
理解Java的String类
String类
在Java中String类的使用的频率可谓相当高。它是Java语言中的核心类,在java.lang包下,主要用于字符串的比较、查找、拼接等等操作。如果要深入理解一个类,最好的方法就是看看源码:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
//...
}从源码中,可以看出以下几点:
- String类被final关键字修饰,表示String类不能被继承,并且它的成员方法都默认为final方法。
- String类实现了Serializable、CharSequence、 Comparable接口。
- String类的值是通过char数组存储的,并且char数组被private和final修饰,字符串一旦创建就不能再修改。
下面通过几个问题不断加深对String类的理解。
问题一
上面说字符串一旦创建就不能再修改,String类提供的replace()方法不就可以替换修改字符串的内容吗?
实际上replace()方法并没有对原字符串进行修改,而是创建了一个新的字符串返回,看看源码就知道了。
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
//创建一个新的字符串返回
return new String(buf, true);
}
}
return this;
}其他方法也是一样,无论是sub、concat还是replace操作都不是在原有的字符串上进行的,而是重新生成了一个新的字符串对象。
问题二
为什么要使用final关键字修饰String类?
首先要讲final修饰类的作用,被final修饰的类不能被继承,类中的所有成员方法都会被隐式地指定为final方法。也就是不能拥有子类,成员方法也不能被重写。
回到问题,String类被final修饰主要基于安全性和效率两点考虑。
- 安全性
因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
String被许多的Java类(库)用来当做参数,比如网络连接地址URL,文件路径path,还有反射机制所需要的String参数等,假若String不是固定不变的,将会引起各种安全隐患。
- 效率
字符串不变性保证了hash码的唯一性,因此可以放心的进行缓存,这也是一种性能优化手段,意味着不必每次都取计算新的哈希码。
只有当字符串是不可变的,字符串池才有可能实现,字符串常量池是java堆内存中一个特殊的存储区域,当创建一个String对象,假如此字符串值已经存在于常量池中,则不会创建一个新的对象,而是引用已经存在的对象。
字符串常量池
字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串我们使用的非常多。JVM为了提高性能和减少内存的开销,所以在实例化字符串的时候使用字符串常量池进行优化。
池化思想其实在Java中并不少见,字符串常量池也是类似的思想,当创建字符串时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中。
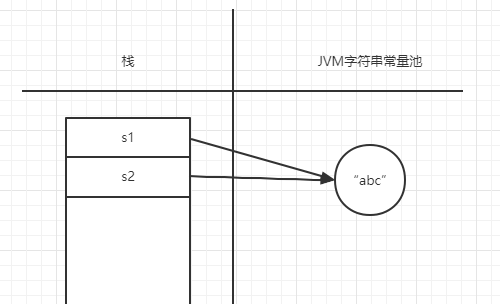
我们可以写个简单的例子证明:
public static void main(String[] args) throws Exception {
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);//true
}
还有一个面试中经常问的,new String(“abc”)创建了几个对象?
这可能就是想考你对字符串常量池的理解,我一般回答是一个或者两个对象。
如果之前"abc"字符串没有使用过,毫无疑问是创建两个对象,堆中创建了一个String对象,字符串常量池创建了一个,一共两个。
如果之前已经使用过了"abc"字符串,则不会再在字符串常量池创建对象,而是从字符串常量缓冲区中获取,只会在堆中创建一个String对象。
String s1 = "abc";
String s2 = new String("abc");
//s2这行代码,只会创建一个对象字符串拼接
字符串的拼接在Java中是很常见的操作,但是拼接字符串并不是简简单单地使用"+"号即可,还有一些要注意的点,否则会造成效率低下。
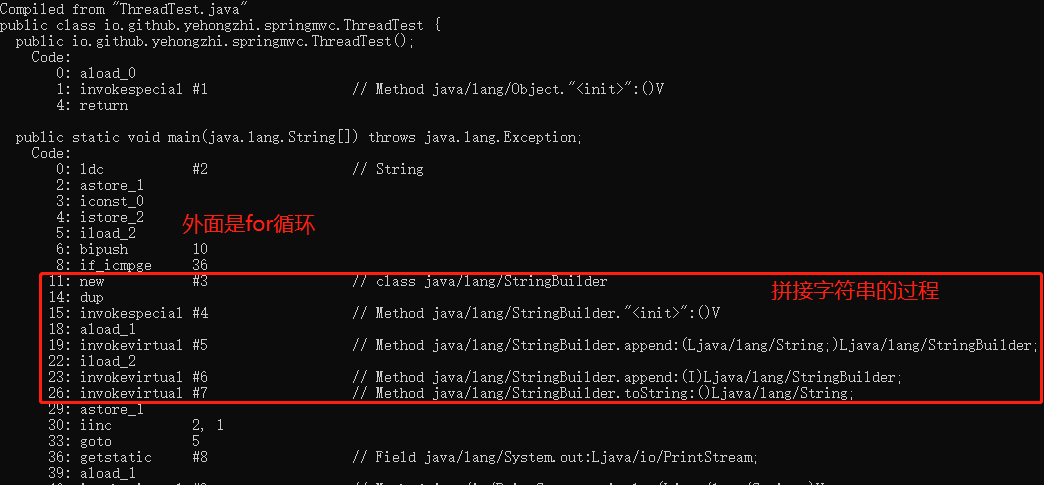
比如下面这段代码:
public static void main(String[] args) throws Exception {
String s = "";
for (int i = 0; i < 10; i++) {
s+=i;
}
System.out.println(s);//0123456789
}在循环内使用+=拼接字符串会有什么问题呢?我们反编译一下看看就知道了。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java