
比开源快30倍的自研 SQL Parser 设计与实践
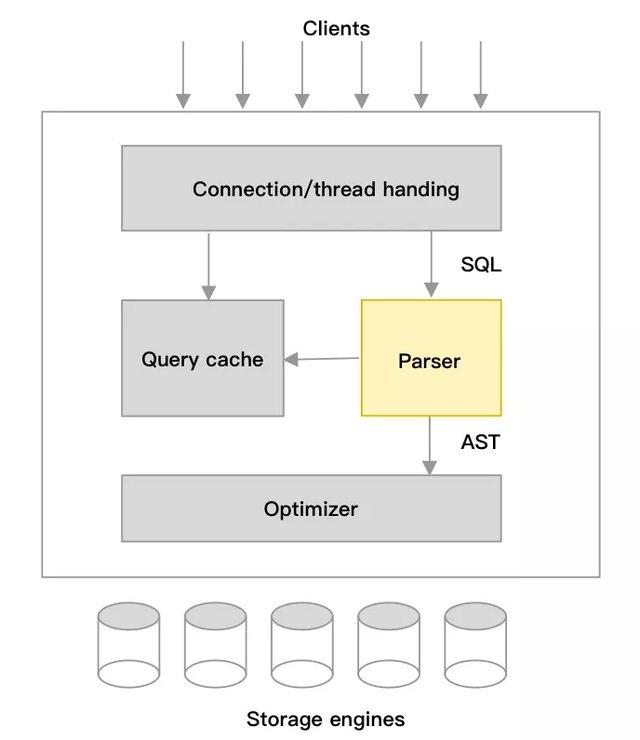
SQL(Structured Query Language)作为一种领域语言(编程语言),最早用于关系型数据库,方便管理结构化数据;SQL由多种不同的类型的语言组成,包括数据定义语言,数据控制语言、数据操作语言;各数据库产品都有不同的声明和实现;用户可以很方便的使用SQL操作数据,数据库系统中的词法语法分析器负责分析和理解SQL文本的含义,包括词法分析、语法分析、语义分析3部分。经过词法语法分析器生成AST(Abstract Syntax Tree),会被优化器处理生成生成执行计划,再由执行引擎执行,下图以MySQL架构为例展示词法语法分析器所处的位置。
本文通过介绍词法语法分析器技术和业界的做法,以及过去使用自动生成的词法语法分析器遇到的问题,分享自研SQL Parser的设计与实践,以及其带来的性能和功能的提升。
一 业界产品如何开发SQL Parser?
按照解析器代码开发方式,可分为以下两种:
1 自动生成
为方便开发词法、语法分析的过程,业界有许多词法、语法分析工具,例如:Flex、Lex、Bison工具常用于生成以C、C++作为目标语言的词法、语法代码;如果以Java作为目标语言,可以使用比较流行的ANTLR和JavaCC等工具,ANTLR、JavaCC工具都以用户编写的词法语法规则文件作为输入,其中语法文件需要满足EBNF(extended Backus–Naur form)[1]语法规则, 这2个工具使用LL(k) (Left-to-right, Leftmost derivation)[2] 算法“自顶向下[3]”解析SQL文本并构建SQL AST, Presto,Spark、Hive等数据库和大数据系统多采用该方式生成。生成的代码包含词法和语法解析部分,语义分析还需要结合Meta数据,各数据库内核自己处理;更多自动生成工具的功能和算法对比[4]在参考文献中。
2 手工编写
与自动生成工具不同,InfluxDB、H2、Clickhouse等流行的数据库的SQL Parser组件均是手工编写而成。
优点:
- 代码逻辑清晰,方便开发人员调试和排错;
- 性能更好:有更多代码优化的空间交给开发人员,可以使用更优秀的算法和数据结构提升性能;
- 自主可控:无licence约束,可读性和可维护性更高;
- 不需要额外依赖第三方词法语法代码生成工具。
不足:
- 对开发人员的技术要求较高,需了解编译原理技术;
- 开发工作量较大,实现MySQL常用语法的各类分支,需要投入很多时间和精力;
- 需要长时间、大规模测试才会趋于稳定。
二 问题与挑战
1 复杂查询的性能问题
在实时分析型数据库的实际生产环境中,经常需要处理数以千行的复杂查询请求或者深层嵌套的查询请求,自动生成的解析器,由于状态机管理复杂,线程堆栈太深,导致个别查询请求在词法语法解析阶段性能下降严重。
2 大批量写入吞吐问题
分析型数据库要稳定处理大批量、高并发写入的场景,要求SQL Parser组件有很好的性能和稳定性,我们尝试使用过ANTLR,JavaCC等工具生成SQL 的词法语法解析器,大批量写入时,values子句在解析过程会产生太多AST临时对象,导致垃圾回收耗时的问题。
3 Query Rewriting的灵活性问题
需要快速方便的遍历AST树,找到符合某种规则的叶子节点,修改改节点,自动生成的解析器并不能很灵活的支持。
自动生成的代码可读性差,排查问题成本高,复杂查询场景下,性能不足,影响系统稳定性和版本迭代速度;在设计之初,我们放弃了自动生成的技术方案,完全手工编写词法语法解析器。
三 自研词法语法分析器的技术要点
自动生成工具主要处理生成下图中左侧的 SQL Parser Core和 SQL Tree Nodes的部分,右侧featrues的部分需要开发同学处理,当右侧功能(例如:SQL rewriting)对左侧有的Tree nodes的更改功能有更多的需求时,想修改自动生成的代码,则无从下手。
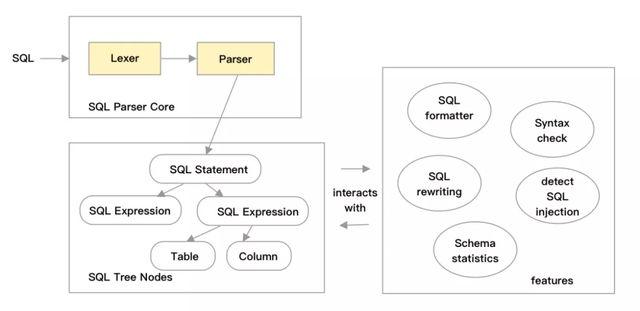
自动生成工具是面向生成通用语法解析器而设计的,针对SQL这一特定领域语言,有特定的优化技术提升稳定性和性能,从设计之初,我们选择LL(k)作为语法分析的算法,其自顶向下的特性,在手工编写分析器时,逻辑清晰,代码易读,方便开发和维护,LL(k)的“左递归”问题,可通过手工判定循环编程的方式避免。
1 词法和语法分析
词法分析中,Lexer持续读取连续SQL 文本,将具有某特征的一段连续文本标识为Token,并标识Token的类别,比如赋值语句 x = 30,经过词法分析后x, = , 30 分别被标识为ID、等号操作符、数值常量;尤其在识别标识符(变量,表名,列名等)和保留字(TABLE,FROM,SELECT等)需要对字符串进行反复对比。自动生成工具在这一阶段使用DFA(Deterministic Finite Automaton)和预先定义的词法文件,确定每个Token的值和类型,手工编写解析器不需要额外维护一个状态机,使用分支预测,减少计算量和调用堆栈的深度。
语法分析器会使用词法分析中的Token作为输入,以SQL语法描述作为规则,自顶向下,依次将非叶子节点展开,构建语法树,整个过程就像是走迷宫,只有一个正确入口和出口,走完迷宫后,会生成一个正确的AST。
快速Token比较
selECT c1 From T1;由于大部分数据库系统对大小写不敏感,上述query中 selECT 和 From 会被识别为保留字,c1和T1会被识别为标识符。识别2者的类型不同,字符串匹配操作是必不可少的,通常将字符统一转为大写或者小写,再比较字面值,是一个可行的方案。首先把数据库保留字按照Map< String, Token >初始化在内存里,key是保留字的大写字符串,value是Token类型;其中key在作大写转化时,可使用ASCII值+32的方法取代toUpperCase()方法,在不影响正确性的前提下,获得数倍性能提升。
快速数值分析
在解析常量值时,通常的做法是读取SQL中的字符串,把字符串作为参数,调用Java自带的Integer.parseInt() / Float.parseFloat() / Long.parseLong(),可以直接在原文本上边读取边计算数值,该过程只使用基础类型,避免构造字符串,可以节省内存,又提升了解析速度,该优化对大批量写入数值的场景优化非常明显。
避免回溯[5]
SQL语法解析过程中,通常只需要预读一个Token,就可以决定如何构建语法节点的关系,或者构建哪种语法节点,有些语法分支较多,需要预读2个及以上的Token才可以做出判断,预读多个Token可以降低回溯带来的性能消耗,极少情况下,2个以上的Token预读都也没有匹配到正确的语法分支,需要撤销预读,走其他分支;为了提高撤销的速度,可以在预读前保存Token位点,撤销时,可以快速回到保存点。
在insert into values语句中,出现常量字面值的概率比出现其他的token要高,通过分支预测可以减少判断逻辑,避免回溯,提升性能。
表达式替换
Query rewriting[6]技术基于“关系代数”修改AST,保证正确性的前提下,使新的AST在具备更好的执行性能,例如:A,B两张表的大小相差悬殊,而且错误的Join顺序对数据库系统不友好,通过更改A,B表的Join顺序可以获得更高的执行性能。使用工具生成的解析器,通常不允许直接更改AST的节点,每次更改AST某个节点都需要重新构建整个AST,性能并不好。自研的Parser中,每个AST节点类实现都replace接口,只需要修改AST中的子树就可以达到改写的目的。
public interface Replaceable {
boolean replace(Node expr, Node target);
}
public class BetweenNode implements Replaceable {
public Node beginExpr;
public Node endExpr;
@Override
public int hashCode(){...}
@Override
public boolean equals(Object obj) {...}
@Override
public boolean replace(SQLExpr expr, SQLExpr target) {
if (expr == beginExpr) {
setBeginExpr(target);
return true;
}
if (expr == endExpr) {
setEndExpr(target);
return true;
}
return false;
}
}其他优化
- 支持AST Clone:如果保持原AST结构不变,克隆出一个新的AST,在新的AST修改节点结构,比如:增加Hint,删减where条件,增加limit 限制等。
- 维护AST 父子关系:自动生成的解析器维护了父到子节点的关系,是单向的引用关系。手写代码可以增加子节点对父节点的引用,构建AST节点的双向引用关系,实现节点的快速“回跳”,使得AST的遍历效率更高。
public abstract class Node {
public abstract List< Node> getChildren()
}
public class BetweenNode extends Node {
public Node beginExpr;
public Node endExpr;
@Override
public List< Node> getChildren() {
return Arrays.< Node>asList(beginExpr, this.endExpr);
}
@Override
public BetweenNode clone() {
BetweenNode x = new BetweenNode();
if (beginExpr != null) {
x.setBeginExpr(beginExpr.clone());
}
if (endExpr != null) {
x.setEndExpr(endExpr.clone());
}
return x;
}
public void setBeginExpr(Node beginExpr) {
if (beginExpr != null) {
beginExpr.setParent(this);
}
this.beginExpr = beginExpr;
}
public void setEndExpr(Node endExpr) {
if (endExpr != null) {
endExpr.setParent(this);
}
this.endExpr = endExpr;
}
}2 语义分析
写入事件回调
前面提到大批量导入数据时,词法语法分析阶段会产生很多AST小对象,给垃圾回收带来压力,解决这个问题的核心是要尽量使用基础数据类型,尽量不要产生AST 节点对象。需要从词法分析阶段入手,避免进入语法分析阶段。在词法分析阶段,允许外部注册实现了写入接口的类,每当词法分析器解析出values中的每个具体值,或者完整解析出values中的一行,同时回调写入接口,实现数据库写入逻辑。
public interface InsertValueHandler {
Object newRow() throws SQLException;
void processInteger(Object row, int index, Number value);
void processString(Object row, int index, String value);
void processDate(Object row, int index, String value);
void processDate(Object row, int index, java.util.Date value);
void processTimestamp(Object row, int index, String value);
void processTimestamp(Object row, int index, java.util.Date value);
void processTime(Object row, int index, String value);
void processDecimal(Object row, int index, BigDecimal value);
void processBoolean(Object row, int index, boolean value);
void processNull(Object row, int index);
void processFunction(Object row, int index, String funcName, Object... values);
void processRow(Object row);
void processComplete();
}
public class BatchInsertHandler implements InsertValueHandler {
...
}
public class Application {
BatchInsertHandler handler = new BatchInsertHandler();
parser.parseInsertHeader(); // 头部:解析 insert into xxx values 部分
parser.parseValues(handler); // 批量值:values (xxx), (xxx), (xxx) 部分
}Query Rewriting
手动编写的SQL Parser可以更灵活的与优化器配合,将Query rewriting 的部分优化能力前置化到SQL Parser中实现,使得优化器能更加专注于基于代价和成本的优化上。Parser可以结合Meta信息,利用“等价关系代数”,在AST上低成本实现Query Rewriting功能,以提升查询性能,例如:常量折叠、函数变换、条件下推或上提、类型推导、隐式转化、语义去重等。
首先,需要设计一个结构存储catalog和table结构信息,包括库名,表名,列名,列类型等。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java