
Hive SQL 入门简介
一、Hive 介绍
简单来说,Hive 是基于 Hadoop 的一个数据仓库工具。
Hive 的计算基于 Hadoop 实现的一个特别的计算模型 MapReduce,它可以将计算任务分割成多个处理单元,然后分散到一群家用或服务器级别的硬件机器上,降低成本并提高水平扩展性。
Hive 的数据存储在 Hadoop 一个分布式文件系统上,即 HDFS。
需明确的是,Hive 作为数仓应用工具,对比 RDBMS(关系型数据库) 有3个“不能”:
- 不能像 RDBMS 一般实时响应,Hive 查询延时大;
- 不能像 RDBMS 做事务型查询,Hive 没有事务机制;
- 不能像 RDBMS 做行级别的变更操作(包括插入、更新、删除)。
另外,Hive 相比 RDBMS 是一个更“宽松”的世界,比如:
- Hive 没有定长的 varchar 这种类型,字符串都是 string;
- Hive 是读时模式,它在保存表数据时不会对数据进行校验,而是在读数据时校验不符合格式的数据设置为NULL。
二、Hive 查询语句
Hive select 常规语法与 Mysql 等 RDBMS SQL 几乎无异,下面附注语法格式,具体不做详细讲解。本节重点介绍 Hive 中出现的一些比较特殊且日常中我有用到的一些技巧给到大家参考。
2.1 附注 select 语法及语序,
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY order_condition]
[DISTRIBUTE BY distribute_condition [SORT BY sort_condition] ]
[LIMIT number]2.2 多维度聚合分析 grouping sets/cube/roolup,
以一个示例来说明 3者作用及区别。request 表为后端请求表,现需分别统计3种不同维度的聚合:总共多少请求?不同系统、设备多少请求?不同城市多少请求。
不使用多维聚合方法,
SELECT NULL, NULL, NULL, COUNT(*)
FROM requests
UNION ALL
SELECT os, device, NULL, COUNT(*)
FROM requests GROUP BY os, device
UNION ALL
SELECT null, null, city, COUNT(*)
FROM requests GROUP BY city;使用 grouping sets,
SELECT os, device, city ,COUNT(*)
FROM requests
GROUP BY os, device, city GROUPING SETS((os, device), (city), ());cube 会枚举指定列的所有可能组合作为 grouping sets,而 roolup 会以按层级聚合的方式产生 grouping sets。如,
GROUP BY CUBE(a, b, c)
--等价于以下语句。
GROUPING SETS((a,b,c),(a,b),(a,c),(b,c),(a),(b),(c),())
GROUP BY ROLLUP(a, b, c)
--等价于以下语句。
GROUPING SETS((a,b,c),(a,b),(a), ())2.3 正则方法指定 select 字段列
说是指定,其实是排除,如:`(num|uid)?+.+` 排除 num 和 uid 字段列。
另外,where 使用正则可以如此:where A Rlike B、where A Regexp B。
2.4 Lateral View(一行变多行)
Lateral View 和表生成函数(例如Split、Explode等函数)结合使用,它能够将一行数据拆成多行数据,并对拆分后的数据进行聚合。
假设您有一张表pageAds,它有两列数据,第一列是pageid string,第二列是adid_list,即用逗号分隔的广告ID集合。
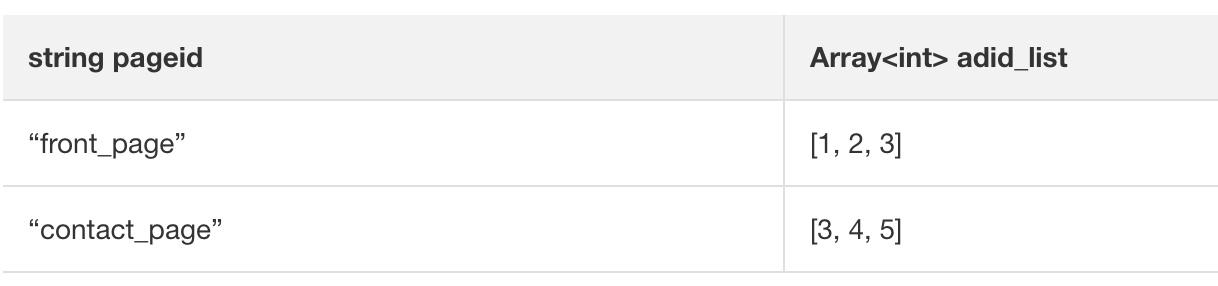
现需要统计所有广告在所有页面的出现次数,则先用 Lateral View + explode 做处理,即可正常分组聚合统计。
SELECT pageid, adid
FROM pageAds LATERAL VIEW explode(adid_list) adTable AS adid;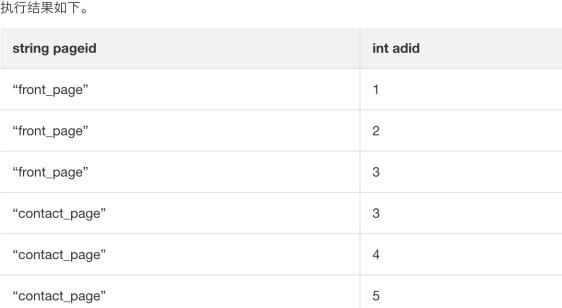
2.5 窗口函数
Hive 的窗口函数非常丰富,这在很多 RDBMS 中是少见的。(至少在 mysql 的较早期版本一直没有支持窗口函数,一个分组排序得用上非常复杂的 SQL 自定义变量)
其中最常用的窗口函数当属 row_number() over(partition by col order col_2),它可以实现按指定字段的分组排序。
其它更丰富的窗口函数,我这不赘述,篇幅太大,完全可以重开一篇新的文章。建议参考阿里云 MaxCompute 的这份「窗口函数」的文档,写得非常详细,强烈推荐!
2.6 代码复用
- CTE复用:with t1 as();
- 阿里云 MaxCompute 支持创建 SQL Script 脚本:允许使用 @var:= 方式创建变量,实现复用。
with t1 as(
select user_id
from user
where ...
)
@var:= select
shop_id
from shop
where ...;
select *
from user_shop
where user_id in(select * from t1)
and shop_id in(select * from @var);三、Hive 定义语句(DDL)
3.1 Hive 建表语句格式,
方法一:独立声明
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [DEFAULT value] [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS]
[STORED BY StorageHandler] -- 仅限外部表
[WITH SERDEPROPERTIES (Options)] -- 仅限外部表
[LOCATION OSSLocation]; -- 仅限外部表
[LIFECYCLE days]
[AS select_statement]方法二:从已有表直接复制
CREATE TABLE [IF NOT EXISTS] table_name
LIKE existing_table_name下面对当中关键的声明语句做解释:
- [EXTERNAL]:声明为外部表,往往在该表需要被多个工具共享时声明,外部表删表不会删数据,只会删元数据。
- col_name datatype:data_type 一定要严谨定义,避免 bigint、double 等等统统用 string 的偷懒做法,否则不知某天数据就出错了。(团队内曾有同事犯过此错误)
- [if not exists]:创建时不指定,若存在同名表则返回出错。指定此选项,若存在同名表忽略后续,不存在则创建。
- [DEFAULT value]:指定列的默认值,当INSERT操作不指定该列时,该列写入默认值。
- [PARTITIONED BY]:指定表的分区字段,当利用分区字段对表进行分区时,新增分区、更新分区内数据和读取分区数据均不需做全表扫描,可以提高处理效率。
- [LIFECYCLE]:是表的生命周期,分区表则每个分区的生命周期与表生命周期相同
- [AS select_statement]:意味着可直接跟 select 语句插入数据
简单示例:创建表sale_detail来保存销售记录,该表使用销售时间 sale_date 和销售区域 region 作为分区列。
create table if not exists sale_detail
(
shop_name string,
customer_id string,
total_price double
)
partitioned by (sale_date string, region string);创建成功的表可以通过 desc 查看定义信息,
desc <table_name>;
desc extended <table_name>; --查看外部表信息。如果需要不记得完整的表名,可以通过 show tables 在 db(数据库)范围内查找,
use db_name;
show tables ('tb.*'); --- tb.* 为正则表达式3.2 Hive 删表语句格式,
DROP TABLE [IF EXISTS] table_name; --- 删除表
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition_col1 = partition_col_value1, ...); --- 删除某分区3.3 Hive 变更表定义语句格式,
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java