
决策树之 GBDT 算法的回归部分
GBDT 是一种 Boosting 类型的决策树,即在算法产生的众多树中,前一棵树的错误决定了后一棵树的生成。
我们先从最为简单的例子开始,一起来学习 GBDT 是如何构造的,然后结合理论知识,对算法的每个细节进行剖析,力求由浅入深的掌握该算法。
我们的极简数据集由以下 3 条数据构成,使用它们来介绍 GBDT 的原理是再好不过了,假设我们用这些数据来构造一个 GBDT 模型,该模型的功能是:通过身高、颜色喜好、性别这 3 个特征来预测体重,很明显这是一个回归问题。
| 身高(米) | 颜色喜好 | 性别 | 体重(kg) |
|---|
构造 GBDT 决策树
GBDT 的第一棵树只有 1 个叶子节点,该节点为所有样本的初始预测值,且该值到所有样本间的 MSE(Mean Squared Error)是最小的。实际上,初始值就是所有样本的平均值,即 (88+76+56)/3 = 73.3,原因我们在下文会详细介绍。
接下来,根据预测值,我们算出每个样本的残差(Residual),如第一个样本的残差为:88 - 73.3 = 14.7,所有样本的残差如下:
| 身高(米) | 颜色喜好 | 性别 | 体重(kg) | 残差 |
|---|
接着,我们以残差为目标值来构建一棵决策树,构造方式同 CART 决策树,这里你可能会问到为什么要预测残差?原因我们马上就会知道,产生的树如下:

因为我们只有 3 个样本,且为了保留算法的细节,这里只用了 2 个叶子节点,但实际工作中,GBDT 的叶子节点通常在 8-32 个之间。
然后我们要处理有多个预测值的叶子节点,取它们的平均值作为该节点的输出,如下:
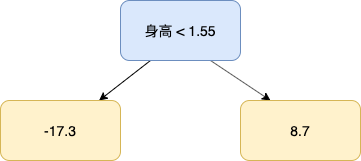
上面这棵树便是第 2 棵树,聪明的你一定发现了,第 2 棵树实际上是第 1 棵树和样本之间的误差,我们拿第 3 个样本作为例子,第一棵树对该样本的预测值为 73.3,此时它和目标值 56 之间的误差为 -17.3,把该样本输入到第 2 棵树,由于她的身高值为 1.5,小于 1.55,她将被预测为 -17.3。
既然后一棵树的输出是前一棵树的误差,那只要把所有的树都加起来,是不是就可以对前面树的错误做出补偿,从而达到逼近真实值的目的呢。这就是我们为什么以残差建树的原因。
当然树之间不会直接相加,而是在求和之前,乘上一个学习率,如 0.1,这样我们每次都可以在正确的方向上,把误差缩小一点点。Jerome Friedman 也说过这么做有助于提升模型的泛化能力(low variance)。
整个过程有点像梯度下降,这应该也是 GBDT 中 Gradient 的来历。GBDT 的预测过程如下图所示:

按此方法更新上述 3 个样本的预测值和残差,如下:
| 样本 | 目标值 | 预测值 | 残差 |
|---|
比较这两棵树的残差:
| 样本 | 树1的残差 | 树2的残差 |
|---|
可见,通过 2 棵树预测的样本比只用 1 棵树更接近目标值。接下来,我们再使用第 2 棵树的残差来构建第 3 棵树,用第 3 棵树的残差来构建第 4 棵树,如此循环下去,直到树的棵数满足预设条件,或总残差小于一定阈值为止。以上,就是 GBDT 回归树的原理。
深入 GBDT 算法细节
GBDT 从名字上给人一种不明觉厉的印象,但从上文可以看出,它的思想还是非常直观的。对于只想了解其原理的同学,至此已经足够了,想学习更多细节的同学,可以继续往下阅读。
初始化模型
该算法主要分为两个步骤,第一步为初始化模型:
F0(x)=argminγ∑i=1nL(yi,γ)
上式中,$F$ 表示模型,$F_0$ 即模型初始状态;L 为 Loss Function,n 为训练样本的个数,$y_i$ 为样本 i 的目标值,gamma 为初始化的预测值,意为找一个 gamma,能使所有样本的 Loss 最小。
前文提过,GBDT 回归算法使用 MSE 作为其 Loss,即:
L(yi,yi^)=12(yi−yi^)2
公式中 $\hat{y_i}$ 表示第 i 个样本的预测值,我们把例子中的 3 个样本带入 $F_0$ 中,得:
F0(x)=12(88−γ)2+12(76−γ)2+12(56−γ)2
要找到一个 gamma,使上式最小,因为上式是一个抛物线,那么 $d(F_0)/d\gamma=0$ 时,上式有最小值,于是:
d(F0)dγ=(γ−88)+(γ−76)+(γ−56)=0
上式化简后,你一眼就可以看出 gamma = (88+76+56)/3 = 73.3,即初始值就是所有样本的平均值,
模型迭代
算法的第二个步骤是一个循环,伪代码如下:
for m = 1 to M:
(A)
(B)
(C)
(D)其中,m 表示树的序号,M 为树的总个数(通常该值设为 100 或更多),(A) (B) (C) (D) 代表每次循环中的 4 个子步骤,我们先来看 (A)
(A) 计算
rim=−[∂L(yi,F(xi))∂F(xi)]F(x)=Fm−1(x)
我们把 $F(x_i)$ 换成 $\hat{y_i}$,该式子其实是对 Loss 求 $\hat{y_i}$ 的偏微分,该偏微分为:
∂L(yi,yi^)∂yi^=∂12(yi−yi^)2∂yi^=−(yi−yi^)
而 $F(x)=F_{m-1}(x)$ 意为使用上一个模型来计算 $\hat{y_i}$,即用 m-1 棵已生成的树来预测每一个样本,那么 $r_{im} = y_i-\hat{y_i}$ 就是上面说的计算残差这一步。
(B) 使用回归决策树来拟合残差 $r_{im}$,树的叶子节点标记为 $R_{jm}$,其中 j 表示第 j 个叶子节点,m 表示第 m 棵树。该步骤的细节如果不清楚可以查看 CART 回归树一文。
(C) 对每个叶子节点,计算
γjm=argminγ∑xi∈RijL(yi,Fm−1(xi)+γ)
上面式子虽然较为复杂,但它和初始化步骤中的式子的目的是一样的,即在每个叶子节点中,找到一个输出值 gamma,使得整个叶子节点的 Loss 最小。
$\gamma_{jm}$ 为第 m 棵树中,第 j 个叶子节点的输出,$\sum_{x_i \in R_{ij}}L$ 表示在第 j 个叶子节点中所有样本的 Loss,如下面的树中,左边叶子节点上有 1 个样本,而右边叶子节点内有 2 个样本,我们希望根据这些样本来求得对应叶子的唯一输出,而 Loss 最小化就是解决之道。
在 Loss 函数中,第 2 个参数 $F_{m-1}(x_i) + \gamma$ 是模型对样本 i 的预测,再加上 $\gamma$,对于只有 1 个样本的叶子节点来说,$\gamma$ 就是该样本残差,而对于有多个样本的节点来说,$\gamma$ 为能使 Loss 最小的那个值,下面就这两种情况分别说明:
以上面这棵树为例,左边叶子节点只有 1 个样本,即样本 3,将它带入到公式中:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java