
基于腾讯云Elasticsearch搭建QQ邮箱全文检索
随着用户邮件数量越来越多,邮件搜索已是邮箱的基本功能。QQ 邮箱于 2008 年推出的自研搜索引擎面临着存储机器逐渐老化,存储机型面临淘汰的境况。因此,需要搭建一套新的全文检索服务,迁移存储数据。本文将介绍 QQ 邮箱全文检索的架构、实现细节与搜索调优。
一、重构背景
QQ 邮箱的全文检索服务于2008年开始提供,使用中文分词算法和倒排索引结构实现自研搜索引擎。设计有二级索引,热数据存放于正排索引支持实时检索,冷数据存放于倒排索引支持分词搜索。在使用旧全文检索过程中存在以下问题:
- 机器老化、磁盘损坏导致丢数据;
- 业务逻辑复杂,代码庞大晦涩,难以维护;
- 使用定制化kv存储,已无人维护;
- 不存储原文,无法实现原生高亮;
- 未索引超大附件名。
旧的全文检索在使用中长期存在上述问题,恰逢旧的存储机器裁撤,借此机会重构 QQ 邮箱的全文检索后台服务。
二、新全文检索架构
Elasticsearch 是一个分布式的搜索引擎,支持存储、搜索和数据分析,有良好的扩展性、稳定性和可维护性,在搜索引擎排名中蝉联第一。
ES 的底层存储引擎是 Lucene,ES 在 Lucene 的基础上提供分布式集群的能力以确保可靠性、提供 REST API 以确保可用性。
Lucene 底层使用倒排索引提供搜索能力,使用 LSM tree 合并处理 Doc 加快索引速度,使用 Translog 持久化数据,实现方式与邮箱旧全文检索相似。
为了快速搭建出一套新全文检索后台并完成迁移,QQ 邮箱全文检索的重构选择 Elasticsearch 作为搜索引擎,同时响应自研上云号召,一步到位直接使用腾讯云 ES 构建搜索服务。
1. 邮件搜索特点
邮箱的发信和收信行为都会触发写全文检索,而搜索行为会触发读全文检索,呈现明显的写多读少。
区别于互联网搜索,邮件检索有自己的特点:

2. 全文检索后台架构
邮箱全文检索模块 fullsearch 的整体架构如上图所示,fullsearch 承担的功能是收录用户的邮件、记事等内容并提供查询。fullsearch 模块下游直接对接腾讯云 ES,内网通过 http 请求访问 ES 的 REST API。模块上游的请求分为两类:
(1)增、删、改
入信、发信、删信等行为会触发更改 ES 内的 doc,入信、发信对实时性要求一般但可靠性要求较高,而删信行为不要求实时性。这类操作都可以异步处理。
(2)查
搜索行为包括邮件普通搜索、邮件高级搜索,将来还有邮箱内全品类搜索。这类搜索行为要求较高的实时性和准确性,需要同步处理。
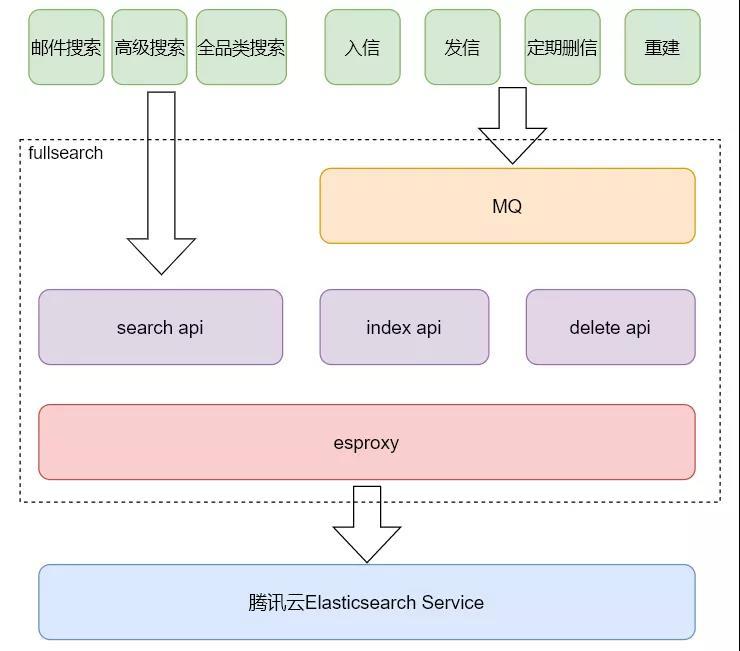
fullsearch 内部设计如下:
- 使用 HTTP 协议与腾讯云ES通讯,传输 json 格式数据,邮箱后台广泛使用的 protobuf 数据结构能轻松转换为 json 格式;
- esproxy 使用 curl 连接池代理邮箱后台与ES的http连接,以提升网络连接速度;
- 使用 MQ 对增、删、改这类异步请求进行削峰,以保护下游 ES。同时利用 MQ 延时和重试功能,确保请求被成功处理;
- 对搜索结果进行过滤,避免搜索结果列表出现已删除邮件。在 ES 故障时,提供另一种搜索机制兜底。
三、新全文检索的实现细节
利用邮箱后台现有的组件库,如 svrkit rpc 框架、protobuf 数据结构、自研 MQ 等能快速将上述 fullsearch 模块搭建出来,但实现过程中遇到以下几个实际问题。
1. 号段索引 or uin索引
第一个要解决的是如何分配索引的问题。最初为了实现 ES 内的数据按 uin 进行隔离,每个 uin 建一个索引。
随着用户数量上来后,ES 提示分片数量达到上限,不可创建新的索引。这是因为 ES 集群对每个索引都会维护映射和状态信息,索引和分片数量过多会导致占用大量内存。详情可参考文档。
ES 官方建议将结构相同的数据放入一个索引,既然不能按 uin 建索引,那可不可以建一个索引容纳全量用户的数据呢?答案是否定的,分片数量过多也会对内存有很大的开销。
ES 的索引概念相当于 MySql 的表概念,一个索引对应一张表,类似 MySql 可以分表,ES 也可以拆分索引。
所以一个折中的方案是(如下图),按 uin 尾号号段(如果号段数据不均匀可以按 uin 哈希)分别建立若干个索引,每个索引内设置少量分片。随着邮件数量上涨,每个索引内的数据量也将上涨,将来可以通过扩展分片数量解决。
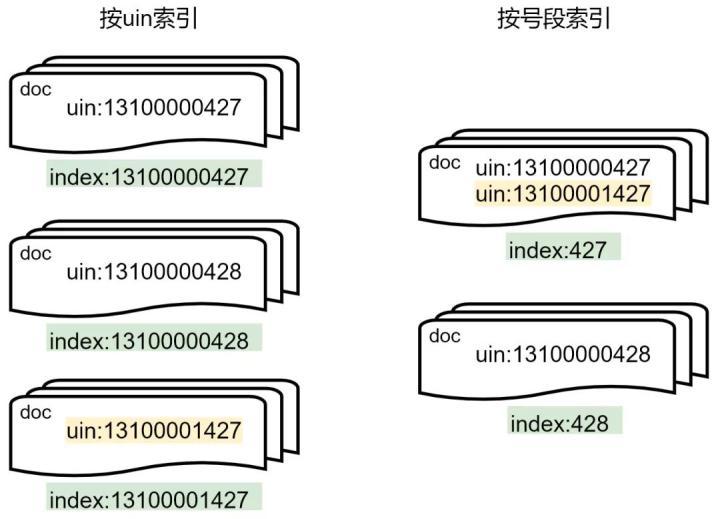
所有搜索操作都带上号段索引,如"428/_search",可达到相对较快的搜索速度,但无法达到按 uin 建索引的搜索速度,因为搜索速度取决于每个索引内的 doc 数量。有没有办法让号段索引的搜索速度媲美 uin 索引的速度呢?
ES 官方提供了一个索引设置选项"index.sort",该选项可以使索引内的 doc 在存储时按照某几个字段的升序或降序进行顺序存储。如果设置 doc 按 uin 顺序存储,在搜索时就能将搜索范围缩小到属于某个 uin 的 doc 存储范围,这将显著提升搜索速度。
与此同时会带来一个负面影响,在增、删、改 doc 时,由于要重排 doc 顺序,这些操作的速度将下降 1/3,需要根据业务特点做权衡。
值得注意的是,这个选项只能在新建索引的时候开启,开启后不可改变,故需要提前压测来权衡是否开启该选项。
2. 邮件正文 to ES字段
如果想让邮件内容被索引到,一般会将邮件主题、正文、附件等分别添加到 doc 的一个字段,并将该字段设置为 type:text。邮件正文被放进 ES 的 text 字段之前,需要做一些预处理,来保证将来的检索质量。
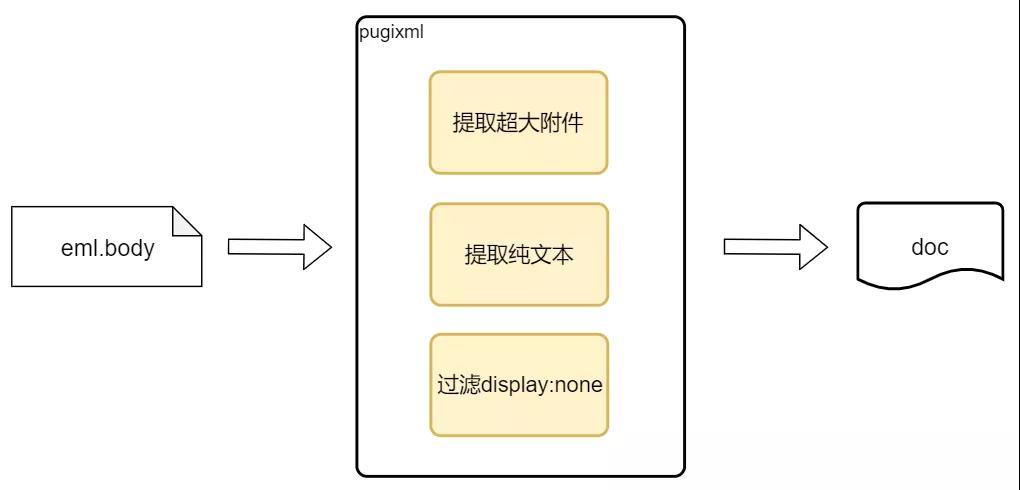
邮箱全文检索会收录邮件、记事本和在线文档的数据。如下图以邮件正文为例,邮件正文一般是一段 html,如果将 html 收录进 ES 太浪费存储空间,而且会干扰高亮的识别,所以需要提取邮件正文的纯文本。
同时,邮件的超大附件信息被放在了正文里,如果搜索超大附件名则需要去搜正文而不是搜附件,这不符合用户使用常识。
另外,有一些 html 节点内包含大量乱码或 url,属性为 display:none,比如邮箱的超大附件,这些乱码文本也是需要剔除掉的。
<span style="display:none;">:http://wx.mail.qq.com/ftn/download?func=3&k=c7991f38b1d109adf4ea5216042ca62df1e0f2a0b6a2ba26e6a261631539efd62535&key=c7991f38b1d109adf4ea4d38603464390ec0623866a2ba26e6a261631539efd62535&code=8fc8b4d9</span>要解决上述问题,可以从解析 html 节点入手:
- 提取纯文本节点并累加,即可过滤所有 html 标签;
- 识别含有超大附件的节点,并提取超大附件名;
- 过滤属性为 display:none 的节点。
此时问题就变成寻找一个符合要求的html解析器,把 htmlbody 解析为 dom 树。常见的 xml 解析器有 rapidxml、tinyxml 和 pugixml。
笔者选择的是pugixml,优点是速度快、易于使用且支持 xpath,缺点是解析较为严格、遇到不规范的 html 会抛异常。
如下图所示,笔者对 pugixml 进行了一番改造,使之增强对 html 的兼容性。在 pugixml 出现异常时,使用速度稍慢些的 ekhtml 解析器作为兜底。
3. ProtoBuf to Json
fullsearch 模块调用腾讯云 ES 的 REST API 使用json数据包进行交互,有大量的打包 json 和解析 json 的操作。而邮箱后台广泛使用的数据结构是 protobuf,这就需要完成 protobuf 到 json 的互相转换。
如果手动判断 protobuf/json 是否存在某个字段,再使用 rapidjson 或 jsoncpp 进行解包和封包,则太繁琐且容易出错。
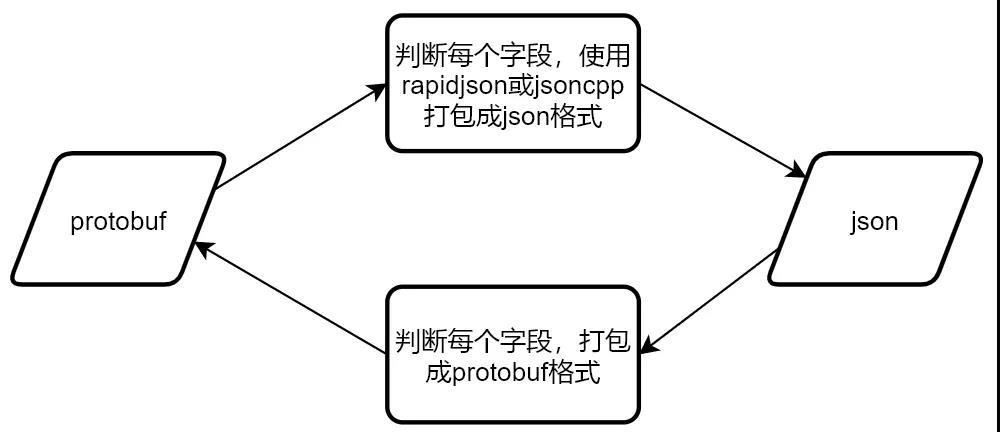
这里选择直接让 protobuf 字段与 json 字段进行映射,使用 protobuf 自带的工具 MessageToJsonString 和 JsonStringToMessage进行 protobuf 和 json 的相互转换,使用起来十分方便。

四、搜索调优
1. 调优背景
新全文检索搭建上线后测试迁移了一批邮件,收到一些关于搜索结果不精确的反馈:
- 搜出大量有关邮件,但想找的邮件不在列表第一页;
- 搜不出邮件;
- 无法通过订单号精确查找邮件。
初步分析,主要由以下几个原因造成:
- 模糊搜索结果虽能按相关度排序,但前端显示结果按时间倒序排序,导致相关度高的结果不一定排在第一页;
- 将模糊搜索替换为精确搜索后,搜索过于严格,导致搜不出邮件;
- 无法知道用户的意图是精确搜索还是模糊搜索,导致不能用一种搜索模式满足所有用户搜索意图;
- 订单号一般由字母+数组组成,分词器处理订单号时,由于默认的分词规则,会丢弃单字母或单数字,导致无法精确匹配。
下面首先详细介绍 ES 的搜索机制,然后通过案例分析对 ES 搜索做一定的优化。
2. ES搜索机制
ES 的全文搜索查询主要分为两种:match 和 match_phrase,它们的搜索机制是:
- 入信时,ES 分词器先对 doc 中 type:text 字段进行分词,默认记录下每个分词的词频和词语在原文中的位置,存在倒排索引中;
- 搜索时,对搜索关键字进行分词,根据关键字分词在倒排索引中查到每个分词的 docid 列表。如果 match(operator=or),则停止搜索并返回 docid 列表;
- 对第二步每个分词的 docid 列表求交集得到新的 docid 列表,使得列表中每个 docid 都出现所有分词。如果是 match 搜索,则停止搜索并返回 docid 列表;
- 比较第三步每个 docid 中所有分词的相对位置,是否与第一步中原文分词的相对位置相同,过滤掉相对位置不同的 docid,结束搜索。这一步是 match_phrase 才有的,且会小幅增加搜索耗时。

来看一个例子,搜索关键字"银行账单",ik_smart 分词列表为["银行", "账单"]。
- match_phrase 搜索最严格,要求"银行"、“账单”同时出现且相邻,只能匹配一篇文章;
- match(operator=or) 只要求出现"银行"、“账单”即可,能匹配所有文章;
- match(operator=and) 要求同时出现"银行"、“账单”,但对词语间隔不做要求,匹配数量介于两者之间,搜索结果精度优于 match(operator=or)。
3. 两级搜索
fullsearch 模块使用 match_phrase 处理精确搜索,使用 match(operator=and) 处理模糊搜索。
为了最大化满足不同用户对精确搜索和模糊搜索的需求,先用 match_phrase 精确搜索,搜不到内容再用 match 模糊搜索。
统计显示精确搜索搜到内容占搜索请求的比例达到 90%,且模糊搜索的耗时远小于精确搜索,两次搜索不会增加太多等待时间。
模糊搜索可能搜到大量结果,按时间倒序后,相关度高的结果可能排在后面,造成不好的搜索体验。这里可以对模糊搜索的结果进行剪枝,去除低评分的结果,使得相关度高的结果适当靠前。
另外,可通过调整不同字段的权值(boost)来调整搜索评分。按照多数用户的搜索习惯,适当调高主题搜索权重。
未来,邮箱还将在搜索框集成查询语法,让用户自定义搜索条件(and、or、not)。
4. 调整match_phrase
使用 Kibana 的调试工具可以很方便地获取一段文字被分词器处理后的 token 列表,如下图,token 列表中每个 token 都是一个分词。在上文 ES 搜索机制中提到,match_phrase 会确保搜索关键字 token 列表中的词语、词语间隔和词语顺序,与原文分词后的 token 列表相同。
(1)测试案例
下面来看一个案例,原文是“一品城府7-1-501”,搜索关键字“一品城府501”无法精确搜索。
(2)分析原因
如下图,搜索关键字分词 token 列表中的词语、词语顺序与原文相同,但词语间隔不对,则 match_phrase 失败。
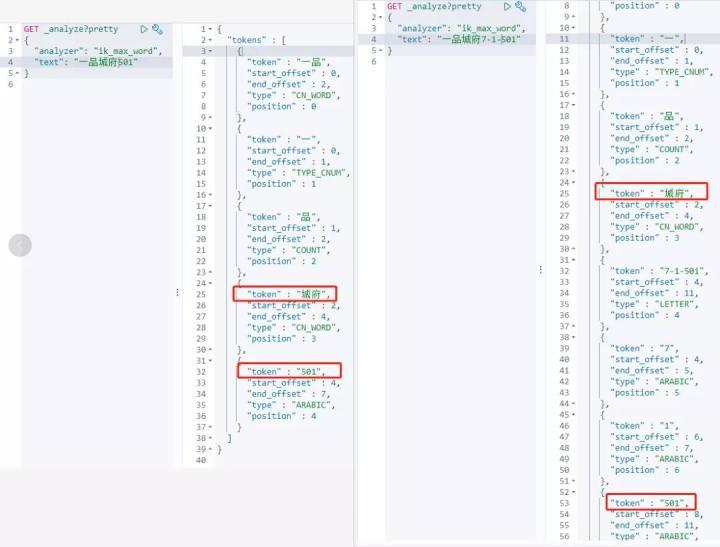
(3)解决思路
match_phrase 有个参数 slop,设置 slop 值能容忍一定的 token 列表词语间隔。在4.2节第四步分词匹配时会不断变换分词位置,可以只过滤掉词语间隔超过 slop 的 docid。
这个案例中,match_phrase.slop 值设为 4 可解决问题。但设置 slop 值将增大匹配工作量,如果 slop 过大将严重拖慢搜索速度,一般 slop 设置为 5 以内。
5. 改造分词器
(1)测试案例
测试时,有一类反馈比较集中,搜索字母+数字(如订单号)搜不出结果。看一个案例,原文是“AL0927_618”,搜索关键字“AL0927”,无论使用精确搜索还是模糊搜索都搜不出内容。
(2)分析原因
因为关键字的“tokenal0927”不在原文 token 列表中,不满足 4.2 节搜索机制中第三步匹配条件。这个问题其实是分词器的缺陷,ik 分词的 github 上有人提过类似案例,但无人回应。
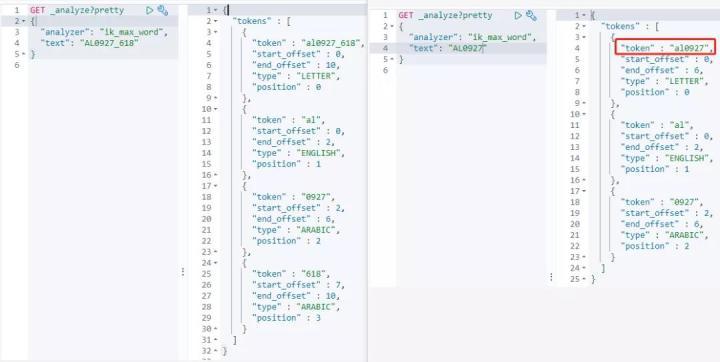
(3)解决思路
对比上图中原文和关键字 token 列表,如果搜索时关键字分词 token 列表中不出现关键字本身(al0927),就能成功实现 match_phrase 匹配。有两种实现方案:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java