
大数据平台架构的演变
早期大数据平台架构
基于这个我们还做了一件事情。最开始大家都是跑Mysql发邮件和Excel,毕竟那时人少,业务也相对聚焦。当业务规模变大,业务方人变多,每个小部门的需求越来越分化时,我们就需要做一个可视化的数据平台。
最开始用redash+RDS+MaxCompute的流程, MaxCompute对数据进行处理,然后通过数据集层回写到RDS,再通过RDS连接前端报表可视化软件去做展示。但存在的不足之处就是链路长,需要先把业务数据同步到MaxCompute,然后MaxCompute再去跑任务,跑完任务再写RDS,写到RDS再去给可视化用。整个环节长,中间链路多,数据累积多了,对RDS占用大,存储成本非常高。
于是我们开始推进到第二个阶段。使用redash工具,发现阿里云MaxCompute有一个Pyodps 的sdk能够在我们的开源工具二次开发集成Pyodps能力,就可以直接用MaxCompute里的数据,不需要去回写,这样就节省了RDS 存储空间,并且缩短我们的数据链路。当时,把很多需要回写的任务逐渐往这个方向去改造。这个改造本身解决了链路长和存储问题。但又出现了新问题,就是MaxCompute毕竟是一个文件系统,读取数据的速度不太能够秒级返回。于是我们又对MaxCompute做了深入的了解,发现 lightning 这个功能是能够符合我们预期的,它相当于在离线的系统上面又封装了一层,类似数仓DB的概念。我们所有的结果表都比较小了,都可以通过lightning 返回到报表系统。我们的报表系统通过这样的迭代,最终形成了业务数据库到MaxCompute,再通过lightning 返回到报表系统这样一个架构,将近一年的时间里,一直是这样的架构来实现数据可视化和自动化报表。
我们在初期遇到的问题,除了由电商业务本身的发展带来,另外一个原因是电商以外的业务正在逐步孵化出来。比如我们有内容社区的业务,也有商家端的业务。除了业务本身,技术架构上原来的单库支持本身存在RDS的瓶颈,不可能无限制扩张。于是,我们就开始对技术架构进行平台化,服务化的建设。反馈到数据这边的话,就是业务开发那边开始进行整个平台的分库分表。一个业务应用,就跑只有这个业务应用的实例,然后这个业务应用的实例,底层可能会有多个表。同一个业务同一个逻辑表,底下可能还会分到各个不同的事实表里,到这个阶段,我们的大数据建设面临的问题就变成了有很多的读库,并且业务变复杂了,再通过访问源表的方式进行报表加工就很低效。为了解决这两个问题我们做了两件事情。
第一,基于DataWorks 和MaxCompute本身的能力对原来的这种一键式整库归档数据仓库的方式做了调整。通过调整多个串行的数据基线,每个基线再通过每个节点运行的耗时和对资源的占用去合理的分配基线启动的时间,减少并发请求业务读库的情况。因为数量太大,如果并发去请求,会导致读库 IO打满,触发一系列的报警。通过这种方式,首先是减轻了读库的压力,其次还能节省读库成本,让读库配置不用做的特别高。
第二,业务分化,我们开始做数仓建模。在整个分库分表业务变更的过程中,引入了更多不同的数据库形式。最早是RDS数据库,都是单体Mysql。后来有些业务应用的数据规模特别大,Mysql 单机不能支持。我们就引入了DRDS、Hbase等一系列方案来解决业务上的数据存储、计算和处理的问题。对于我们的数仓来说,因为业务数据分散在不同的介质里, 所以我们的诉求是对不同来源的数据进行数据质量监控。这就应用到了DataWorks 和MaxCompute的特性,能够对数据质量进行定时监控,通过既有的触发报警的功能,提醒我们某天某个业务的数据流入是有异常的。这样我们的数仓同学就能够及时介入并解决问题。
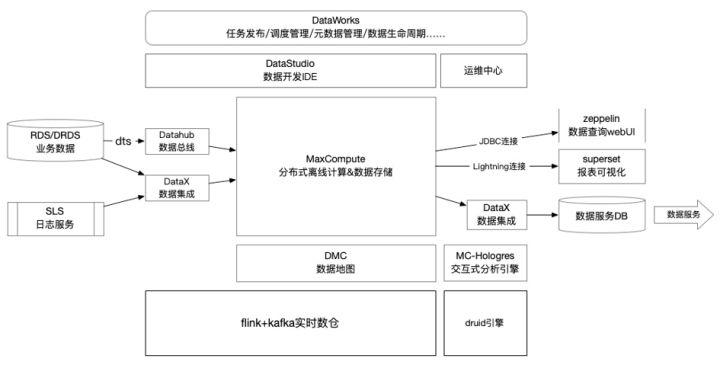
当前大数据架构
当下的情况又会跟中期不太一样,因为平台的体量又到达了更高量级。现实的问题就是不管什么样的业务,单表的数据量是非常大的。单表的数据规模大,就不能再用原来通过DataWorks数据集成方式批量导入。既然批量导入不现实,我们就开始调研其他方式来把业务DB的数据同步过来,我们也看了阿里云的产品,包括我们本身的DTS,它有数据集成的功能,也能够指向到数仓。不过用起来感受没那么完善。比如说DRDS的数据,没有办法直接打到数仓。因为有很多分库分表,我们需要DRDS的数据能够平滑的进入到数仓里。我们就对数据集成进行了迭代。先引入了一个新的集成组件DTS 加DataHub,然后再到数仓。因为DataHub可以根据我的需求进行数据归档,我可以每十五分钟就把数据归档到数仓里面。整个架构就会变成了来源是业务DB,然后DTS,然后DataHub。然后再通过DataWorks 进入MaxCompute这样一个云原生的大数据平台体系。
随着准实时和实时需求越来越多,有两个问题是亟待解决。一是原来所有数据查询,甚至准实时数据查询都依赖于MaxCompute本身的计算能力。因为有准实时需求,我们每1小时、半个小时甚至十五分钟都有大量的任务运行。但算力其实是受限的。BI同学想要去查一个表的数据,此时计算资源可能在同步其他的表或计算其他的任务,导致数据查询效率不高。这时我们发现了MC-Hologres,他能访问MaxCompute底层文件数据,且不占用MaxCompute 资源,形成一个独立的计算节点和集群,解决我们查询加速和资源隔离的问题。
另外,我们当前有很多榜单类的实时数据指标需要提供给业务方。今年下半年又上线了广告平台,商家可以在我们平台内部投广告。榜单,直播这类业务都依赖实时数据来产生业务价值。这时我们就引入了实时数仓。实时数仓建设依赖阿里云EMR,采用Flink 加Kafka,对我们的数据进行订阅消费分层。数据来源也有几种,一个是DTS 到DataHub。因为DataHub除了能归档到MaxCompute,DataHub数据也可以被Flink在这些场景里去订阅。我们搭建实时数仓时,也用了Flink on Yarn的方式,基于EMR 的Yarn,最终帮我们把实时数仓的框架搭建起来。实时数仓建好后,还有一个诉求是需要实时数据,我们需要对数据进行报表化和可视化,自动推送一系列数据给业务方。此时,我们又引入了查询引擎Druid和superset的数据可视化。因为Druid和superset天然绑定在一起的,我们的Kafka,可以直接被Druid的数据引擎消费,以此实现完整的实时的数据链路闭环,构成了我们目前的大数据平台。离线是MaxCompute+DataWorks+报表可视化。实时是Flink+Kafka+Druid+superset。
再说到未来的规划,就是引入湖仓一体的建设。这样的规划是从两方面来考虑的。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java