
Dubbo 3.0 前瞻系列:服务发现支持百万集群,带来可伸缩微服务架构
摘要
本文主要围绕下一代微服务框架 Dubbo 3.0 在地址推送链路的性能测试展开,也是在性能层面对 Dubbo 3.0 在阿里落地过程中的一个阶段性总结,本轮测试了 Dubbo2 接口级地址发现、Dubbo3 接口级地址发现、Dubbo3 应用级地址发现。压测数据表明,在百万实例地址的压测场景下:
- 基于接口级地址发现模型,Dubbo3 与 Dubbo2 对比,有超过 50% 常驻内存下降,Full GC 间隔更是明显拉长。
- Dubbo3 新引入的应用级服务发现模型,可以进一步实现在资源占用方面的大幅下降,常驻内存比 Dubbo3 接口级地址进一步下降 40%,应用实例扩缩容场景增量内存分配基本为零,相同周期内(1 小时) Full GC 减少为 2 次。
Dubbo 3.0 作为未来支撑业务系统的核心中间件,其自身对资源占用率以及稳定性的提升对业务系统毫无疑问将带来很大的帮助。
背景介绍
1. 下一代服务框架 Dubbo 3.0 简介
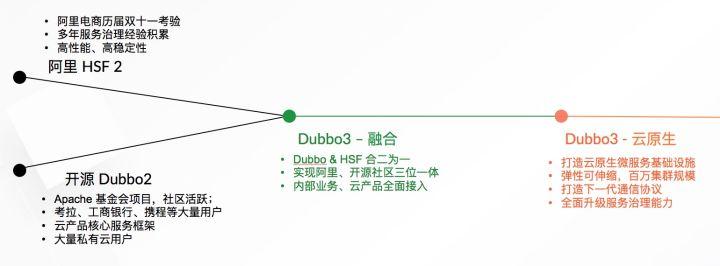
一句话概括 Dubbo 3.0:它是 HSF & 开源 Dubbo 后的融合产品,在兼容两款框架的基础上做了全面的云原生架构升级,它将成为未来面向阿里内部与开源社区的主推产品。
Dubbo 3.0 诞生的大背景是阿里巴巴在推动的全站业务上云,这为我们中间件产品全面拥抱云上业务,提供内部、开源一致的产品提出了要求也提供了契机,让中间件产品有望彻底摆脱自研体系、开源体系多线作战的局面,有利于实现价值最大化的局面。一方面阿里电商系统大规模实践的经验可以输出到社区,另一方面社区优秀的开发者也能参与到项目贡献中。以服务框架为例,HSF 和 Dubbo 都是非常成功的产品:HSF 在内部支撑历届双十一,性能优异且久经考验;而在开源侧,Dubbo 坐稳国内第一开源服务框架宝座,用户群体非常广泛。
同时维护两款高度同质化的产品,对研发效率、业务成本、产品质量与稳定性都是非常大的考验。举例来说,首先,Dubbo 与 HSF 体系的互通是一个非常大的障碍,在阿里内部的一些生态公司如考拉、饿了么等都在使用 Dubbo 技术栈的情况下,要实现顺利平滑的与 HSF 的互调互通一直以来都是一个非常大的障碍;其次,产品不兼容导致社区输出成本过高、质量验收等成本也随之增长,内部业务积累的服务化经验与成果无法直接赋能社区,二次改造适配 Dubbo 后功能性、稳定性验收都要重新投入验证。为彻底解决以上问题,结合上文提到的阿里集团业务整体上云、开源以及云产品输出战略,我们制定了全面发展 Dubbo 3.0 的计划。
2. Dubbo 不同版本在地址推送链路上的性能压测与对比
下图是服务框架的基本工作原理,橙色路径即为我们此次重点压测的地址推送链路,我们重点关注在百万地址实例推送的情况下,Dubbo 不同版本 Consumer 间的差异,尤其是 Dubbo 3.0 的实际表现。

作为对比,我们选取了以下场景进行压测:
- Dubbo2,此次压测的参考基线
- Dubbo3 接口级地址发现模型,与 Dubbo2 采用的模型相同
- Dubbo3 应用级地址发现模型,由云原生版本引入,详细讲解请参见这篇文章
压测环境与方法
- 压测数据
本次压测模拟了 220w(接口级)集群实例地址推送的场景,即单个消费端进程订阅 220w 地址。
- 压测环境
8C16G Linux,JVM 参数中堆内存设置为 10G。
- 压测方法
Consumer 进程订阅 700 个接口,ConserverServer 作为注册中心按一定比例持续模拟地址变更推送,持续时间 1 hour+,在此过程中统计 Consumer 进程以及机器的各项指标。
优化结果分析与对比
1. GC 耗时与分布
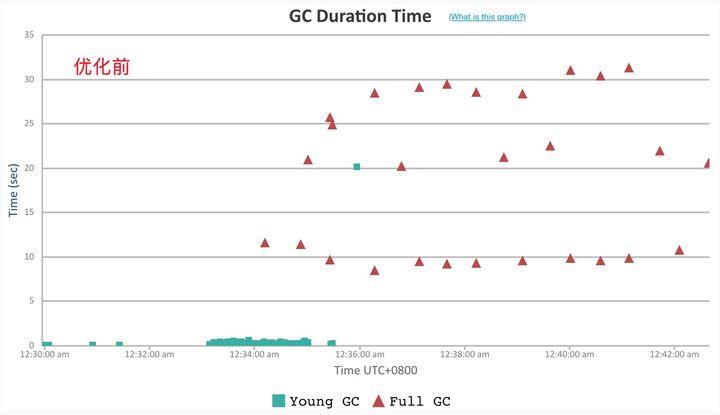
Dubbo2 接口级地址模型

Dubbo3 接口级地址模型
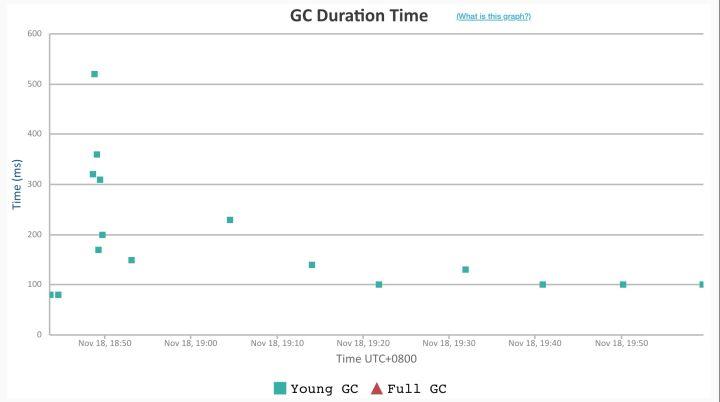
Dubbo3 应用级地址模型
2. 增量内存分配情况
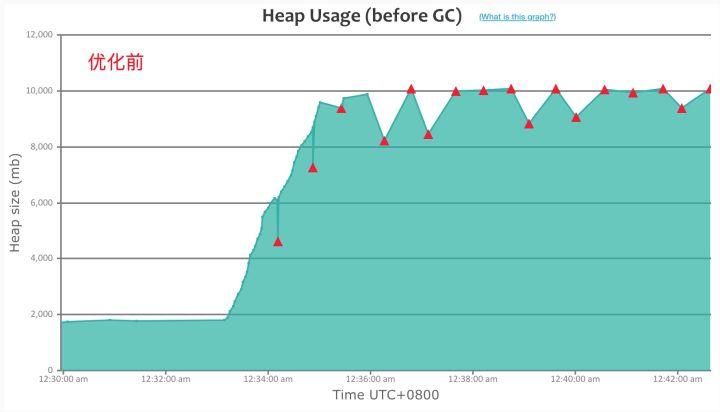
Dubbo2 接口级地址模型
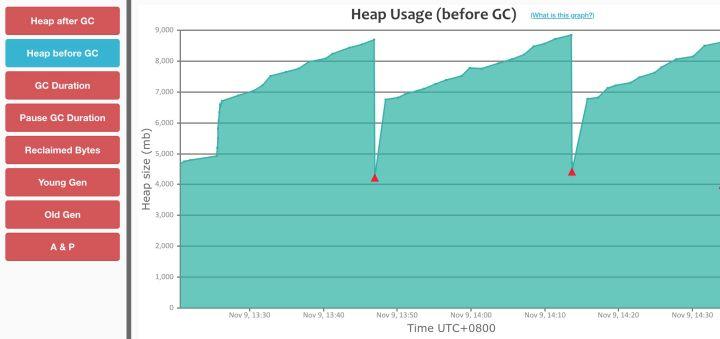
Dubbo 3.0 接口级地址模型
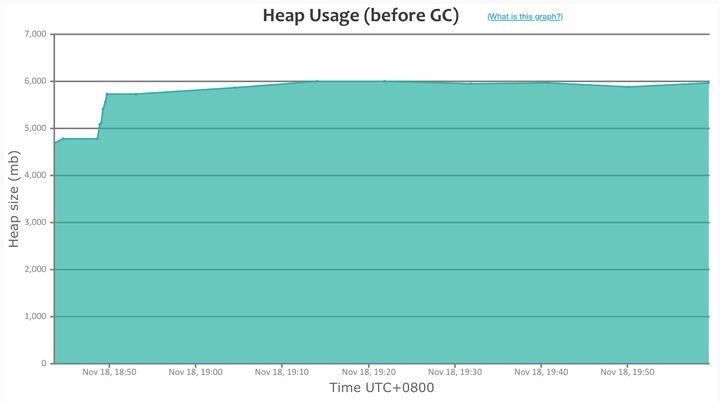
Dubbo3 应用级地址模型
3. OLD 区与常驻内存
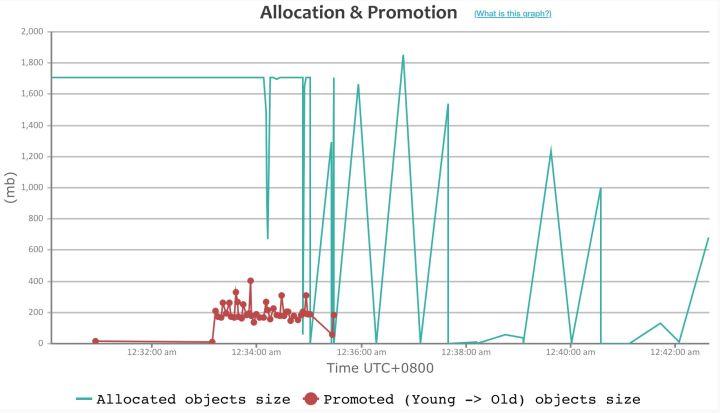
Dubbo2 接口级模型
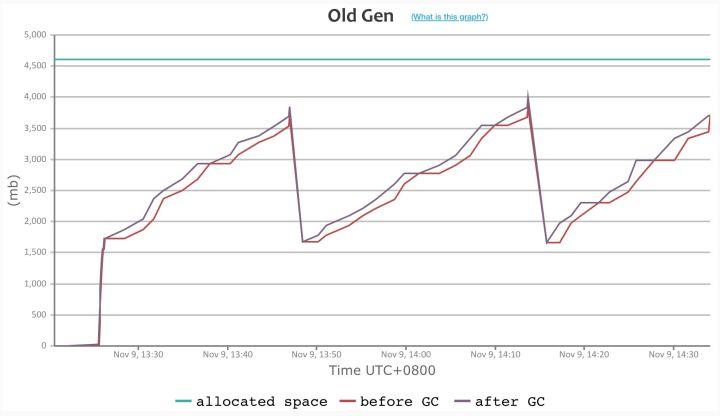
Dubbo3 接口级模型
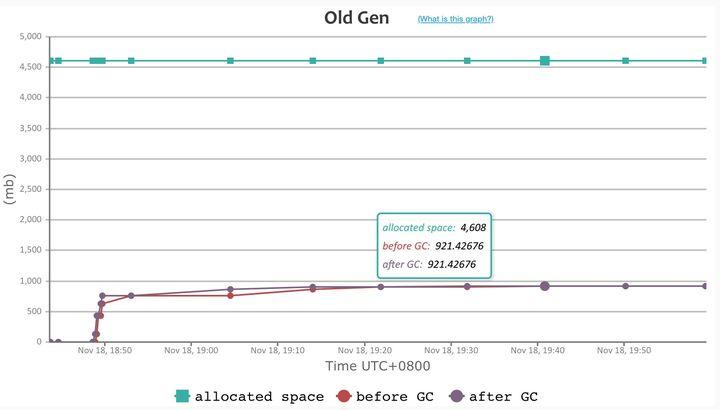
Dubbo3 应用级模型
4. Consumer 负载
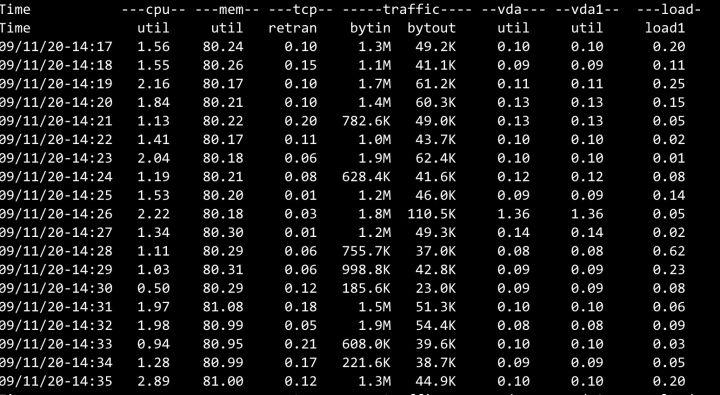
Dubbo3 接口级模型
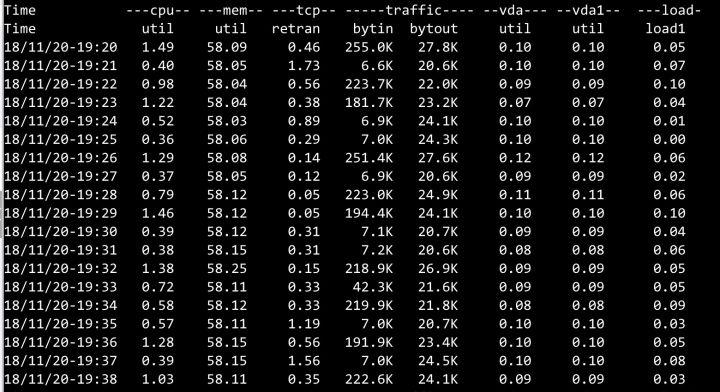
Dubbo3 应用级模型
详细对比与分析
1. Dubbo2 接口模型 VS Dubbo3 接口模型
在 200w 地址规模下,Dubbo2 很快吃满了整个堆内存空间,并且大部分都无法得到释放,而由此触发的频繁的 GC,使得整个 Dubbo 进程已无法响应,因此我们压测数据采集也没有持续很长时间。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java