
ClickHouse:人群圈选业务的大杀器
什么是人群圈选
随着数据时代的发展,各行各业数据平台的体量越来越大,用户个性化运营的诉求也越来越突出,用户标签系统,做为个性化千人千面运营的基础服务,应运而生。如今,几乎所有行业(如互联网、游戏、教育等)都有实时精准营销的需求。通过系统生成用户画像,在营销时通过条件组合筛选用户,快速提取目标群体,例如:
- 电商行业中,商家在运营活动前,需要根据活动的目标群体的特征,圈选出一批目标用户进行广告推送或进行活动条件的判断。
- 游戏行业中,商家需要根据玩家的某些特征进行圈选,针对性地发放大礼包,提高玩家活跃度。
- 教育行业中,需要根据学生不同的特征,推送有针对性的习题,帮助学生查缺补漏。
- 搜索、门户、视频网站等业务中,根据用户的关注热点,推送不同的内容。
以电商平台中一个典型的目标群体圈选场景为例,如服装行业对其潜在客户信息采集,打标,清洗后如下表:
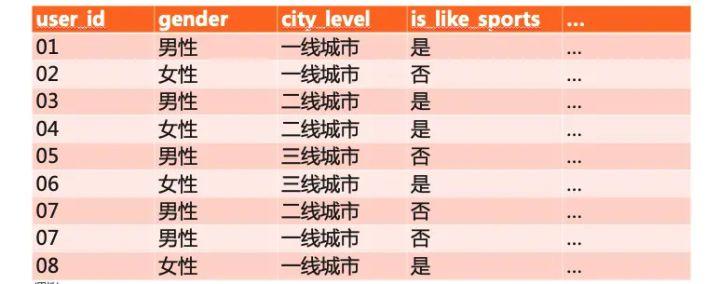
(以上表结构中,第一列为用户身份的唯一标识,往往作为主键,其他列均为标签列。)
如公司想推出一款高端男性运动产品,则可能的圈选条件为:
- 男性,推出产品的受众群体为男性。
- 运动爱好者,运动爱好者更有可能消费运动类产品。
- 一线城市,一线城市用户相比于二三线城市用户,可能更倾向于消费高端产品。
- ...
从上述表结构(人群圈选典型表结构,且大都如此,第一列为用户id,其余皆为标签列)和查询条件可以看出,人群圈选业务都面临一些共同的痛点:
- 用户标签多、标签丰富,标签列可达成百甚至上千列。
- 数据量庞大,用户数多,从而所需运算量也极大。
- 圈选条件组合多样化,没有固定索引可以优化,存储空间占用极大。
- 性能要求高,圈选结果要求及时响应,过长的延时会造成营销人群的不准确。
- 数据更新时效要求高,用户画像要求近实时的更新,过期的人群信息也将直接影响圈选的精准性。
针对以上痛点,本文将从原理层面深度分析,多角度对比讲解如何使用ClickHouse搭建人群圈选系统,为何选择ClickHouse,以及选用ClickHouse搭建人群圈选系统的优势。
为什么选择ClickHouse
本文以开源ElasticSearch(ES)为例,仅针对人群圈选场景与ClickHouse做对比。开源版ES是一款高效的搜索分析引擎,利用其优秀的索引技术,可以完成各种复杂的条件组合和数据聚合运算。ClickHouse是最近比较火的一款开源列式存储分析型数据库,它最核心的特点就是极致存储压缩率和查询性能,尤其擅长单个大宽表的查询场景。因此细比两者,相较于ClickHouse,ES虽具备人群圈选业务所需的必要能力,但仍有以下3方面不足:
成本方面:
开源ES的底层存储使用lucene,主要包含行存储(storefiled),列存储(docvalues)和倒排索引(invertindex)。行存中_source字段用于控制doc原始数据的存储。在写入数据时,ES把doc原始数据的整个json结构体当做一个string,存储为_source字段,因此_source字段对存储占用量大且关闭_source将不支持update操作。同时,索引也是ES不可缺少的一部分,ES默认全列索引,虽可手动设置对特定的列取消索引,但取消索引的列将不可查询。在人群圈选场景下,选取标签过滤条件是任意的,多样的,不断变化的。对任意一条标签列不做索引都是不现实的,因此针对成百上千列的大宽表,全列索引必然使得存储成本翻倍。
ClickHouse是一款彻底的列式存储数据库,且ClickHouse的查询不依赖索引,使用过程中也不强制构建索引,因此不需要保留额外的索引文件。同时ClickHouse存储数据的副本数量灵活可配,可将使用成本降至最低。
数据更新与治理方面:
索引为ES带来了高效的查询性能,但是索引的构造过程是复杂的,耗时的。每一次索引的构建都需对全列数据进行扫描,排序来生成索引文件。而在人群圈选业务中,人群信息必然是不断增长的。标签的不断更新将会使得ES不得不频繁的重构索引,这将对ES的性能造成巨大的开销。
ClickHouse的查询不依赖索引,使用过程中也不强制构建索引。因此对于新增数据,ClickHouse不涉及索引的更新与维护。
易用性方面:
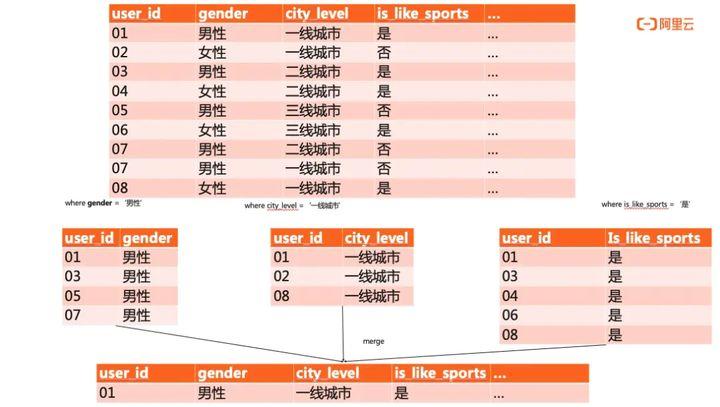
开源ES缺少完备的sql支持,查询请求的json格式复杂。同时ES对多条件过滤聚合的执行策略缺少优化,还以文章开头的典型场景为例,圈出一款高端男性运动产品的受众人群。可得如下sql:
“SELECT user_id FROM whatever_table WHERE city_level = '一线城市' AND gender = '男性' AND is_like_sports = '是';”
针对以上sql,ES的执行会对3个标签分别做3次索引扫描,之后再将3次扫描的结果做merge,流程如下图所示
而ClickHouse的执行则更优雅一些。ClickHouse采用标准sql,语法简单且功能强大。在执行where语句时,会自动优化形成prewhere分层执行,因此二次扫描将基于一次扫描的结果进行,执行流程如下图所示:
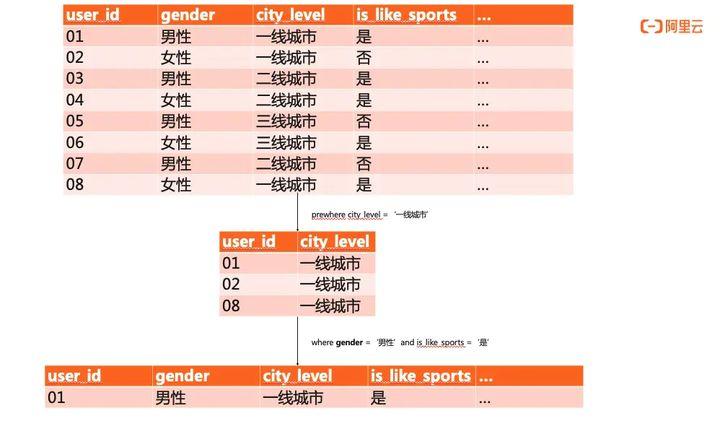
显而易见,针对复杂条件过滤的场景,ClickHouse对多条件筛选流程做出优化,扫描的数据量更小,性能也较ES而言更高效。
如何基于ClickHouse搭建人群圈选系统
对比选型完成后,接下来讲解如何基于ClickHouse搭建人群圈选系统,回顾文章开头的业务描述和上一部分的典型sql(“SELECT user_id FROM whatever_table WHERE city_level = '一线城市' AND gender = '男性' AND is_like_sports = '是';”),再次总结人群圈选业务对数据库能力的要求如下:
- 具备高效的批量数据导入性能。
- 具备处理频繁,实时update的能力。
- 具备加列/减列的DDL能力。
- 可以指定任意列为过滤条件的高效查询能力。
面对以上需求,ClickHouse如何使用才能在人群圈选场景下物尽其用,扬长避短?
1. insert代替update
首先要解决的是ClickHouse的异步update机制。ClickHouse对update的执行是低效的,ClickHouse内核中的MergeTree存储一旦生成一个Data Part,这个Data Part就不可再更改了。所以从MergeTree存储内核层面,ClickHouse就不擅长做数据更新删除操作。ClickHouse的语法把Update操作也加入到了Alter Table的范畴中,它并不支持裸的Update操作。
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr;注:左右滑动阅览
当用户执行一个如上的Update操作获得返回时,ClickHouse内核其实只做了两件事情:
- 检查Update操作是否合法;
- 保存Update命令到存储文件中,唤醒一个异步处理merge和mutation的工作线程;异步线程的工作流程极其复杂,总结其精髓描述如下:先查找到需要update的数据所在datapart,之后对整个datapart做扫描,更新需要变更的数据,然后再将数据重新落盘生成新的datapart,最后用新的datapart做替代并remove掉过期的datapart。
这就是ClickHouse对update指令的执行过程,可以看出,频繁的update指令对于ClickHouse来说将是灾难性的。
因此,我们使用insert语句代替update语句。当需要对某一指定user更新标签时,就重新插入一条该user的数据,如对表中07号用户进行数据更新:

最终,每个user可能都存在多条记录。针对人群圈选场景,同一user错乱冗余的信息显然对查询结果产生误导,无法满足精准圈选的需求。接下来讲解如何使用ClickHouse进行主键去重,即同一user,然后insert进来的数据覆盖掉已有的数据,实现update的效果。
2. 选用AggregatingMergeTree表引擎
MergeTree是ClickHouse中最重要,最核心的存储内核,MergeTree思想上与LSM-Tree相似,其实现原理复杂,不在此展开,因为一篇文章也难以讲解清楚。本篇围绕人群圈选场景,着重从功能层面描述如何在人群圈选场景下使用MergeTree的变种AggregatingMergeTree以及使用AggregatingMergeTree可实现的数据聚合效果。AggregatingMergeTree继承自 MergeTree,存储上和基础的MergeTree其实没有任何差异,而是在数据Merge的过程中加入了“额外的合并逻辑”, AggregatingMergeTree 会将相同主键的所有行(在一个数据片段内)替换为单个存储一系列聚合函数状态的行。以文章开头部分的表结构为例,使用AggregatingMergeTree表引擎的建表语句如下:
CREATE TABLE IF NOT EXISTS whatever_table ON CLUSTER default
(
user_id UInt64,
city_level SimpleAggregateFunction(anyLast, Nullable(Enum('一线城市' = 0, '二线城市' = 1, '三线城市' = 2, '四线城市' = 3))),
gender SimpleAggregateFunction(anyLast, Nullable(Enum('女' = 0, '男' = 1))),
interest_sports SimpleAggregateFunction(anyLast, Nullable(Enum('否' = 0, '是' = 1))),
reg_date SimpleAggregateFunction(anyLast, Datetime),
comment_like_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),
last30d_share_cnt SimpleAggregateFunction(anyLast, Nullable(UInt32)),
user_like_consume_trend_type SimpleAggregateFunction(anyLast, Nullable(String)),
province SimpleAggregateFunction(anyLast, Nullable(String)),
last_access_version SimpleAggregateFunction(anyLast, Nullable(String)),
others SimpleAggregateFunction(anyLast,Array(String))
)ENGINE = AggregatingMergeTree() partition by toYYYYMMDD(reg_date) ORDER BY user_id;注:左右滑动阅览
就以上建标语句展开分析,AggregatingMergeTree会将除主键(user)外的其余列,配合anyLast函数,替换每行数据为一种预聚合状态。其中anyLast聚合函数声明聚合策略为保留最后一次的更新数据。
3. 数据一致性保证
上一部分讲述了如何针对人群圈选场景选择表引擎和聚合函数,但是AggregatingMergeTree并不能保证任何时候的查询都是聚合过后的结果,并且也没有提供标志位用于查询数据的聚合状态与进度。因此,为了确保数据在查询前处于已聚合的状态,还需手动下发optimize指令强制聚合过程的执行。同时方便起见,可自行配置周期性optimize指令的下发。例如每10分钟执行一次optimize指令。optimize的执行周期可在业务的实时性需求与计算资源之间做权衡。如数据量过大,optimize生效慢,可按partition级别并行下发做优化。optimize生效后即可实现去重逻辑。

Demo
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java