痛点,因此我们决定引入 Flink 来解决这种问题。
在大多数作业,特别是 Flink 作业中,执行效率的优化一直是 Flink 任务优化的关键,在京东每天数据增量 PB 级情况下,作业的优化显得尤为重要。
写过一些 SQL 作业的同学肯定都知道,对于 Flink SQL 作业,在一些情况下会造成同一个 UDF 被反复调用的情况,这对一些消耗资源的任务非常不友好;此外,影响执行效率大致可以从 shuffle、join、failover 策略等方面考虑;另外,Flink 任务调试的过程也非常复杂,对于一些线上机器隔离的公司来说尤甚。
为此,我们实现了内嵌式的 Derby 来作为 Hive 的元数据存储数据库 (allowEmbedded);在任务恢复方面,批式作业没有 checkpoint 机制来实现failover,但是 Flink 特有的 region 策略可以使批式作业快速恢复;此外,本文还介绍了对象重用等相关优化措施。
二、 Flink SQL 的优化
1. UDF 重用
在 Flink SQL 任务里会出现以下这种情况:如果相同的 UDF 既出现在 LogicalProject 中,又出现在 Where 条件中,那么 UDF 会进行多次调用 (见https://issues.apache.org/jira/browse/FLINK-20887)。但是如果该 UDF 非常耗 CPU 或者内存,这种多余的计算会非常影响性能,为此我们希望能把 UDF 的结果缓存起来下次直接使用。在设计的时候需要考虑:(非常重要:请一定保证 LogicalProject 和 where 条件的 subtask chain 到一起)
- 一个 taskmanager 里面可能会有多个 subtask,所以这个 cache 要么是 thread (THREAD LOCAL) 级别要么是 tm 级别;
- 为了防止出现一些情况导致清理 cache 的逻辑走不到,一定要在 close 方法里将 cache 清掉;
- 为了防止内存无限增大,选取的 cache 最好可以主动控制 size;至于 “超时时间”,建议可以配置一下,但是最好不要小于 UDF 先后调用的时间;
- 上文有提到过,一个 tm 里面可能会有多个 subtask,相当于 tm 里面是个多线程的环境。首先我们的 cache 需要是线程安全的,然后可根据业务判断需不需要锁。
根据以上考虑,我们用 guava cache 将 UDF 的结果缓存起来,之后调用的时候直接去cache 里面拿数据,最大可能降低任务的消耗。下面是一个简单的使用(同时设置了最大使用 size、超时时间,但是没有写锁):
public class RandomFunction extends ScalarFunction {
private static Cache<String, Integer> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.expireAfterWrite(3, TimeUnit.SECONDS)
.build();
public int eval(String pvid) {
profileLog.error("RandomFunction invoked:" + atomicInteger.incrementAndGet());
Integer result = cache.getIfPresent(pvid);
if (null == result) {
int tmp = (int)(Math.random() * 1000);
cache.put("pvid", tmp);
return tmp;
}
return result;
}
@Override
public void close() throws Exception {
super.close();
cache.cleanUp();
}
}2. 单元测试
大家可能会好奇为什么会把单元测试也放到优化里面,大家都知道 Flink 任务调试过程非常复杂,对于一些线上机器隔离的公司来说尤甚。京东的本地环境是没有办法访问任务服务器的,因此在初始阶段调试任务,我们耗费了很多时间用来上传 jar 包、查看日志等行为。
为了降低任务的调试时间、增加代码开发人员的开发效率,实现了内嵌式的 Derby 来作为 Hive 的元数据存储数据库 (allowEmbedded),这算是一种优化开发时间的方法。具体思路如下:
首先创建 Hive Conf:
public static HiveConf createHiveConf() {
ClassLoader classLoader = new HiveOperatorTest().getClass().getClassLoader();
HiveConf.setHiveSiteLocation(classLoader.getResource(HIVE_SITE_XML));
try {
TEMPORARY_FOLDER.create();
String warehouseDir = TEMPORARY_FOLDER.newFolder().getAbsolutePath() + "/metastore_db";
String warehouseUri = String.format(HIVE_WAREHOUSE_URI_FORMAT, warehouseDir);
HiveConf hiveConf = new HiveConf();
hiveConf.setVar(
HiveConf.ConfVars.METASTOREWAREHOUSE,
TEMPORARY_FOLDER.newFolder("hive_warehouse").getAbsolutePath());
hiveConf.setVar(HiveConf.ConfVars.METASTORECONNECTURLKEY, warehouseUri);
hiveConf.set("datanucleus.connectionPoolingType", "None");
hiveConf.set("hive.metastore.schema.verification", "false");
hiveConf.set("datanucleus.schema.autoCreateTables", "true");
return hiveConf;
} catch (IOException e) {
throw new CatalogException("Failed to create test HiveConf to HiveCatalog.", e);
}
}接下来创建 Hive Catalog:(利用反射的方式调用 embedded 的接口)
public static void createCatalog() throws Exception{
Class clazz = HiveCatalog.class;
Constructor c1 = clazz.getDeclaredConstructor(new Class[]{String.class, String.class, HiveConf.class, String.class, boolean.class});
c1.setAccessible(true);
hiveCatalog = (HiveCatalog)c1.newInstance(new Object[]{"test-catalog", null, createHiveConf(), "2.3.4", true});
hiveCatalog.open();
}创建 tableEnvironment:(同官网)
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
TableConfig tableConfig = tableEnv.getConfig();
Configuration configuration = new Configuration();
configuration.setInteger("table.exec.resource.default-parallelism", 1);
tableEnv.registerCatalog(hiveCatalog.getName(), hiveCatalog);
tableEnv.useCatalog(hiveCatalog.getName());最后关闭 Hive Catalog:
public static void closeCatalog() {
if (hiveCatalog != null) {
hiveCatalog.close();
}
}此外,对于单元测试,构建合适的数据集也是一个非常大的功能,我们实现了 CollectionTableFactory,允许自己构建合适的数据集,使用方法如下:
CollectionTableFactory.reset();
CollectionTableFactory.initData(Arrays.asList(Row.of("this is a test"), Row.of("zhangying480"), Row.of("just for test"), Row.of("a test case")));
StringBuilder sbFilesSource = new StringBuilder();
sbFilesSource.append("CREATE temporary TABLE db1.`search_realtime_table_dump_p13`(" + " `pvid` string) with ('connector.type'='COLLECTION','is-bounded' = 'true')");
tableEnv.executeSql(sbFilesSource.toString());3. join 方式的选择
传统的离线 Batch SQL (面向有界数据集的 SQL) 有三种基础的实现方式,分别是 Nested-loop Join、Sort-Merge Join 和 Hash Join。
| 效率 | 空间 | 备注 | |
| Nested-loop Join | 差 | 占用大 | |
| Sort-Merge Join | 有sort merge开销 | 占用小 | 有序数据集的一种优化措施 |
| Hash Join | 高 | 占用大 | 适合大小表 |
- Nested-loop Join 最为简单直接,将两个数据集加载到内存,并用内嵌遍历的方式来逐个比较两个数据集内的元素是否符合 Join 条件。Nested-loop Join 的时间效率以及空间效率都是最低的,可以使用:table.exec.disabled-operators:NestedLoopJoin 来禁用。以下两张图片是禁用前和禁用后的效果 (如果你的禁用没有生效,先看一下是不是 Equi-Join):
- Sort-Merge Join 分为 Sort 和 Merge 两个阶段:首先将两个数据集进行分别排序,然后再对两个有序数据集分别进行遍历和匹配,类似于归并排序的合并。(Sort-Merge Join 要求对两个数据集进行排序,但是如果两个输入是有序的数据集,则可以作为一种优化方案)。
- Hash Join 同样分为两个阶段:首先将一个数据集转换为 Hash Table,然后遍历另外一个数据集元素并与 Hash Table 内的元素进行匹配。第一阶段和第一个数据集分别称为 build 阶段和 build table;第二个阶段和第二个数据集分别称为 probe 阶段和 probe table。Hash Join 效率较高但是对空间要求较大,通常是作为 Join 其中一个表为适合放入内存的小表的情况下的优化方案 (并不是不允许溢写磁盘)。
注意:Sort-Merge Join 和 Hash Join 只适用于 Equi-Join ( Join 条件均使用等于作为比较算子)。
Flink 在 join 之上又做了一些细分,具体包括:
| 特点 | 使用 | |
| Repartition-Repartition strategy | 对数据集分别进行分区和shuffle,如果数据集大的时候效率极差 | 两个数据集相差不大 |
| Broadcast-Forward strategy | 将小表的数据全部发送到大表数据的机器上 | 两个数据集有较大的差距 |
- Repartition-Repartition strategy:Join 的两个数据集分别对它们的 key 使用相同的分区函数进行分区,并经过网络发送数据;
- Broadcast-Forward strategy:大的数据集不做处理,另一个比较小的数据集全部复制到集群中一部分数据的机器上。
众所周知,batch 的 shuffle 非常耗时间。
- 如果两个数据集有较大差距,建议采用 Broadcast-Forward strategy;
- 如果两个数据集差不多,建议采用 Repartition-Repartition strategy。
可以通过:table.optimizer.join.broadcast-threshold 来设置采用 broadcast 的 table 大小,如果设置为 “-1”,表示禁用 broadcast。
下图为禁用前后的效果:


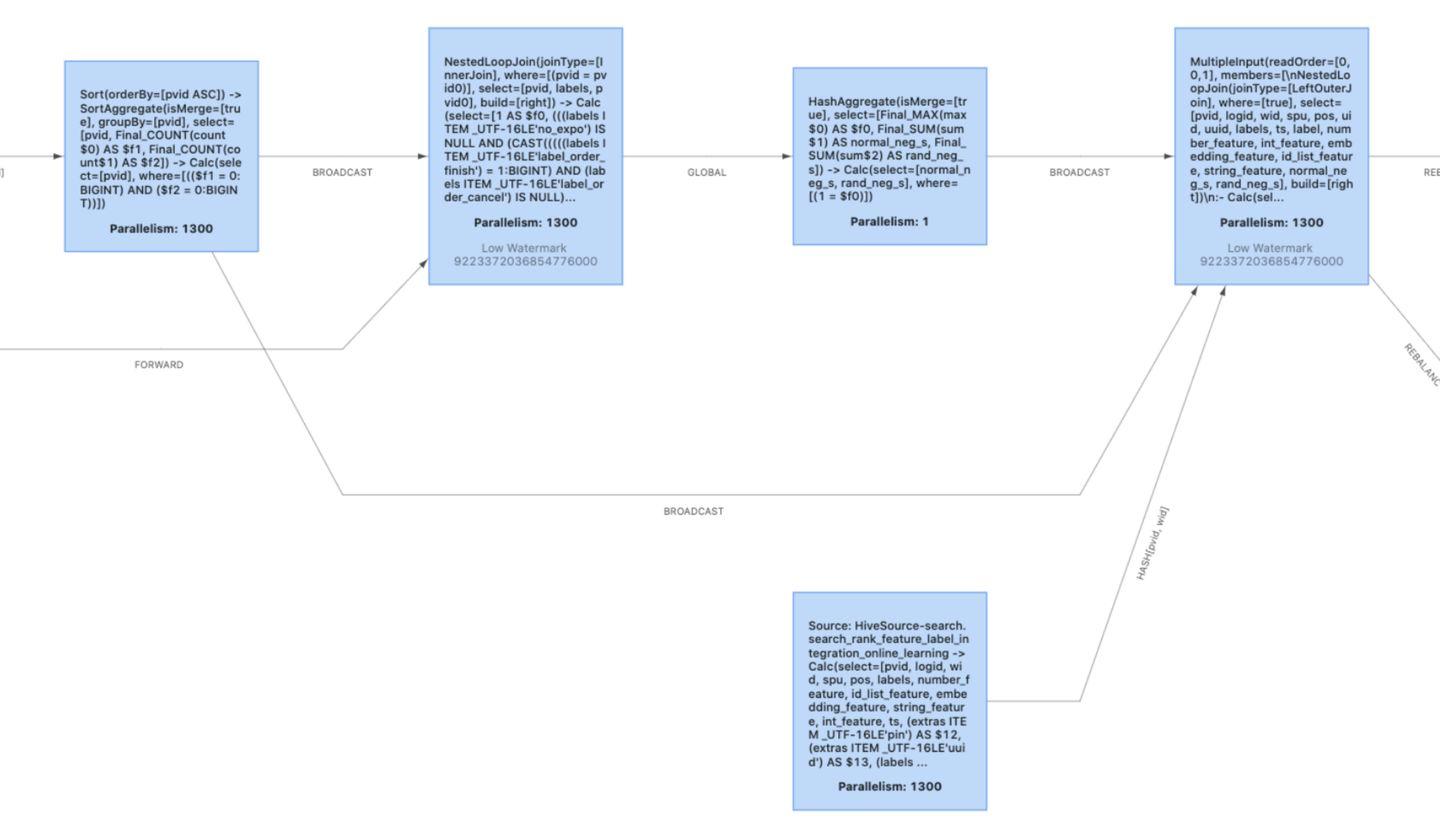
4. multiple input
在 Flink SQL 任务里,降低 shuffle 可以有效的提高 SQL 任务的吞吐量,在实际的业务场景中经常遇到这样的情况:上游产出的数据已经满足了数据分布要求 (如连续多个 join 算子,其中 key 是相同的),此时 Flink 的 forward shuffle 是冗余的 shuffle,我们希望将这些算子 chain 到一起。Flink 1.12 引入了 mutiple input 的特性,可以消除大部分没必要的 forward shuffle,把 source 的算子 chain 到一起。
table.optimizer.multiple-input-enabled:true
下图为开了 multiple input 和没有开的拓扑图 ( operator chain 功能已经打开):

5. 对象重用
上下游 operator 之间会经过序列化 / 反序列化 / 复制阶段来进行数据传输,这种行为非常影响 Flink SQL 程序的性能,可以通过启用对象重用来提高性能。但是这在 DataStream 里面非常危险,因为可能会发生以下情况:在下一个算子中修改对象意外影响了上面算子的对象。
但是 Flink 的 Table / SQL API 中是非常安全的,可以通过如下方式来启用:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableObjectReuse();或者是通过设置:pipeline-object-reuse:true
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java