
性能提升400%,ClickHouse在携程酒店数仓的实践
一、背景
随着时间推移和业务的快速发展,携程酒店数据累积越来越多。目前流量日数据在3T左右,再加上各种订单、价、量、态等数据更是庞大。现有Hive(Spark引擎)执行速度虽然相对较快,但在国际化发展背景下,一些海外业务由于时差问题,数据需要比国内提前数小时完成,性能提升迫在眉睫。2020年初,我们开始研究ClickHouse在数据仓库领域应用。
本文将从技术方案选型、集成开发环境封装、ClickHouse代码优化技巧、异常问题处理、服务器故障处理五个方面分享ClickHouse实践,希望给关注同样问题的同学有所启发。
二、技术预研与技术方案选型
1)公司内部有无ClickHouse集群使用环境。经过了解知晓,原ClickHouse验证集群正准备下线,无可用环境;
2)办公电脑通过Vmware搭建ClickHouse集群,部分同学基于单机练习ClickHouse语法以及验证各项ClickHouse特性,部分专攻ClickHouse集群搭建及各项配置、集成开发环境的封装等底层功能。
3)2020年3月,Vmware搭建ClickHouse集群基本完成各项验证,同时4台物理服务器(配置:内存-256G,CPU-40core,硬盘-3.5T)到位。为保证对生产平稳过渡(不给生产DB造成额外压力),我们从Hive ODS层同步数据至ClickHouse ODS层,技术方案如下图1(橙色部分是ClickHouse实现部分):
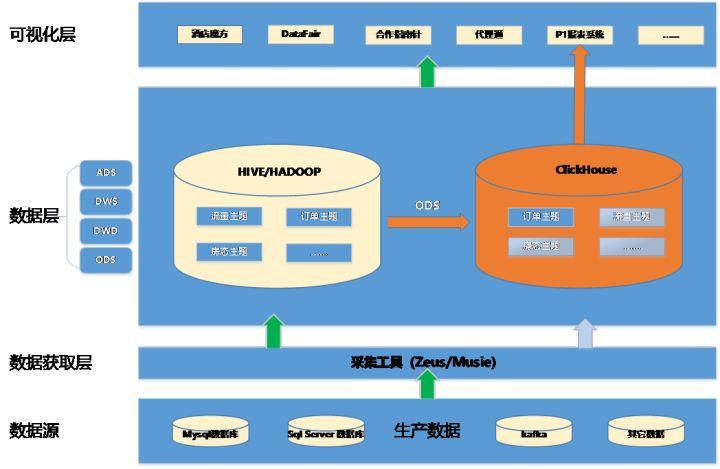 图1
图1
三、集成开发环境封装
1)数据同步工具封装
我们发现消耗在数据同步上的时间太多,是数据计算时间的十几倍。于是开始研究ClickHouse数据导入方式,其中一种如下:
cat filename.orc | clickhouse-client -- query="INSERTINTO some_table FORMAT ORC"在此基础上通过缓存、批处理等机制封装成新的orc2ck.sh同步工具,使同步速度比原先工具的性能提高500%以上。
2)集成开发工具封装
为了提高开发效率,减少代码冗余,我们封装了ClickHouse代码执行工具ck.sh,执行环境如下图2(橙色部分是应用代码部分,红色框部分是封装工具及参数)。
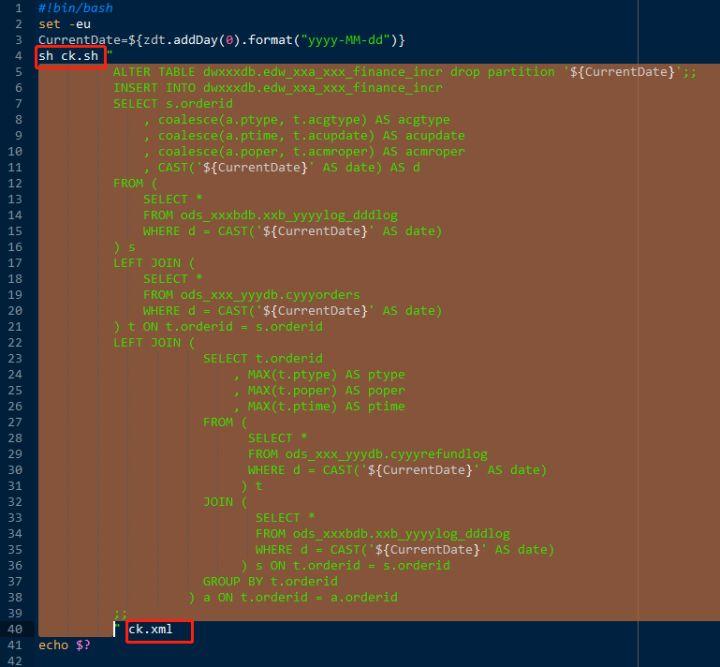 图2
图2
四、ClickHouse代码优化技巧
1)小表置于join右侧降低内存消耗
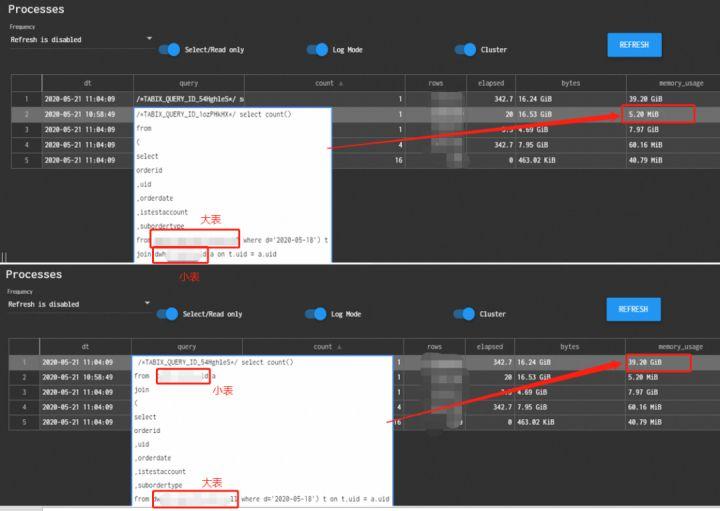
2)用in替代join提高执行速度
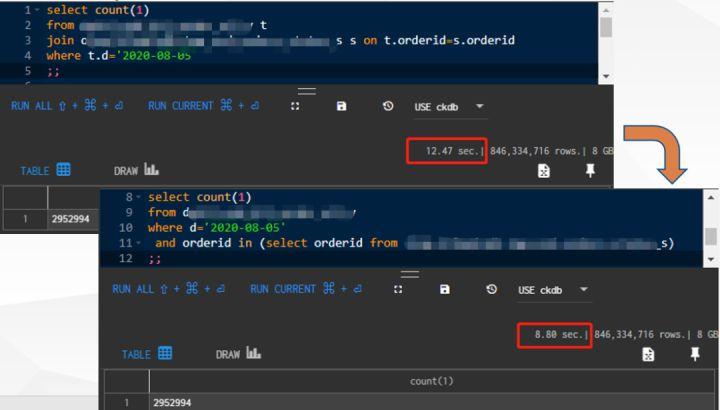
3)减少数据扫描提高执行速度
通过增加过滤逻辑可以减少数据扫描,达到提高执行速度及降低内存消耗的目的。
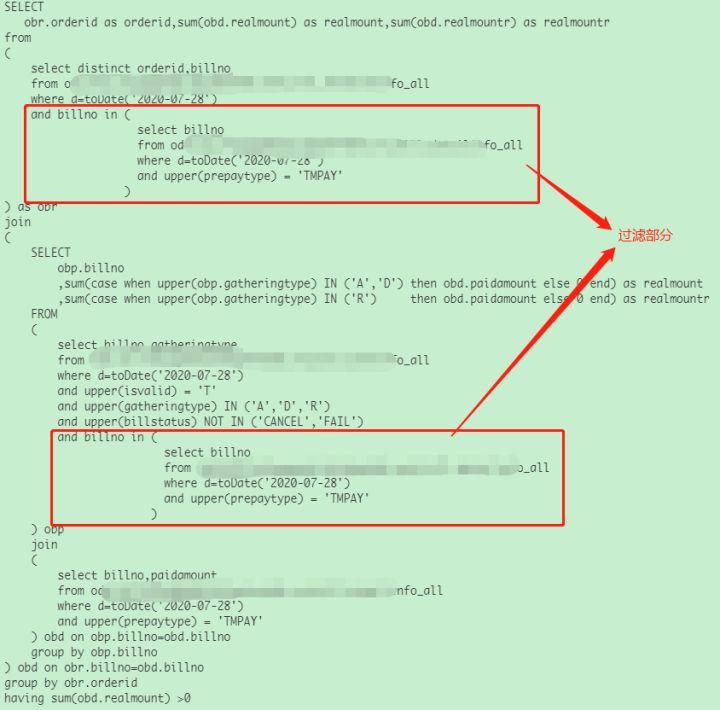
五、异常问题处理
Code: 252, e.displayText() = DB::Exception: Too many parts (301) . Merges are processing significantly slower than inserts.解决这个问题需要先分析Merge过程,如下图所示:
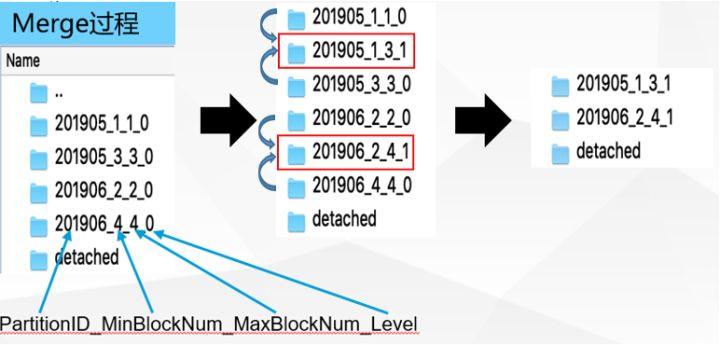
Merge过程是异步的,插入速度过快会导致以上错误,一般建议速度100w/s。
Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded这种错误是请求内存高于系统分配内存导致,解决这类问题可以从两方面入手:
- 在服务器内存充裕的情况下增加内存配额,一般通过max_memory_usage来实现;
- 在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行速度;一般通过max_bytes_before_external_group_by 、max_bytes_before_external_sort参数来实现。
如果以上方法仍然无法解决问题,需要检查代码是否合理,从代码角度去优化(参考代码优化技巧部分)。
六、服务器故障处理
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java