
分布式系统的高内聚低耦合
什么是高内聚低耦合
分布式系统的本质就是「分治」和「冗余」。
其中,分治就是“分解 -> 治理 -> 归并”的三部曲。「高内聚」、「低耦合」的概念就来源于此。
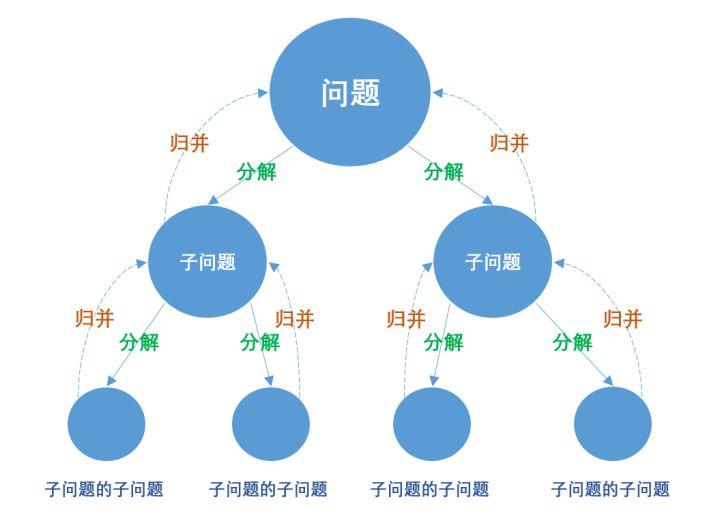
需要注意的是,当你在做「分解」这个操作的时候,务必要关注每一次的「分解」是否满足一个最重要的条件:不同分支上的子问题,不能相互依赖,需要各自独立。
因为一旦包含了依赖关系,子问题和父问题之间就失去了可以被「归并」的意义。
比如,一个「问题Z」被分解成了两个子问题,「子问题A」和「子问题B」。但是,解问题A依赖于问题B的答案,解问题B又依赖于问题A的答案。这不就等于没有分解吗?
题外话:这里的“如何更合理的分解问题”这个思路也可以用到你的生活和工作中的任何问题上。
所以,当你在做「分解」的时候,需要有一些很好的着力点去切入。
这个着力点就是前面提到的「耦合度」和「内聚度」,两者是一个此消彼长的关系。
越符合高内聚低耦合这个标准,程序的维护成本就越低。为什么呢?因为依赖越小,各自的变更对其他关联方的影响就越小。
所以,「高内聚」和「低耦合」是我们应当持续不断追求的目标。
题外话:耦合度,指的是软件模块之间相互依赖的程度。比如,每次调用方法 A 之后都需要同步调用方法 B,那么此时方法 A 和 B 间的耦合度是高的。
内聚度,指的是模块内的元素具有的共同点的相似程度。比如,一个类中的多个方法有很多的共同之处,都是做支付相关的处理,那么这个类的内聚度是高的。
怎么做好高内聚低耦合
做好高内聚低耦合,思路也很简单:定职责、做归类、划边界。
首先,定职责就是定义每一个子系统、每一个模块、甚至每一个class和每一个function的职责。
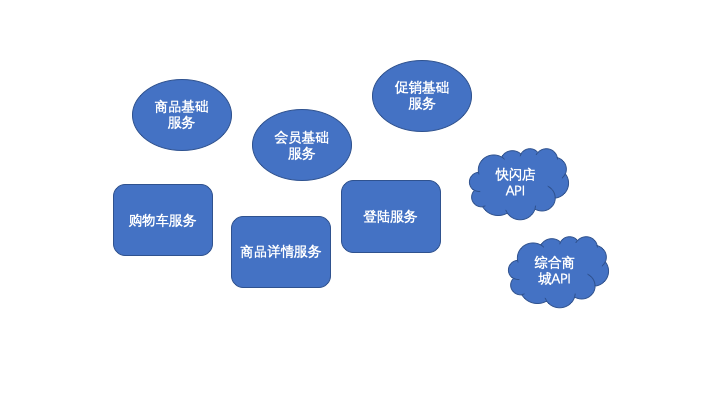
比如,在子系统或者模块层面可以这样。
又比如,在class或者function层面可以这样。
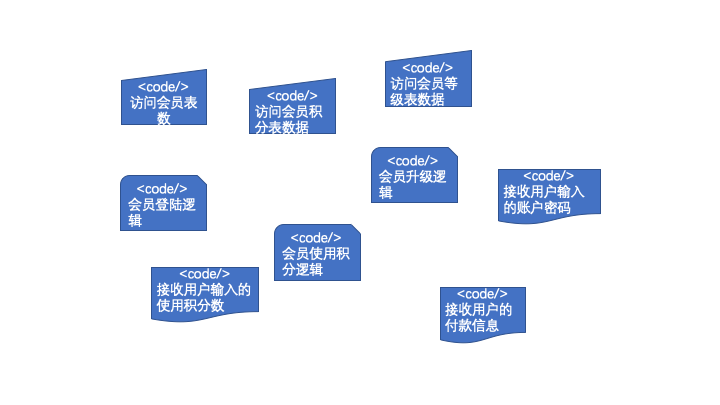
我想这点大家平时都会有意识的去做。
做好了职责定义后,内聚性就会有很大的提升,同时也提高了代码/程序的复用程度。
至此,我们才谈得上「单一职责(SRP)」这种设计原则的运用。
其次,做归类。梳理不同模块之间的依赖关系。
像上面提到的案例1可以归类为3层:
- 基础层:商品基础服务、会员基础服务、促销基础服务
- 聚合层:购物车服务、商品详情服务、登陆服务
- 接入层:快闪店API、综合商城API
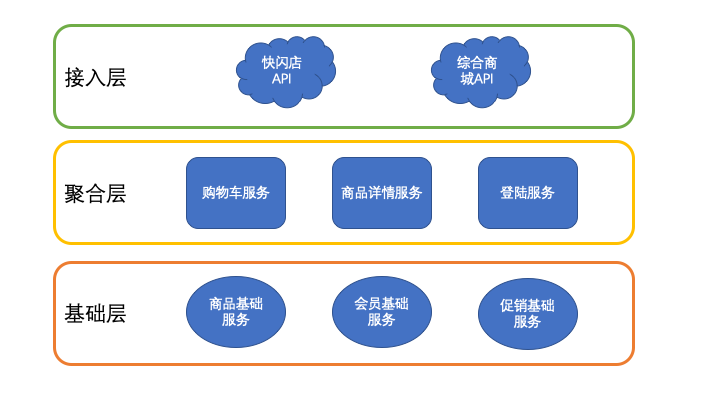
案例2也可以归类为3层:
- 数据访问层:访问会员表数据、访问会员积分表数据、访问会员等级表数据
- 业务逻辑层:会员登陆逻辑、会员使用积分逻辑、会员升级逻辑
- 应用层:接收用户输入的账户密码、接收用户输入的使用积分数、接收用户的付款信息

最后就是划边界。好不容易梳理清楚,为了避免轻易被再次破坏,所以需要设立好合理清晰的边界。
否则你想的是这样整齐。

实际会慢慢变成这样混乱。

那么应该怎么划边界呢?
class和function级别。这个层面可以通过codereview或者静态代码检测工具来进行,可以关注的点比如:
1.调用某些class必须通过interface而不是implement
2.访问会员表数据的class中不能存在访问商品数据的function
模块级别。可以选择以下方案:
1.给每一种类型的class分配不同project,打包到各自的dll(jar)中
2.每次代码push上来的时候检测其中的依赖是否有超出规定的依赖。例如,不能逆向依赖(检测dal是否包含bll);不能在基础层做聚合业务(检测商品基础服务是否包含其他基础服务的dll(jar))。
系统级别。及时识别子系统之间的调用是否符合预期,可以通过接入一个调用链跟踪系统(如,zipkin)来分析请求链路是否合法。
让边界更清晰、稳定的最佳实践
很多时候不同的模块或者子系统会被分配到不同的小组中负责,所以z哥再分享几个最佳实践给你。它可以让系统之间的沟通更稳定。
首先是:模块对外暴露的接口部分,数据类型的选择上尽量做到宽进严出。比如,使用long代替byte之类的数据类型;使用弱类型代替强类型等等。
举个「宽进严出」的例子:
//使用long代替byte之类的数据类型。
void Add(long param1, long param2){
if(param1 <1000&& param2 < 1000){ //先接收进来,到里面再做逻辑校验。
//do something...
}
else{
//do something...
}
}其次是:写操作接口,接收参数尽可能少;读操作接口,返回参数尽可能多。
为什么呢?因为很多时候,写操作的背后会存在一个潜在预期,是「准确」。
准确度和可信度有着很大的联系,只有更多的逻辑处理在自己掌控范围内进行才能越具备「可信度」(当然是职责范围内的逻辑,而不是让商品服务去计算促销的逻辑)。反之,上游系统一个bug就会牵连到你的系统中。
而读操作背后的潜在预期是:「满足」。你得提供给我满足我当前需要的数据,否则我的工作无法开展。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java