
分布式数据库实现 Join。
用关系型数据库一定多多少少会用到 Join 操作。常见的 Join 有 Nested-Loop Join,Hash Join,Sort Merge Join 等等。实际在 OLTP 场景中,最常用的就是基于索引点查的 Index Nested-Loop Join,这样的 Join 往往能在极短的时间内返回,相信这也是大多数开发同学对 Join 的感受。
PolarDB-X 不仅语法兼容 MySQL,作为分布式数据库,也力求保持与单机数据库一致的使用体验。在分布式场景下,Join 的两张表可能都是分布式表,因此需要通过多次网络请求获取相应的数据。如何高效地实现这一点呢?
MySQL 的 Join 实现
我们先看看单机数据库上的 Join 是怎么做的。MySQL 支持的 Join 算法很有限:
- Nested-Loop Join (NL Join)
- Batched Key Access Join (BKA Join)
- Block Nested-Loop Join(版本 < 8.0.20)
- Hash Join (版本 >= 8.0.18)
如果 Join 两侧的任何一张表上 join key 列存在索引,那么 MySQL 通常会使用基于索引的 BKA Join 或 NL Join,我们实际使用中的绝大多数情形都对应这种方式。如果 Join 两侧都没有索引可以用,那么 MySQL 只能退而求其次选择 Block Nested-Loop Join 或 Hash Join(取决于 MySQL 版本)。我们今天主要关注 NL 和 BKA Join。
Nested-Loop Join 是最简单的 Join 形式,可以看作一个两层 For 循环。对于外表(也称为驱动表)中的每一行,循环检查内表(也称为被驱动表)的每一行,如果满足 Join 条件则作为 Join 结果输出。如果 Join Key 在内侧表有索引可用,那么内表的循环可以大大简化——只要查索引即可拿到可以 Join 的行,无需遍历整个表。我们也将这种带索引的 NL Join 称为 Index Nested-Loop Join。
# Nested-Loop Join for outer_row in outer_table: for inner_row in inner_table: if join_condition is True: output (outer_row, inner_row) # Index Nested-Loop Join for outer_row in outer_table: for inner_row in inner_index.lookup(outer_join_key): if join_condition is True: output (outer_row, inner_row)
注:*左右滑动阅览
下面的例子中,orders 表通过 customer 表的主键 c_custkey 与之进行 Join,MySQL 会使用 Index NL Join 算法完成 Join。
/* Query 1 */ SELECT o_orderkey, o_custkey, c_name FROM orders JOIN customer ON o_custkey = c_custkey WHERE o_orderkey BETWEEN 1001 AND 1005
注:*左右滑动阅览
![]()
![]()
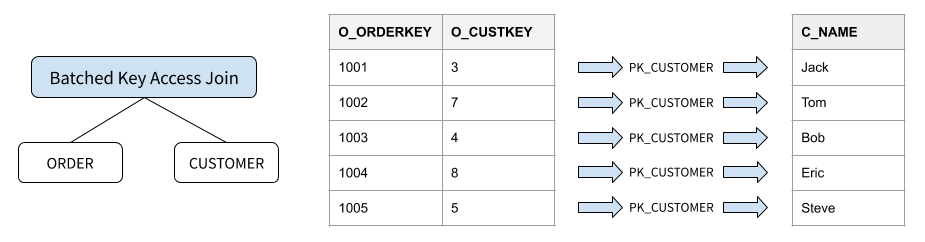
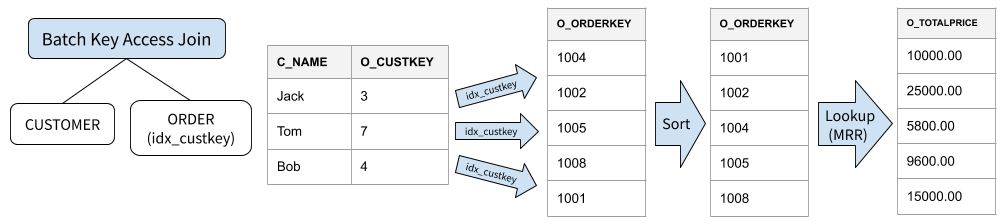
BKA Join 可以看作一个性能优化版的 Index Nested-Loop Join。之所以称为 Batched,是因为它的实现使用了存储引擎提供的 MRR(Multi-Range Read) 接口批量进行索引查询,并通过 PK 排序的方法,将随机索引回表转化为顺序回表,一定程度上加速了查索引的磁盘 IO。
下面的例子中,Join Key 命中的是二级索引,并且 SELECT 的列包含二级索引中所不包含的列,因此需要进行索引回表得到完整的 Join 结果。
/* Query 2 */ SELECT c_name, c_custkey, o_orderkey, o_totalprice FROM customer JOIN orders ON c_cutkey = o_custkey WHERE c_custkey BETWEEN 13 AND 15
注:*左右滑动阅览
![]()
![]()
通常 OLTP 查询中 Join 驱动侧的数据量不大,并且 Join 往往都有能匹配的索引。这种情况下,NL Join、BKA Join 的代价与驱动侧的数据量呈线性相关,可以迅速计算出结果。
PolarDB-X 的 Lookup Join
PolarDB-X 的架构与 MySQL 有很大的不同,它的架构可以分为 SQL 层和存储层,SQL 层的计算节点需要计算数据所在的分片,然后从多个 DN 节点(数据节点)拉取所需的数据。
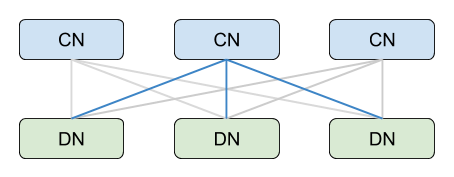
对于 Join 查询,如果恰好 Join Key 和拆分键一致,那么可以将其下推到 DN 执行。否则,就需要在 CN 节点执行 Join。PolarDB-X 支持多种 Join 算法,包括 Lookup Join、Nested-Loop Join、Hash Join、Sort-Merge Join 等多种执行方式。在 OLTP 查询中最常用的就是类似 MySQL BKA Join 的 Lookup Join,本文主要介绍 Lookup Join,其他 Join 诸如 Hash Join、Nested-Loop Join 等将在以后的文章中介绍。
除了 Join 本身的功能需求,PolarDB-X 的 Lookup Join 的设计中还要考虑以下两个性能需求:
- 批量。在分布式数据库中,CN 到 DN 的每一次查询都会经过网络 RPC,其延迟相比 MySQL 的本地调用要大几个数量级,因此批量处理显得更为重要。
- 并发。由于数据可能分布在多个 DN 节点上,如果依次遍历则会引入大量不必要的等待,最好的做法是并发地对所有 DN 进行查询,这样每批数据仅需一次网络 round-trip。
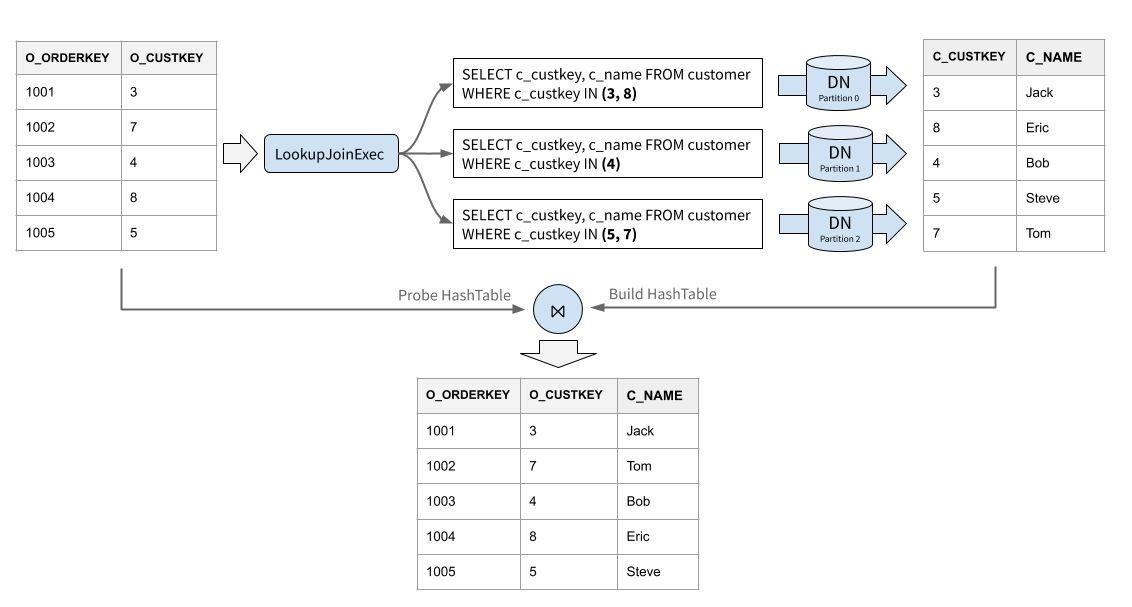
Lookup Join 的执行过程如下(非索引回表情形):
- 从驱动侧拉取一批数据。通常情况下数据量不会很多,如果数据较多,那么每个批的大小受到 lookup 端的分片数量以及是否可以进行分片裁剪限制。批大小的选择会直接影响查询性能,如果批特别小会导致 RPC 次数太高,批太大则会导致内存中暂存的数据量膨胀,高并发情况下可能导致 OOM。默认情况下我们尽可能让每个分片平均查询 50 个值、最多不超过 300 个值。
- 计算 batch 内每行数据所在分片,由于 lookup 侧是一个分区表,驱动表的每行数据要 lookup 的数据位于不同的分区中。只有包含数据的分片才需要参与 Join,如果没有任何值被路由到某个分片上,那么这个分片也无需被 Lookup。
- 并发请求所有需要 lookup 的分片,并将查到的数据行以 Join Key 为 Key 构建成哈希表,缓存在内存中。
- 类似于 Hash Join,利用哈希表为驱动侧的每行找到与其 Join 的行,取决于 Join 类型,可能 Join 出 0 行、1 行或多行。
/* Query 1 */ SELECT o_orderkey, o_custkey, c_name FROM orders JOIN customer ON o_cutkey = c_custkey WHERE o_orderkey BETWEEN 1001 AND 1005
注:*左右滑动阅览
这个过程中有一些有趣的细节,例如,当要 lookup 的列不止一列(例如 X = A AND Y = B)时如何处理?这时可以通过 row-expression 组成多列的 IN 条件。如果多列 IN 条件中出现 NULL 如何处理?对于 Anti-Join 如何处理?这些就不在这里展开了,有兴趣的同学可以在评论交流。
对于绝大多数 TP 查询,Lookup Join 都可以通过一次 lookup 完成 Join,将延迟降到了最低。
全局索引与 Lookup Join
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java