
几种Java常用序列化框架的选型与对比。
一 背景介绍
序列化与反序列化是我们日常数据持久化和网络传输中经常使用的技术,但是目前各种序列化框架让人眼花缭乱,不清楚什么场景到底采用哪种序列化框架。本文会将业界开源的序列化框架进行对比测试,分别从通用性、易用性、可扩展性、性能和数据类型与Java语法支持五方面给出对比测试。
- 通用性:通用性是指序列化框架是否支持跨语言、跨平台。
- 易用性:易用性是指序列化框架是否便于使用、调试,会影响开发效率。
- 可扩展性:随着业务的发展,传输实体可能会发生变化,但是旧实体有可能还会被使用。这时候就需要考虑所选择的序列化框架是否具有良好的扩展性。
- 性能:序列化性能主要包括时间开销和空间开销。序列化的数据通常用于持久化或网络传输,所以其大小是一个重要的指标。而编解码时间同样是影响序列化协议选择的重要指标,因为如今的系统都在追求高性能。
- Java数据类型和语法支持:不同序列化框架所能够支持的数据类型以及语法结构是不同的。这里我们要对Java的数据类型和语法特性进行测试,来看看不同序列化框架对Java数据类型和语法结构的支持度。
下面分别对JDK Serializable、FST、Kryo、Protobuf、Thrift、Hession和Avro进行对比测试。
二 序列化框架
1 JDK Serializable
JDK Serializable是Java自带的序列化框架,我们只需要实现java.io.Serializable或java.io.Externalizable接口,就可以使用Java自带的序列化机制。实现序列化接口只是表示该类能够被序列化/反序列化,我们还需要借助I/O操作的ObjectInputStream和ObjectOutputStream对对象进行序列化和反序列化。
下面是使用JDK 序列化框架进行编解码的Demo:

通用性
由于是Java内置序列化框架,所以本身是不支持跨语言序列化与反序列化。
易用性
作为Java内置序列化框架,无序引用任何外部依赖即可完成序列化任务。但是JDK Serializable在使用上相比开源框架难用许多,可以看到上面的编解码使用非常生硬,需要借助ByteArrayOutputStream和ByteArrayInputStream才可以完整字节的转换。
可扩展性
JDK Serializable中通过serialVersionUID控制序列化类的版本,如果序列化与反序列化版本不一致,则会抛出java.io.InvalidClassException异常信息,提示序列化与反序列化SUID不一致。
java.io.InvalidClassException: com.yjz.serialization.java.UserInfo; local class incompatible: stream classdesc serialVersionUID = -5548195544707231683, local class serialVersionUID = -5194320341014913710上面这种情况,是由于我们没有定义serialVersionUID,而是由JDK自动hash生成的,所以序列化与反序列化前后结果不一致。
但是我们可以通过自定义serialVersionUID方式来规避掉这种情况(序列化前后都是使用定义的serialVersionUID),这样JDK Serializable就可以支持字段扩展了。
private static final long serialVersionUID = 1L;性能
JDK Serializable是Java自带的序列化框架,但是在性能上其实一点不像亲生的。下面测试用例是我们贯穿全文的一个测试实体。
public class MessageInfo implements Serializable {
private String username;
private String password;
private int age;
private HashMap<String,Object> params;
...
public static MessageInfo buildMessage() {
MessageInfo messageInfo = new MessageInfo();
messageInfo.setUsername("abcdefg");
messageInfo.setPassword("123456789");
messageInfo.setAge(27);
Map<String,Object> map = new HashMap<>();
for(int i = 0; i< 20; i++) {
map.put(String.valueOf(i),"a");
}
return messageInfo;
}
}使用JDK序列化后字节大小为:432。光看这组数字也许不会感觉到什么,之后我们会拿这个数据和其它序列化框架进行对比。
我们对该测试用例进行1000万次序列化,然后计算时间总和:
| 1000万序列化耗时(ms) | 1000万反序列化耗时(ms) |
| 38952 | 96508 |
同样我们之后会同其它序列化框架进行对比。
数据类型和语法结构支持性
由于JDK Serializable是Java语法原生序列化框架,所以基本都能够支持Java数据类型和语法。
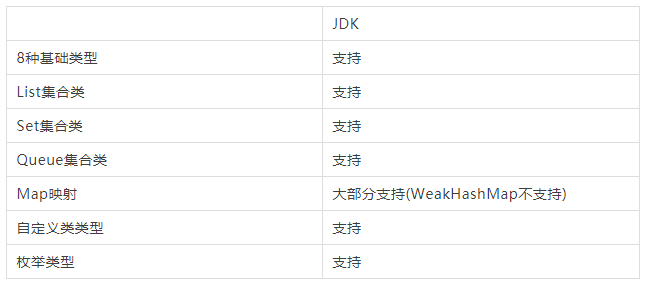
WeakHashMap没有实现Serializable接口。
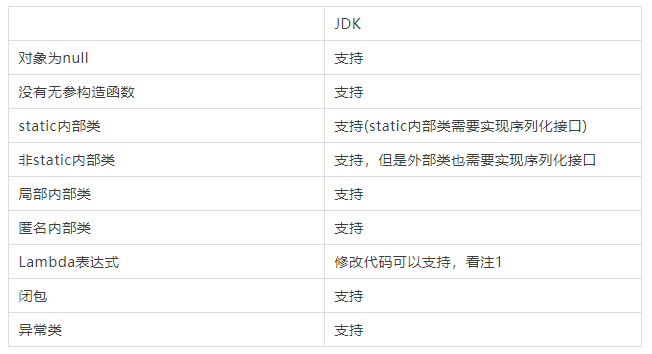
注1:但我们要序列化下面代码:
Runnable runnable = () -> System.out.println("Hello");直接序列化会得到以下异常:
com.yjz.serialization.SerializerFunctionTest$$Lambda$1/189568618原因就是我们Runnable的Lambda并没有实现Serializable接口。我们可以做如下修改,即可支持Lambda表达式序列化。
Runnable runnable = (Runnable & Serializable) () -> System.out.println("Hello");2 FST序列化框架
FST(fast-serialization)是完全兼容JDK序列化协议的Java序列化框架,它在序列化速度上能达到JDK的10倍,序列化结果只有JDK的1/3。目前FST的版本为2.56,在2.17版本之后提供了对Android的支持。
下面是使用FST序列化的Demo,FSTConfiguration是线程安全的,但是为了防止频繁调用时其成为性能瓶颈,一般会使用TreadLocal为每个线程分配一个FSTConfiguration。
private final ThreadLocal<FSTConfiguration> conf = ThreadLocal.withInitial(() -> {
FSTConfiguration conf = FSTConfiguration.createDefaultConfiguration();
return conf;
});
public byte[] encoder(Object object) {
return conf.get().asByteArray(object);
}
public <T> T decoder(byte[] bytes) {
Object ob = conf.get().asObject(bytes);
return (T)ob;
}通用性
FST同样是针对Java而开发的序列化框架,所以也不存在跨语言特性。
易用性
在易用性上,FST可以说能够甩JDK Serializable几条街,语法极其简洁,FSTConfiguration封装了大部分方法。
可扩展性
FST通过@Version注解能够支持新增字段与旧的数据流兼容。对于新增的字段都需要通过@Version注解标识,没有版本注释意味着版本为0。
private String origiField;
@Version(1)
private String addField;注意:
- 删除字段将破坏向后兼容性,但是如果我们在原始字段情况下删除字段是能够向后兼容的(没有新增任何字段)。但是如果新增字段后,再删除字段的话就会破坏其兼容性。
- Version注解功能不能应用于自己实现的readObject/writeObject情况。
- 如果自己实现了Serializer,需要自己控制Version。
综合来看,FST在扩展性上面虽然支持,但是用起来还是比较繁琐的。
性能
使用FST序列化上面的测试用例,序列化后大小为:172,相比JDK序列化的432 ,将近减少了1/3。下面我们再看序列化与反序列化的时间开销。

我们可以优化一下FST,将循环引用判断关闭,并且对序列化类进行余注册。
private static final ThreadLocal<FSTConfiguration> conf = ThreadLocal.withInitial(() -> {
FSTConfiguration conf = FSTConfiguration.createDefaultConfiguration();
conf.registerClass(UserInfo.class);
conf.setShareReferences(false);
return conf;
});通过上面的优化配置,得到的时间开销如下:

可以看到序列化时间将近提升了2倍,但是通过优化后的序列化数据大小增长到了191 。
数据类型和语法结构支持性
FST是基于JDK序列化框架而进行开发的,所以在数据类型和语法上和Java支持性一致。
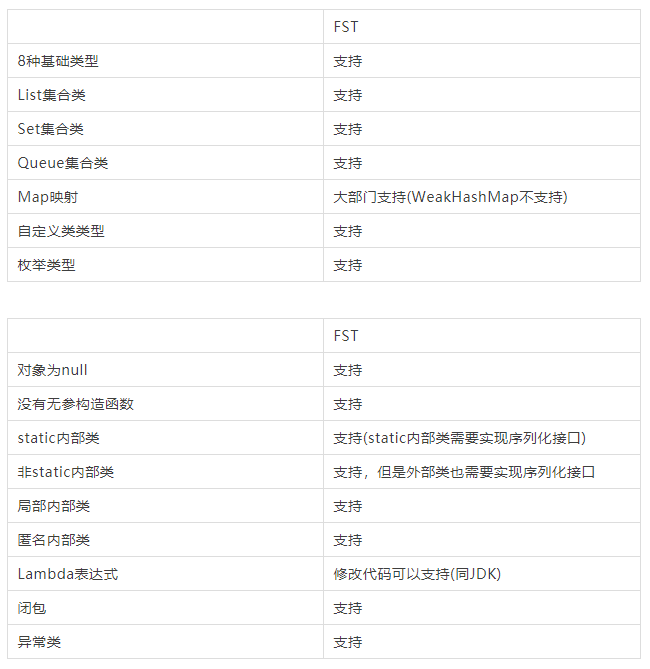
3 Kryo序列化框架
Kryo一个快速有效的Java二进制序列化框架,它依赖底层ASM库用于字节码生成,因此有比较好的运行速度。Kryo的目标就是提供一个序列化速度快、结果体积小、API简单易用的序列化框架。Kryo支持自动深/浅拷贝,它是直接通过对象->对象的深度拷贝,而不是对象->字节->对象的过程。
下面是使用Kryo进行序列化的Demo:

需要注意的是使用Output.writeXxx时候一定要用对应的Input.readxxx,比如Output.writeClassAndObject()要与Input.readClassAndObject()。
通用性
首先Kryo官网说自己是一款Java二进制序列化框架,其次在网上搜了一遍没有看到Kryo的跨语言使用,只是一些文章提及了跨语言使用非常复杂,但是没有找到其它语言的相关实现。
易用性
在使用方式上Kryo提供的API也是非常简洁易用,Input和Output封装了你几乎能够想到的所有流操作。Kryo提供了丰富的灵活配置,比如自定义序列化器、设置默认序列化器等等,这些配置使用起来还是比较费劲的。
可扩展性
Kryo默认序列化器FiledSerializer是不支持字段扩展的,如果想要使用扩展序列化器则需要配置其它默认序列化器。
比如:
private static final ThreadLocal<Kryo> kryoLocal = ThreadLocal.withInitial(() -> {
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
kryo.setDefaultSerializer(TaggedFieldSerializer.class);
return kryo;
});性能
使用Kryo测试上面的测试用例,Kryo序列化后的字节大小为172 ,和FST未经优化的大小一致。时间开销如下:

我们同样关闭循环引用配置和预注册序列化类,序列化后的字节大小为120,因为这时候类序列化的标识是使用的数字,而不是类全名。使用的是时间开销如下:

数据类型和语法结构支持性
Kryo对于序列化类的基本要求就是需要含有无参构造函数,因为反序列化过程中需要使用无参构造函数创建对象。
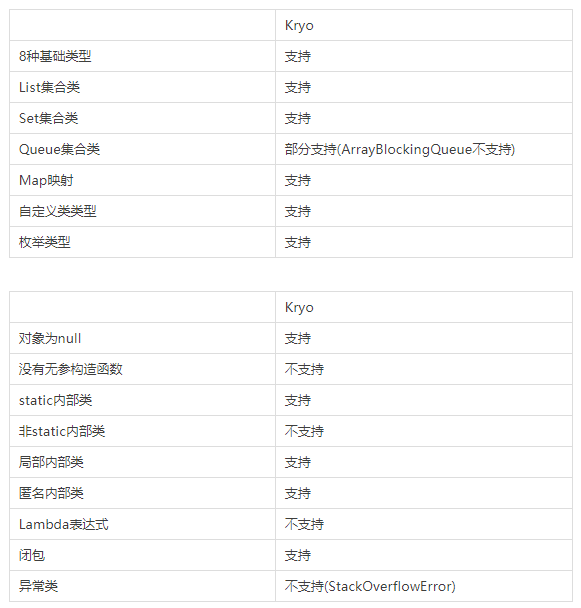
4 Protocol buffer
Protocol buffer是一种语言中立、平台无关、可扩展的序列化框架。Protocol buffer相较于前面几种序列化框架而言,它是需要预先定义Schema的。
下面是使用Protobuf的Demo:
(1)编写proto描述文件:
syntax = "proto3";
option java_package = "com.yjz.serialization.protobuf3";
message MessageInfo
{
string username = 1;
string password = 2;
int32 age = 3;
map<string,string> params = 4;
}(2)生成Java代码:
protoc --java_out=./src/main/java message.proto(3)生成的Java代码,已经自带了编解码方法:

通用性
protobuf设计之初的目标就是能够设计一款与语言无关的序列化框架,它目前支持了Java、Python、C++、Go、C#等,并且很多其它语言都提供了第三方包。所以在通用性上,protobuf是非常给力的。
易用性
protobuf需要使用IDL来定义Schema描述文件,定义完描述文件后,我们可以直接使用protoc来直接生成序列化与反序列化代码。所以,在使用上只需要简单编写描述文件,就可以使用protobuf了。
可扩展性
可扩展性同样是protobuf设计之初的目标之一,我们可以非常轻松的在.proto文件进行修改。
新增字段:对于新增字段,我们一定要保证新增字段要有对应的默认值,这样才能够与旧代码交互。相应的新协议生成的消息,可以被旧协议解析。
删除字段:删除字段需要注意的是,对应的字段、标签不能够在后续更新中使用。为了避免错误,我们可以通过reserved规避带哦。

protobuf在数据兼容性上也非常友好,int32、unit32、int64、unit64、bool是完全兼容的,所以我们可以根据需要修改其类型。
通过上面来看,protobuf在扩展性上做了很多,能够很友好的支持协议扩展。
性能
我们同样使用上面的实例来进行性能测试,使用protobuf序列化后的字节大小为 192,下面是对应的时间开销。

可以看出protobuf的反序列化性能要比FST、Kryo差一些。
数据类型和语法结构支持
Protobuf使用IDL定义Schema所以不支持定义Java方法,下面序列化变量的测试:
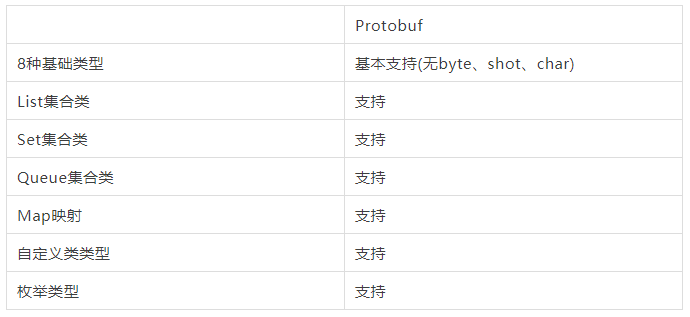
注:List、Set、Queue通过protobuf repeated定义测试的。只要实现Iterable接口的类都可以使用repeated列表。
5 Thrift序列化框架
Thrift是由Facebook实现的一种高效的、支持多种语言的远程服务调用框架,即RPC(Remote Procedure Call)。后来Facebook将Thrift开源到Apache。可以看到Thrift是一个RPC框架,但是由于Thrift提供了多语言之间的RPC服务,所以很多时候被用于序列化中。
使用Thrift实现序列化主要分为三步,创建thrift IDL文件、编译生成Java代码、使用TSerializer和TDeserializer进行序列化和反序列化。
(1)使用Thrift IDL定义thrift文件:
namespace java com.yjz.serialization.thrift
struct MessageInfo{
1: string username;
2: string password;
3: i32 age;
4: map<string,string> params;
}(2)使用thrift编译器生成Java代码:
thrift --gen java message.thrift(3)使用TSerializer和TDeserializer进行编解码:
public static byte[] encoder(MessageInfo messageInfo) throws Exception{
TSerializer serializer = new TSerializer();
return serializer.serialize(messageInfo);
}
public static MessageInfo decoder(byte[] bytes) throws Exception{
TDeserializer deserializer = new TDeserializer();
MessageInfo messageInfo = new MessageInfo();
deserializer.deserialize(messageInfo,bytes);
return messageInfo;
}通用性
Thrift和protobuf类似,都需要使用IDL定义描述文件,这是目前实现跨语言序列化/RPC的一种有效方式。Thrift目前支持 C++、Java、Python、PHP、Ruby、 Erlang、Perl、Haskell、C#、Cocoa、JavaScript、Node.js、Smalltalk、OCaml、Delphi等语言,所以可以看到Thrift具有很强的通用性。
易用性
Thrift在易用性上和protobuf类似,都需要经过三步:使用IDL编写thrift文件、编译生成Java代码和调用序列化与反序列化方法。protobuf在生成类中已经内置了序列化与反序列化方法,而Thrift需要单独调用内置序列化器来进行编解码。
可扩展性
Thrift支持字段扩展,在扩展字段过程中需要注意以下问题:
- 修改字段名称:修改字段名称不影响序列化与反序列化,反序列化数据赋值到更新过的字段上。因为编解码过程利用的是编号对应。
- 修改字段类型:修改字段类型,如果修改的字段为optional类型字段,则返回数据为null或0(数据类型默认值)。如果修改是required类型字段,则会直接抛出异常,提示字段没有找到。
- 新增字段:如果新增字段是required类型,则需要为其设置默认值,负责在反序列化过程抛出异常。如果为optional类型字段,反序列化过程不会存在该字段(因为optional字段没有赋值的情况,不会参与序列化与反序列化)。如果为缺省类型,则反序列化值为null或0(和数据类型有关)。
- 删除字段:无论required类型字段还是optional类型字段,都可以删除,不会影响反序列化。
- 删除后的字段整数标签不要复用,负责会影响反序列化。
性能
上面的测试用例,使用Thrift序列化后的字节大小为:257,下面是对应的序列化时间与反序列化时间开销:

Thrift在序列化和反序列化的时间开销总和上和protobuf差不多,protobuf在序列化时间上更占优势,而Thrift在反序列化上有自己的优势。
数据类型和语法结构支持
数据类型支持:由于Thrift使用IDL来定义序列化类,所以能够支持的数据类型就是Thrift数据类型。Thrift所能够支持的Java数据类型:
- 8中基础数据类型,没有short、char,只能使用double和String代替。
- 集合类型,支持List、Set、Map,不支持Queue。
- 自定义类类型(struct类型)。
- 枚举类型。
- 字节数组。
Thrift同样不支持定义Java方法。
6 Hessian序列化框架
Hessian是caucho公司开发的轻量级RPC(Remote Procedure Call)框架,它使用HTTP协议传输,使用Hessian二进制序列化。
Hessian由于其支持跨语言、高效的二进制序列化协议,被经常用于序列化框架使用。Hessian序列化协议分为Hessian1.0和Hessian2.0,Hessian2.0协议对序列化过程进行了优化(优化内容待看),在性能上相较Hessian1.0有明显提升。
使用Hessian序列化非常简单,只需要通过HessianInput和HessianOutput即可完成对象的序列化,下面是Hessian序列化的Demo:
public static <T> byte[] encoder2(T obj) throws Exception{
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output hessian2Output = new Hessian2Output(bos);
hessian2Output.writeObject(obj);
return bos.toByteArray();
}
public static <T> T decoder2(byte[] bytes) throws Exception {
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
Hessian2Input hessian2Input = new Hessian2Input(bis);
Object obj = hessian2Input.readObject();
return (T) obj;
}通用性
Hessian与Protobuf、Thrift一样,支持跨语言RPC通信。Hessian相比其它跨语言PRC框架的一个主要优势在于,它不是采用IDL来定义数据和服务,而是通过自描述来完成服务的定义。目前Hessian已经实现了语言包括:Java、Flash/Flex、Python、C++、.Net/C#、D、Erlang、PHP、Ruby、Object-C。
易用性
相较于Protobuf和Thrift,由于Hessian不需要通过IDL来定义数据和服务,对于序列化的数据只需要实现Serializable接口即可,所以使用上相比Protobuf和Thrift更加容易。
可扩展性
Hession序列化类虽然需要实现Serializable接口,但是它并不受serialVersionUID影响,能够轻松支持字段扩展。
- 修改字段名称:反序列化后新字段名称为null或0(受类型影响)。
- 新增字段:反序列化后新增字段为null或0(受类型影响)。
- 删除字段:能够正常反序列化。
- 修改字段类型:如果字段类型兼容能够正常反序列化,如果不兼容则直接抛出异常。
性能
使用Hessian1.0协议序列化上面的测试用例,序列化结果大小为277。使用Hessian2.0序列化协议,序列化结果大小为178。
序列化化与反序列化的时间开销如下:

可以看到Hessian1.0的无论在序列化后体积大小,还是在序列化、反序列化时间上都比Hessian2.0相差很远。
数据类型和语法结构支持
由于Hession使用Java自描述序列化类,所以Java原生数据类型、集合类、自定义类、枚举等基本都能够支持(SynchronousQueue不支持),Java语法结构也能够很好的支持。
7 Avro序列化框架
Avro是一个数据序列化框架。它是Apache Hadoop下的一个子项目,由Doug Cutting主导Hadoop过程中开发的数据序列化框架。Avro在设计之初就用于支持数据密集型应用,很适合远程或本地大规模数据交换和存储。
使用Avro序列化分为三步:
(1)定义avsc文件:
{
"namespace": "com.yjz.serialization.avro",
"type": "record",
"name": "MessageInfo",
"fields": [
{"name": "username","type": "string"},
{"name": "password","type": "string"},
{"name": "age","type": "int"},
{"name": "params","type": {"type": "map","values": "string"}
}
]
}(2)使用avro-tools.jar编译生成Java代码(或maven编译生成):
java -jar avro-tools-1.8.2.jar compile schema src/main/resources/avro/Message.avsc ./src/main/java(3)借助BinaryEncoder和BinaryDecoder进行编解码:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java