
基于 RocketMQ 的在线消息系统建设实践。
为什么建设在线消息系统
在引入RocketMQ之前,快手已经在大量的使用Kafka了,但并非所有情况下Kafka都是最合适的,比如以下场景:
- 业务希望个别消费失败以后可以重试,并且不堵塞后续其它消息的消费。
- 业务希望消息可以延迟一段时间再投递。
- 业务需要发送的时候保证数据库操作和消息发送是一致的(也就是事务发送)。
- 为了排查问题,有的时候业务需要一定的单个消息查询能力。
为了应对以上这类场景,我们需要建设一个主要面向在线业务的消息系统,作为Kafka的补充。在考察的一些消息中间件中,RocketMQ和业务需求匹配度比较高,同时部署结构简单,使用的公司也比较多,于是最后我们就采用了RocketMQ。
部署模式和落地策略
在一个已有的体系内落地一个开软软件,通常大概有两种方式:
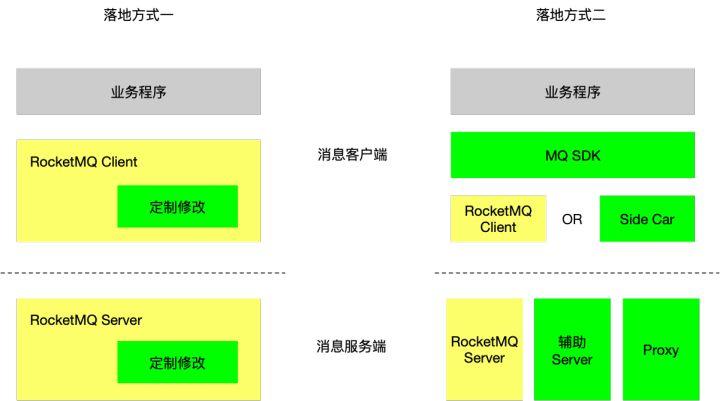
方式一,在开源软件的基础上做深度修改,很容易实现公司内需要的定制功能。但和社区开源版本分道扬镳,以后如何升级?
方式二,尽量不修改社区版本(或减少不兼容的修改),而是在它的外围或者上层进一步包装来实现公司内部需要的定制功能。
注:上图方式一的图画的比较极端,实际上很多公司是方式一、方式二结合的。
我们选择了方式二。最早的时候,我们使用的是4.5.2版本,后来社区4.7版本大幅减小了同步复制的延迟,正好我们的部署模式就是同步复制,于是就很轻松的升级了4.7系列,享受了新版本的红利。
在部署集群的时候,还会面临很多部署策略的选择:
• 大集群 vs 小集群
• 选择副本数
• 同步刷盘 vs 异步刷盘
• 同步复制 vs 异步复制
• SSD vs 机械硬盘
大集群会有更好的性能弹性,而小集群具有更好的隔离型,此外小集群可以不需要跨可用区/IDC部署,所以会有更好的健壮性,我们非常看重稳定性,因此选择了小集群。集群同步复制异步刷盘,首选SSD。
客户端封装策略
如上所述,我们没有在Rocketmq里面做深度修改,所以需要提供一个SDK来提供公司内的需要的定制功能,这个SDK大概是这样的:
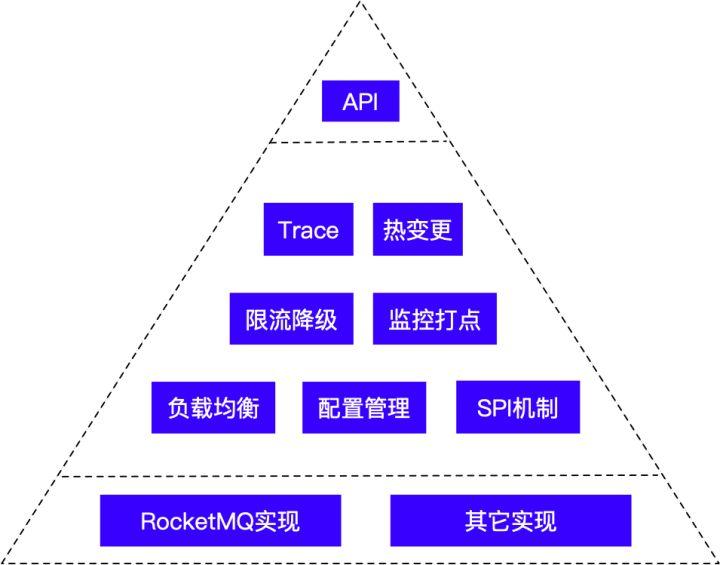
对外只提供最基本的API,所有访问必须经过我们提供的接口。简洁的API就像冰山的一个角,除了对外的简单接口,下面所有的东西都可以升级更换,而不会破坏兼容性。
业务开发起来也很简单,只要需要提供Topic(全局唯一)和Group就可以生产和消费,不用提供环境、Name Server地址等。SDK内部会根据Topic解析出集群Name Server的地址,然后连接相应的集群。生产环境和测试环境环境会解析出不同的地址,从而实现了隔离。
上图分为3层,第二层是通用的,第三层才对应具体的MQ实现,因此,理论上可以更换为其它消息中间件,而客户端程序不需要修改。
SDK内部集成了热变更机制,可以在不重启client的情况下做动态配置,比如下发路由策略(更换集群name server的地址,或者连接到别的集群去),Client的线程数、超时时间等。通过maven强制更新机制,可以保证业务使用的SDK基本上是最新的。
集群负载均衡 & 机房灾备
所有的Topic默认都分配到两个可用区,生产者和消费者会同时连接至少两个独立集群(分布在不同的可用区),如下图:

生产者同时连接两个集群,如果可用区A出现故障,流量就会自动切换到可用区B的集群2去。我们开发了一个小组件来实现自适应的集群负载均衡,它包含以下能力:
• 千万级OPS
• 灵活的权重调整策略
• 健康检查支持/事件通知
• 并发度控制(自动降低响应慢的服务器的请求数)
• 资源优先级(类似Envoy,实现本地机房优先,或是被调服务器很多的时候选取一个子集来调用)
• 自动优先级管理
• 增量热变更
实际上它并不仅仅用于消息生产者,而是一个通用的主调方负载均衡类库,可以在github上找到:https://github.com/PhantomThief/simple-failover-java
核心的SimpleFailover接口和PriorityFailover类没有传递第三方依赖,非常容易整合。
多样的消息功能
延迟消息
延迟消息是非常重要的业务功能,不过RocketMQ内置的延迟消息只能支持几个固定的延迟级别,所以我们又开发了单独的Delay Server来调度延迟消息:
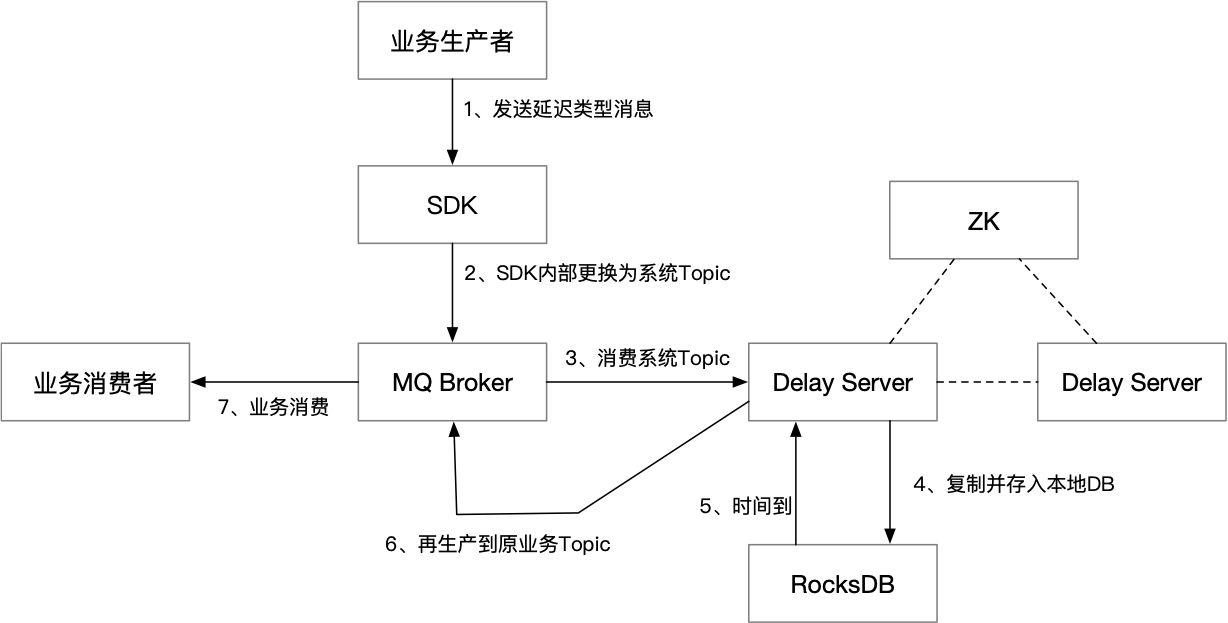
上图这个结构没有直接将延迟消息发到Delay Server,而是更换Topic以后存入RocketMQ。这样的好处是可以复用现有的消息发送接口(以及上面的所有扩展能力)。对业务来说,只需要在构造消息的时候额外指定一个延迟时间字段即可,其它用法都不变。
事务消息
RocketMQ 4.3版本以后支持了事务消息,可以保证本地事务和消费发送同时成功或者失败,对于一些业务场景很有帮助。事务消息的用法和原理有很多资料,这里就不细述了。但关于事务消息的实践网上资料较少,我们可以给出一些建议。
首先,事务消息功能一直在不断完善,应该使用最新的版本,至少是4.6.1以后的版本,可以避免很多问题。
其次,事务消息性能是不如普通消息的,它在内部实际上会生成3个消息(一阶段1个,二阶段2个),所以性能大约只有普通消息的1/3,如果事务消息量大的话,要做好容量规划。回查调度线程也只有1个,不要用极限压力去考验它。
最后有一些参数注意事项。在broker的配置中:
- transientStorePoolEnable这个参数必须保持默认值false,否则会有严重的问题。
- endTransactionThreadPoolNums是事务消息二阶段处理线程大小,sendMessageThreadPoolNums则指定一阶段处理线程池大小。如果二阶段的处理速度跟不上一阶段,就会造成二阶段消息丢失导致大量回查,所以建议endTransactionThreadPoolNums应该大于sendMessageThreadPoolNums,建议至少4倍。
- useReentrantLockWhenPutMessage设置为true(默认值是false),以免线程抢锁出现严重的不公平,导致二阶段处理线程长时间抢不到锁。
- transactionTimeOut默认值6秒太短了,如果事务执行时间超过6秒,就可能导致消息丢失。建议改到1分钟左右。
生产者client也有一个注意事项,如果有多组broker,并且是2副本(有1个Slave),应该打开
retryAnotherBrokerWhenNotStoreOK,以免某个Slave出现故障以后,大量消息发送失败。
分布式对账监控
除了比较一些常规的监控手段以外,我们开发了一个监控程序做分布式对账。可以发现我们的集群以及我们提供的SDK是否有异常。
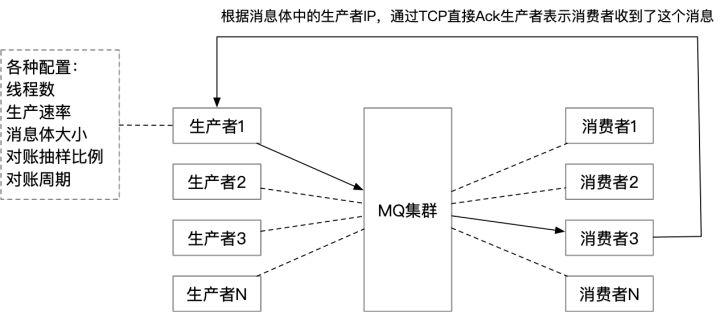
具体做法是在每个Broker上都建立一个监控专用的Topic,监控程序使用我们自己提供的SDK框架来连接集群(就像我们的业务用户那样),监控生产者会给每个集群发送少量消息。然后检查发送是否成功:
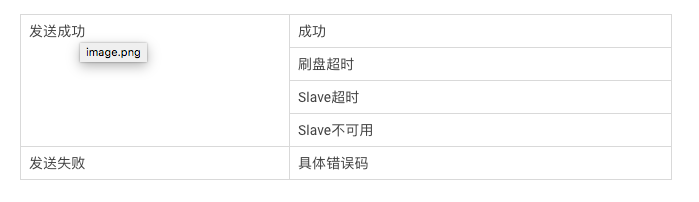
生产者只对这些结果进行打点,不判断是否正常,具体到监控(或者演练)场景可以配置不同的报警规则。
消费者收到了消息会通过TCP旁路Ack生产者,生产者这边会做分布式对账,将对账结果打点:
- 收到消息
- 消息丢失(或超时未收到消息)
- 重复收到消息
- 消息生成到最终消费的时间差
- Ack生产者失败(由消费者打点)
同样监控程序只负责打点,报警规则可另外配置。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java