
基于 Apache Flink 的优化实践
首先介绍流式计算的基本概念, 然后介绍 Flink 的关键技术,最后讲讲 Flink 在快手生产实践中的一些应用,包括实时指标计算和快速 failover。
一、流式计算的介绍
流式计算主要针对 unbounded data(无界数据流)进行实时的计算,将计算结果快速的输出或者修正。
这部分将分为三个小节来介绍。第一,介绍大数据系统发展史,包括初始的批处理到现在比较成熟的流计算;第二,为大家简单对比下批处理和流处理的区别;第三,介绍流式计算里面的关键问题,这是每个优秀的流式计算引擎所必须面临的问题。
1、大数据系统发展史
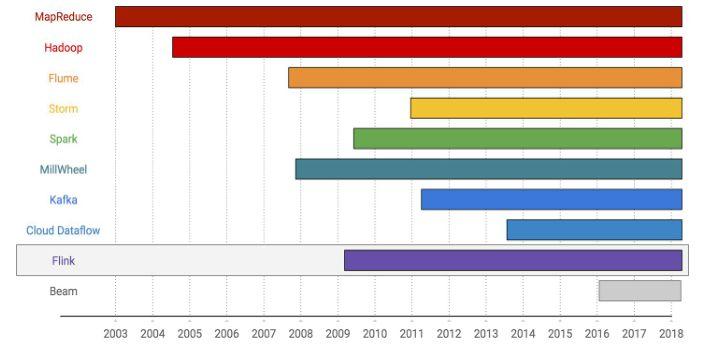
上图是 2003 年到 2018 年大数据系统的发展史,看看是怎么一步步走到流式计算的。
2003 年,Google 的 MapReduce 横空出世,通过经典的 Map&Reduce 定义和系统容错等保障来方便处理各种大数据。很快就到了 Hadoop,被认为是开源版的 MapReduce, 带动了整个apache开源社区的繁荣。再往后是谷歌的 Flume,通过算子连接等 pipeline 的方式解决了多个 MapReduce 作业连接处理低效的问题。
流式系统的开始以 Storm 来介绍。Storm 在2011年出现, 具备延时短、性能高等特性, 在当时颇受喜爱。但是 Storm 没有提供系统级别的 failover 机制,无法保障数据一致性。那时的流式计算引擎是不精确的,lamda 架构组装了流处理的实时性和批处理的准确性,曾经风靡一时,后来因为难以维护也逐渐没落。
接下来出现的是 Spark Streaming,可以说是第一个生产级别的流式计算引擎。Spark Streaming 早期的实现基于成熟的批处理,通过 mini batch 来实现流计算,在 failover 时能够保障数据的一致性。
Google 在流式计算方面有很多探索,包括 MillWheel、Cloud Dataflow、Beam,提出了很多流式计算的理念,对其他的流式计算引擎影响很大。
再来看 Kafka。Kafka 并非流式计算引擎,但是对流式计算影响特别大。Kafka 基于log 机制、通过 partition 来保存实时数据,同时也能存储很长时间的历史数据。流式计算引擎可以无缝地与kafka进行对接,一旦出现 Failover,可以利用 Kafka 进行数据回溯,保证数据不丢失。另外,Kafka 对 table 和 stream 的探索特别多,对流式计算影响巨大。
Flink 的出现也比较久,一直到 2016 年左右才火起来的。Flink 借鉴了很多 Google 的流式计算概念,使得它在市场上特别具有竞争力。后面我会详细介绍 Flink 的一些特点。
2、批处理与流计算的区别
批处理和流计算有什么样的区别,这是很多同学有疑问的地方。我们知道 MapReduce 是一个批处理引擎,Flink 是一个流处理引擎。我们从四个方面来进行一下对比:
1)使用场景
MapReduce 是大批量文件处理,这些文件都是 bounded data,也就是说你知道这个文件什么时候会结束。相比而言,Flink 处理的是实时的 unbounded data,数据源源不断,可能永远都不会结束,这就给数据完备性和 failover 带来了很大的挑战。

2)容错
MapReduce 的容错手段包括数据落盘、重复读取、最终结果可见等。文件落盘可以有效保存中间结果,一旦 task 挂掉重启就可以直接读取磁盘数据,只有作业成功运行完了,最终结果才对用户可见。这种设计的哲理就是你可以通过重复读取同一份数据来产生同样的结果,可以很好的处理 failover。
Flink 的容错主要通过定期快照和数据回溯。每隔一段时间,Flink就会插入一些 barrier,barrier 从 source 流动到 sink,通过 barrier 流动来控制快照的生成。快照制作完就可以保存在共享引擎里。一旦作业出现问题,就可以从上次快照进行恢复,通过数据回溯来重新消费。
3)性能
MapReduce 主要特点是高吞吐、高延时。高吞吐说明处理的数据量非常大;高延时就是前面说到的容错问题,它必须把整个作业处理完才对用户可见。
Flink 主要特点是高吞吐、低延时。在流式系统里,Flink 的吞吐是很高的。同时,它也可以做到实时处理和输出,让用户快速看到结果。
4)计算过程
MapReduce 主要通过 Map 和 reduce 来计算。Map 负责读取数据并作基本的处理, reduce 负责数据的聚合。用户可以根据这两种基本算子,组合出各种各样的计算逻辑。
Flink 为用户提供了 pipeline 的 API 和批流统一的 SQL。通过 pipeline 的 API, 用户可以方便地组合各种算子构建复杂的应用;Flink SQL 是一个更高层的 API 抽象,极大地降低了用户的使用门槛。
3、流式计算的关键问题
这部分主要通过四个问题给大家解答流式计算的关键问题,也是很多计算引擎需要考虑的问题。
1)What
What 是指通过什么样的算子来进行计算。主要包含三个方面的类型,element-wise 表示一对一的计算,aggregating 表示聚合操作,composite 表示多对多的计算。
2)Where
aggregating 会进行一些聚合的计算, 主要是在各种 window 里进行计算。窗口包含滑动窗口、滚动窗口、会话窗口。窗口会把无界的数据切分成有界的一个个数据块进行处理,后面我们会详细介绍这点。
3)When
When 就是什么时候触发计算。窗口里面有数据,由于输入数据是无穷无尽的,很难知道一个窗口的数据是否全部到达了。流式计算主要通过 watermark 来保障数据的完备性,通过 trigger 来决定何时触发。当接收到数值为 X 的 Watermark 时,可以认为所有时间戳小于等于X的事件全部到达了。一旦 watermark 跨过窗口结束时间,就可以通过 trigger 来触发计算并输出结果。
4)How
How 主要指我们如何重新定义同一窗口的多次触发结果。前面也说了 trigger 是用来触发窗口的, 一个窗口可能会被触发多次,比如1分钟的窗口每 10 秒触发计算一次。处理方式主要包含三种:
- Discarding,丢弃之前的状态重新计算。这种方式每次的触发结果都是互不关联的,多次触发结果的组合反映了全部的窗口内容,下游一般会再次聚合;
- Accumulating,这个就是一个聚合的状态,比如说第二次触发的时候是在第一次的结果上进行计算的,下游只需要保存最新的结果即可;
- Accumulating 和 retracting,这个主要在 Accumulating 的基础上加了一个 retracting,retracting 的意思就是撤销。窗口再次触发时,会告诉下游撤销上一次的计算结果,并告知最新的结果。Flink SQL 的聚合就使用了这种 retract的模式。
二、Flink 关键技术
1、Flink 简介
Flink 是一款分布式计算引擎, 既可以进行流式计算,也可以进行批处理。下图是官网对 Flink 的介绍:
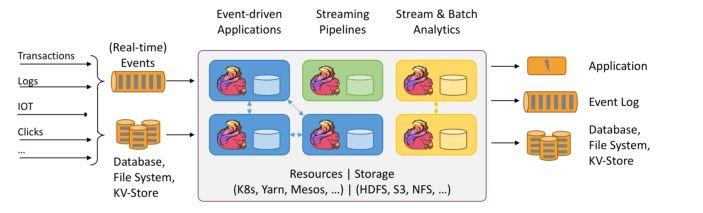
Flink 可以运行在 k8s、yarn、mesos 等资源调度平台上,依赖 hdfs 等文件系统,输入包含事件和各种其他数据,经过 Flink 引擎计算后再输出到其他中间件或者数据库等。
Flink 有两个核心概念:
- State:Flink 可以处理有状态的数据,通过自身的 state 机制来保障作业failover时数据不丢失;
- Event Time:允许用户按照事件时间来处理数据,通过 watermark 来推动时间前进,这个后面还会详细介绍。主要是系统的时间和事件的时间。
Flink 主要通过上面两个核心技术来保证 exactly-once, 比如说作业 Failover 的时候状态不丢失,就好像没发生故障一样。
2、快照机制
Flink 的快照机制主要是为了保障作业 failover 时不丢失状态。Flink 提供了一种轻量级的快照机制,不需要停止作业就可以帮助用户持久化内存中的状态数据。

上图中的 markers(与 barrier 语义相同)通过流动来触发快照的制作,每一个编号都代表了一次快照,比如编号为 n 的 markers 从最上游流动到最下游就代表了一次快照的制作过程。简述如下:
- 系统发送编号为 n 的 markers 到最上游的算子,markers 随着数据往下游流动;
- 当下游算子收到 marker 后,就开始将自身的状态保存到共享存储中;
- 当所有最下游的算子接收到 marker 并完成算子快照后,本次作业的快照制作完成。
一旦作业失败,重启时就可以从快照恢复。
下面为一个简单的 demo 说明(barrier 等同于 marker)。
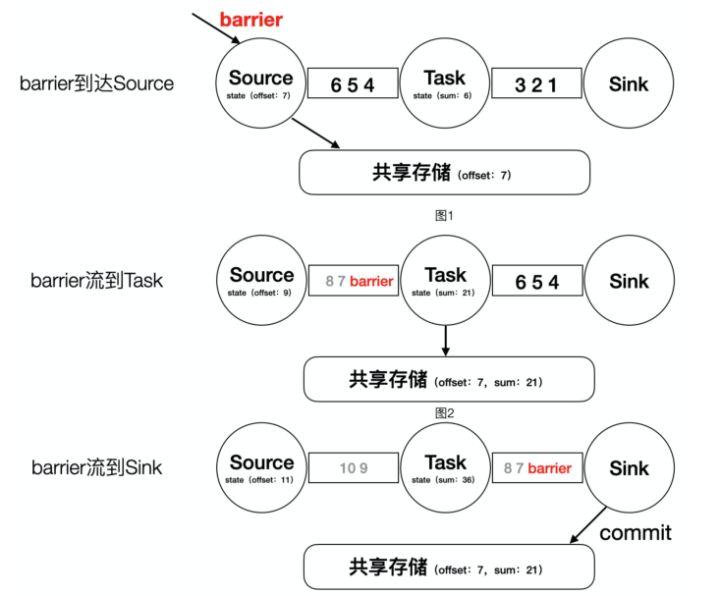
- barrier 到达 Source,将状态 offset=7 存储到共享存储;
- barrier 到达 Task,将状态 sum=21 存储到共享存储;
- barrier 到达 Sink,commit 本次快照,标志着快照的成功制作。
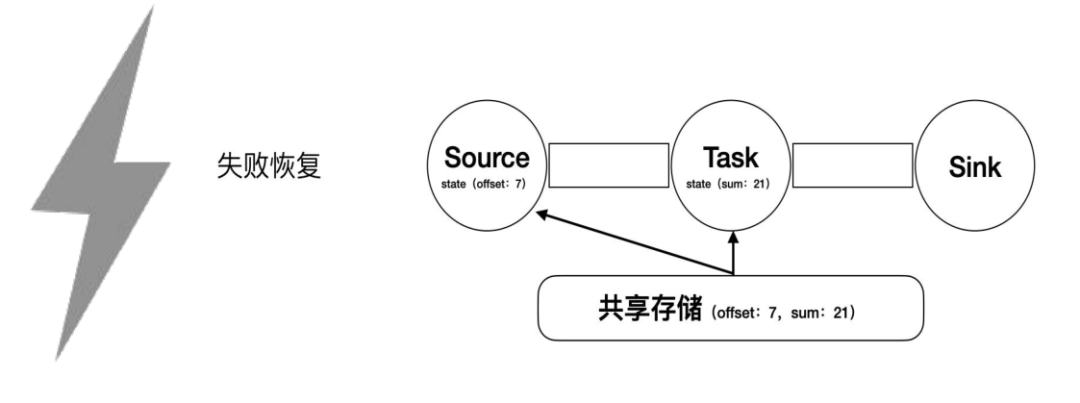
这时候突然间作业也挂掉, 重启时 Flink 会通过快照恢复各个状态。Source 会将自身的 offset 置为 7,Task 会将自身的 sum 置为 21。现在我们可以认为 1、2、3、4、5、6 这 6 个数字的加和结果并没有丢失。这个时候,offset 从 7 开始消费,跟作业失败前完全对接了起来,确保了 exactly-once。
3、事件时间
时间类型分为两种:
- Event time(事件时间),指事件发生的时间,比如采集数据时的时间;
- Processing time(系统时间),指系统的时间,比如处理数据时的时间。
如果你对数据的准确性要求比较高的话,采用 Event time 能保障 exactly-once。Processing Time 一般用于实时消费、精准性要求略低的场景,主要是因为时间生成不是 deterministic。
我们可以看下面的关系图, X 轴是 Event time,Y 轴是 Processing time。理想情况下 Event time 和 Processing time 是相同的,就是说只要有一个事件发生,就可以立刻处理。但是实际场景中,事件发生后往往会经过一定延时才会被处理,这样就会导致我们系统的时间往往会滞后于事件时间。这里它们两个的差 Processing-time lag 表示我们处理事件的延时。

事件时间常用在窗口中,使用 watermark 来确保数据完备性,比如说 watermarker 值大于 window 末尾时间时,我们就可以认为 window 窗口所有数据都已经到达了,就可以触发计算了。
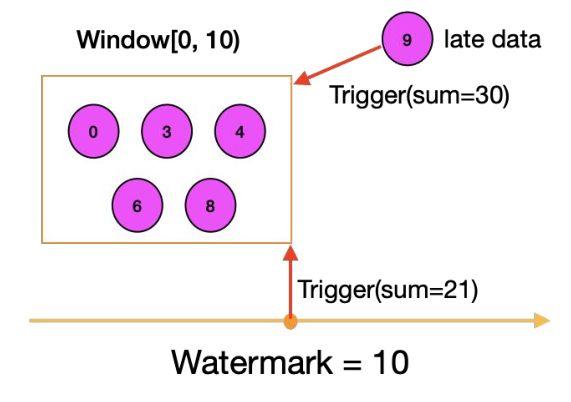
比如上面 [0-10] 的窗口,现在 watermark 走到了 10,已经到达了窗口的结束,触发计算 SUM=21。如果要是想对迟到的数据再进行触发,可以再定义一下后面 late data 的触发,比如说后面来了个 9,我们的 SUM 就等于 30。
4、窗口机制
窗口机制就是把无界的数据分成数据块来进行计算,主要有三种窗口。
- 滚动窗口:固定大小的窗口,相邻窗口没有交集;
- 滑动窗口:每个窗口的大小是一样的,但是两个窗口之间会有重合;
- 会话窗口:根据活跃时间聚合而成的窗口, 比如活跃时间超过3分钟新起一个窗口。窗口之间留有一定的间隔。

窗口会自动管理状态和触发计算,Flink 提供了丰富的窗口函数来进行计算。主要包括以下两种:
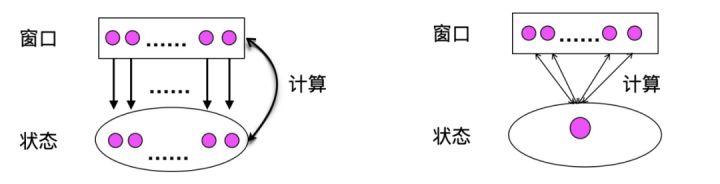
- ProcessWindowFunction,全量计算会把所有数据缓存到状态里,一直到窗口结束时统一计算。相对来说,状态会比较大,计算效率也会低一些;
- AggregateFunction,增量计算就是来一条数据就算一条,可能我们的状态就会特别的小,计算效率也会比 ProcessWindowFunction 高很多,但是如果状态存储在磁盘频繁访问状态可能会影响性能。
三、快手 Flink 实践
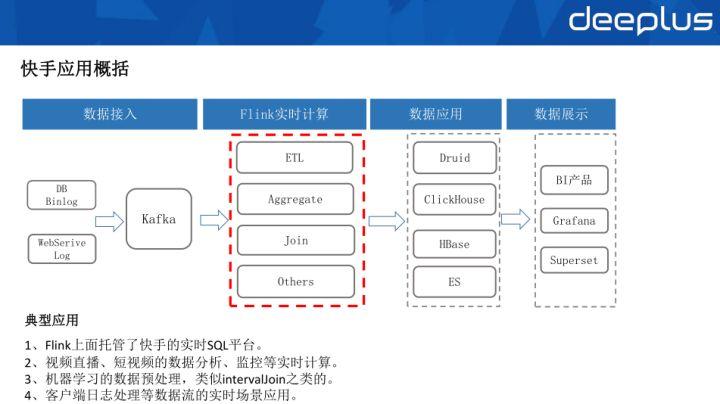
1、应用概括
快手应用概括主要是分为数据接入、Flink 实时计算、数据应用、数据展示四个部分。各层各司其职、衔接流畅,为用户提供一体化的数据服务流程。
2、实时指标计算
常见的实时指标计算包括 uv、pv 和 sum。这其中 uv 的计算最为复杂也最为经典。下面我将重点介绍 uv。
uv 指的是不同用户的个数,我们这边计算的就是不同 deviceld 的个数,主要的挑战来自三方面:
- 用户数多,数据量大。活动期间的 QPS 经常在千万级别,实际计算起来特别复杂;
- 实时性要求高,通常为几秒到分钟结果的输出;
- 稳定性要求高,比如说我们在做春晚活动时候要求故障时间需要低于2%或更少。
针对各种各样的 uv 计算,我们提供了一套成熟的计算流程。主要包含了三方面:
- 字典方案:将 string 类型的 deviceld 转成 long 类型,方便后续的 uv 计算;
- 倾斜处理:比如某些大 V 会导致数据严重倾斜,这时候就需要打散处理;
- 增量计算:比如计算 1 天的 uv,每分钟输出一次结果。
字典方案需要确保任何两个不同的 deviceId 不能映射到相同的 long 类型数字上。快手内部主要使用过以下三种方案:

- HBase, 基于 partition 分区建立 deviceld 到 id 的映射, 通过缓存和批量访问来加速;
- Redis, 这种方案严格来说不属于字典,主要通过 key-value 来判断数据是否首次出现,基于首次数据来计算 uv,这样就会把 pv 和 uv 的计算进行统一;
- 最后就是一个 Flink 内部自建的全局字典实现 deviceld 到 id 的转换,之后计算UV。
这三种方案里面,前两种属于外部存储的字典方案,优点是可以做到多个作业共享 1 份数据, 缺点是外部访问慢而且不太稳定。最后一种 Flink 字典方案基于 state,不依赖外部存储, 性能高但是无法多作业共享。
接下来我们重点介绍基于Flink自身的字典方案,下图主要是建立一个 deviceld 到 id 的映射:
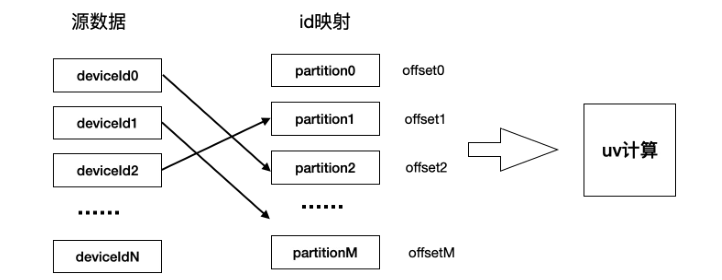
主要分成三步走:
1)建立 Partition 分区, 指定一个比较大的 Partition 分区个数,该个数比较大并且不会变,根据 deviceld 的哈希值将其映射到指定 partition。
2)建立 id 映射。每个 Partition 都有自己负责的 id 区间,确保 Partition 之间的long 类型的 id 不重复, partition 内部通过自增 id 来确保每个 deviceId 对应一个 id。
3)使用 keyed state 保存 id 映射。这样我们的作业出现并发的大改变时,可以方便的 rescale,不需要做其他的操作。
除了 id 转换,后面就是一个实时指标计算的常见问题,就是数据倾斜。业界常见的解决数据倾斜处理方案主要是两种:
- 打散再聚合:先将倾斜的数据打散计算,然后再聚合计算结果;
- Local-aggregate:先在本地计算预聚合,这样会大大减少下游的数据压力。
二者的本质是一样的,都是先预聚合再汇总,从而避免单点性能问题。
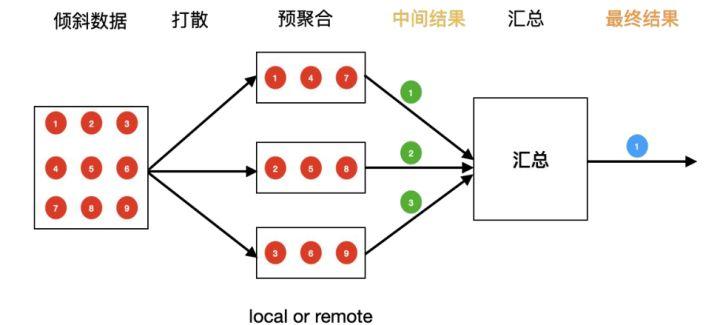
上图为计算最小值的热点问题,红色数据为热点数据。如果直接将它们打到同一个分区,会出现性能问题。为了解决倾斜问题,我们通过hash策略将数据分成小的 partition 来计算,如上图的预计算,最后再将中间结果汇总计算。
当一切就绪后,我们来做增量的 UV 计算,比如计算 1 天 uv,每分钟输出 1 次结果。计算方式既可以采用 API,也可以采用 SQL。
针对 API,我们选择了 global state+bitmap 的组合,既严格遵循了 Event Time 又减少了 state 大小:
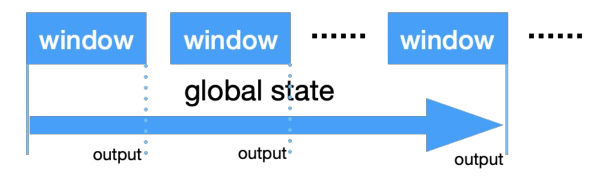
下面为计算流程(需要注意时区问题):
定义跟触发间隔一样大小的 window(比如 1 分钟);
- Global state 用来保存跨窗口的状态,我们采用 bitmap 来存储状态;
- 每隔一个 window 触发一次,输出起始至今的 UV;
- 当前作用域(比如 1 天)结束,清空状态重新开始。
针对 SQL,增量计算支持的还不是那么完善,但是可以利用 early-fire 的参数来提前触发窗口。
配置如下:
table.exec.emit.early-fire.enabled: truetable.exec.emit.early-fire.delay:60 s
early-fire.delay 就是每分钟输出一次结果的意思。
SQL 如下:
SELECT TUMBLE_ROWTIME(eventTime, interval ‘1’ day) AS rowtime, dimension, count(distinct id) as uv FROM person GROUP BY TUMBLE(eventTime, interval '1' day), dimension
如果遇到倾斜,可以参考上一步来处理。
3、快速 failover
最后看下我们部门最近发力的一个方向,如何快速 failover。
Flink 作业都是 long-running 的在线作业,很多对可用性的要求特别高,尤其是跟公司核心业务相关的作业,SLA 要求 4 个 9 甚至更高。当作业遇到故障时,如何快速恢复对我们来说是一个巨大的挑战。
下面分三个方面来展开:
- Flink 当前已有的快速恢复方案;
- 基于 container 宕掉的快速恢复;
- 基于机器宕掉的快速恢复。
1)Flink 当前已有的快速恢复方案
Flink 当前已有的快速恢复方案主要包括以下两种:
- region failover。如果流式作业的 DAG 包含多个子图或者 pipeline,那么 task 失败时只会影响其所属的子图或者 pipeline ,而不用整个 DAG 都重新启动;
- local recovery。在 Flink 将快照同步到共享存储的同时,在本地磁盘也保存一份快照。作业失败恢复时,可以调度到上次部署的位置,并从 local disk 进行快照恢复。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java