
日均TB级数据,携程支付统一日志框架
一、背景
支付中心作为携程集团公共部门,主要负责的业务包括交易、实名绑卡、账户、收单等,由于涉及到交易相关的资金流转以及用户实名认证,部分用户操作环节的中间数据应内控/审计要求需要长时间保存。当前研发应用多,日志量大、格式各异,对于日志的存储和使用产生较大的挑战,故支付数据与研发团队群策群力,共同开发了一套统一日志框架。
二、总体架构图
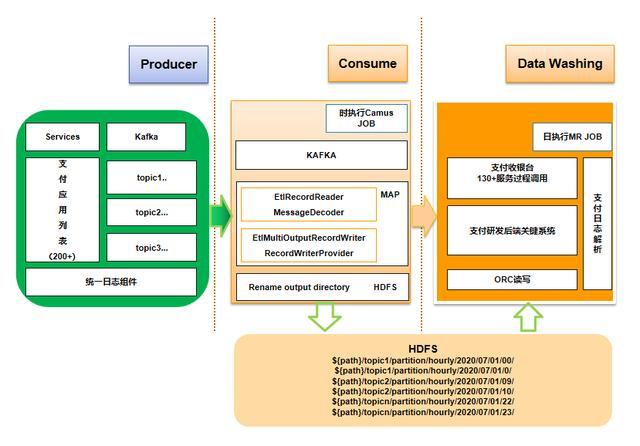
核心模块包括:日志生产、日志采集、日志解析,其中调用流程如下:
1)研发应用/服务接入基于log4j2扩展的统一日志组件,将日志抛送至kafka。
2)周期性启动消费kafka topic的camus job将日志写入hdfs。
3)T+1启动MR job读取camus写入的hdfs内容并load到hive表。
三、日志生产-统一日志组件
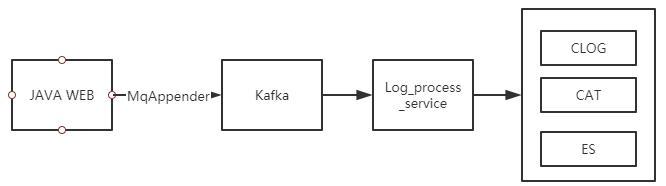
支付研发基于log4j2自定义了多个Appender,将应用日志以服务调用形式抛送至kafka,并被log_process_service 服务统一处理并提交至携程常用基础日志框架如:CLOG、CAT、ES,各应用无需关心公司日志框架,统一由日志平台处理。
其优点:
- 不同日志框架对应着不同的Appender,方便进行日志框架接入的扩展。
- 采用AOP编程,对于接入的业务侵入性小,接入简单。
- 定义了丰富的java注解,便于日志配置化输出,其中可打印日志包括但不限于:类名、方法名、方法入参、返回值、异常等,支持敏感字段脱敏。
存在的问题:
- 日志格式不规范:研发应用数百个,研发人员较多,日志格式差异大,给数据分析和使用带来巨大挑战。
- 存储时长短:当前公司在线CLOG存储系统只能查询最近几天数据、ES保存稍长一段时间数据且不支持批量查询,基础离线CLOG hive表由于数据量巨大,仅能做到T+2,无法满足T+1的报表需求。
故支付数据团队在研发团队统一日志组件的基础上,结合数据分析和数据存储生命周期开发了统一日志框架。
3.1 统一日志-埋点设计
支付研发团队负责数百个服务或应用,支持的业务包括:路由、鉴权、免密、卡服务、订单、钱包实名、电子支付等,不同的业务又可拆分app、h5、online、offline等项目,整合这些数据是个极大的挑战。如果各系统研发埋点任意指定,会给BI数据分析带来极大的困难,数据分析准确性难以得到保障,故支付数据基于业务特点定义了一套统一日志埋点规范。
字段定义主要是基于日常分析需求,致力于简化数据的使用,故总体原则为json形式,当前原始日志有两部分组成:tag/message,其中tag数据结构为Map,关键数据一般是通过tag内的数据进行检索,明细数据通过message进行检索,tag与message的组成格式为:[[$tag]]$message,目前标准字段包括两类:规范性字段和通用性字段。
3.1.1 规范性字段格式
规范性字段需要应用研发一定程度的参与,提供符合字段命名的类和方法。部分字段名称及定义如下:
字段名称字段类型描述serviceNamestring调用服务名称tagMapkeyvalue信息messagestring原始日志requeststring接口请求参数responsestring接口返回值requesttimestring日志请求时间responsetimestring日志请求时间
其中tag可以灵活填充,主要扩展字段如下:
名称字段类型描述versionstringapp版本号platstring平台信息refnostring流水号
3.1.2 通用字段格式
日志框架能够自动获取属性,无需研发编码,即可打印。
字段名称字段类型描述applicationidstring携程应用唯一识别号logtimestring日志生成时间
3.2 分区/分桶字段的定义
当前离线数据分析基于hive引擎,hive的分区分桶设计极大的影响了查询性能,特别是在日志量巨大的场景下,分区字段的选择尤为关键。如:用户进入支付收银台可能会有上百个场景,而每种场景下会有多次服务调用,其中不同场景下服务调用频率差异很大,占用的空间差异也较大,故针对每种场景分配一个唯一的场景号,通过场景号进行分区,可以高效的进行数据分析,而过多的分区也可能导致较多的小文件,对hadoop namenode产生较大的影响,此时结合分桶能够达到优化查询效率且避免分区无限制野蛮增长产生众多过多小文件的问题。
四、日志采集

日志采集框架基于LinkedIn的开源项目Camus,Camus使用MapReduce读取kafka数据然后写入hdfs,由于无reduce阶端,所有数据处理及写入都在Map侧,很少会发生数据倾斜,Camus具有接入简单,方便扩展,故我们进行了二次开发,以满足当前业务的需要:
- 自定义decoder/partitioner,原生的decoder/partitioner支持的hdfs落地路径主要基于日期,较为粗糙,无法适应业务的需要。故自定义decoder 抽取原始日志分区字段,然后代入partitioner中,生成具有业务含义的hdfs输出路径,为特定时间范围数据回刷提供了高效的解决方案。
- 自定义provider,原生的StringRecordWriterProver仅支持text文件方式落地,占用空间大、压缩后无法并行切分,容易错列错行,而orc格式数据,有效的节约了hdfs占用空间,查询效率高且可以切分,有利于日志解析job的高效执行。其中在配置Camus job过程中需要关注如下问题:
4.1 camus 任务执行
- 执行频率设置
Error: java.io.IOException: target exists.the file size(614490 vs 616553) is not the same.由于kafka消息保存天数有限和单个分区size有限(Server 配置:log.retention.bytes),携程侧为3天和10G,如果camus同步kafka频率较低时,可能会出现数据丢失,故需要根据日志量大小,设置camus 调度任务的执行频率,防止数据丢失。
- 任务重叠执行
Error: java.io.IOException: target exists.the file size(614490 vs 616553) is not the same.camus从kafka 读取数据,任务要以单例形式执行,任务执行完成后才会更新kafka的offset,若一个任务执行了多次,就会导致数据大小无法对齐,此时需要删除配置路径下的所有数据后重新启动任务,即可完成修复。
4.2 如何控制camus落地文件的大小
当kafka各partition数据写入量不平衡时,由于各partition会写入一个hdfs文件中,如果研发日志集中写入kafka某个partition,会导致这个partition对应的hdfs文件占用空间特别大,如果恰巧这个文件是不可切分的,极端情况下会导致只有一个线程去解析这个大文件,降低了数据读写的并发度,拉长了数据解析时间,遇到这种问题的解决办法是:
- 临时解决方案:研发日志分散写入kafka partition,不要导致某类数据集中写入一个partition;
- 高效解决方案:数据侧采用可切分的输入格式,进行数据切分;
4.3 写入orc文件格式注意事项
- orc写入timeout
AttemptID:attempt_1587545556983_2611216_m_000001_0 Timed out after 600 secsorc文件写入速度较text文件会慢很多,如果同时写入的的文件较多或者内存回收占用时间较长,会导致map方法在600秒内没有读、写或状态更新,job会被尝试终结,解决方法是调高默认的task超时时间,由10分钟调高到20分钟。
mapreduce.task.timeout=1200000- OOM 内存溢出
beyond physical memory limits. Current usage: 2.5 GB of 2.5 GB physical memory used; 4.2 GB of 5.3 GB virtual memory used. Killing container.在orc写文件的时候如果出行较多的OOM,此时需要加大map执行的内存。
mapreduce.map.memory.mb=8096
mapreduce.map.java.opts=-Xmx6000m五、统一日志-解析

鉴于日志解析工作主要集中在MapReduce的Map侧,而Map侧通过参数调整能够很容易控制map的个数,以提高数据解析的并发度,MapReduce主要分为:intputformat、map、shuffle、reduce等几个核心阶段,通过优化各阶段的执行时间,可以显著提高日志解析的速度。
5.1 inputsplit优化
MR job中影响map的个数主要有:
- 文件个数:如果不采用CombineFileInputFormat,那么不会进行小文件合并,每个文件至少有一个map处理,当小文件太多时,频繁启动和回收线程也会对性能产生影响,同时对集群其它job资源分配产生影响。
- 文件属性:当文件较大且可切分时,系统会生成多个map处理大文件,inputsplit块按照MR最小单元进行文件切割(split),并且一个split对应一个MapTask。
前期日志解析程序的性能较高,一天的全量日志解析约25分钟,中间有段时间任务执行时间从25分钟延迟到4个小时,原因是研发将大量订单号为空的日志写入到指定的partition中,日志量巨大,导致其中少量map在读取大文件时执行时间特别长。
经过分析发现text+snappy 文件无法切分,只能够被一个map处理,将camus落地数据格式从text+snappy换为orc+snappy格式,同时开发了支持orc文件格式的CombineFileInputFormat,既减少了小文件对hadoop计算资源果断的占用也提高了job的并发程度。
5.2 shuffle优化
使map的输出能够更加均匀的映射到reduce侧,由于默认的分区策略是对map的输出key hash取reduce个数的模,容易导致数据倾斜,解决办法是在key上面增加时间戳或者重写partition函数。
5.3 批量日志解析
当前MR的输出会作为hive外表的数据源,hive表会按照业务过程进行分区,所有数据的解析结果路径为:日期+业务过程,而业务过程可能有数百个,采用了MultipleInputs/MultipleOutputs 能够在一个mapreduce job中实现多输入多输出的功能,以适应业务自定义解析,并归一化后统一抛到reduce侧。
5.3.1 空文件生产
在使用的过程中会出现生成众多临时小文件及生成size 为0的小文件,增加了hdfs namenode内存压力,同时空文件也会导致spark表查询失败,可通过LazyOutputFormat进行修复。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java