
爱奇艺在 Dubbo 生态下的微服务架构实践
本文将主要围绕以下几个主题展开:
- Apache Dubbo 简介及其在爱奇艺的发展历史
- 爱奇艺内部对 Dubbo SDK 的扩展及围绕 Dubbo 相关的微服务生态建设
- 后续规划
Apache Dubbo 简介及其在爱奇艺的发展历史
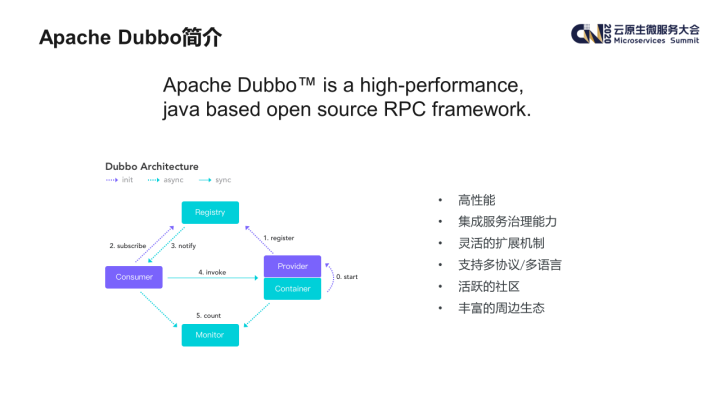
1. Apache Dubbo 简介
Apache Dubbo 是一款由阿里开源的高性能 RPC 框架。Dubbo 框架本身除了通信外,还内置了微服务治理的多项功能(如注册发现,路由规则等)。
自从 2017 年重启维护以来,Dubbo 社区一直保持了较高的活跃度。从周边生态来看也相对比较完善,比如 Nacos、Sentinel 等开源框架都对其提供了支持。在语言支持方面,除了 Java 语言之外,Dubbo-go 社区目前也非常活跃,且针对 python,nodejs 等主流开发语言 Dubbo 也有一些开源实现。基于以上这些因素,我们决定引入 Dubbo 框架,用以替换原先自研的 RPC 框架。
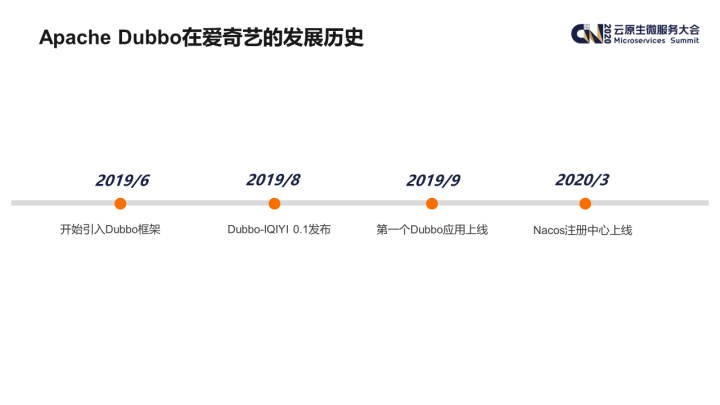
爱奇艺是在 2019 年 6 月正式开始引入 Dubbo 框架的。我们将其与对接公司内部的基础设施做了对接,如注册中心、监控系统等等,并在 2019 年 8 月正式发布了第一个内部版本。
这里值得一提的是我们并没有维护自己的 Dubbo 分支,而是利用 Dubbo 强大的扩展机制开发我们的新特性,这样使得我们能够在跟进 Dubbo 社区新版本方面没有障碍。在这个内部版本发布后,很快就有第一个生产应用在同年 9 月份上线。后续我们在进一步扩展 Dubbo SDK 功能的同时,在周边生态建设方面也做了不少工作,其中就包括在 2020 年 3 月份上线的 Nacos 注册中心等。
2. Apache Dubbo 在爱奇艺的发展历史
优秀的微服务开发框架是业务服务化的基石,但是由于微服务应用的复杂性,要帮助业务团队更好地实践微服务架构,还需要一个相对完善的微服务生态体系作为支撑。
微服务生态体系
下图展示了目前爱奇艺内部微服务生态体系的全景。
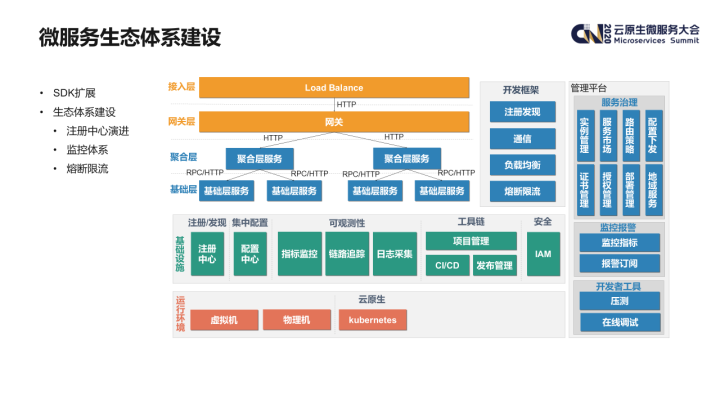
这里面分为几个层面:
- 首先是开发框架层面,Dubbo SDK 集成了注册发现、通信及负载均衡的能力,但是类似熔断及限流功能还是需要采用 Sentinel 等框架来进行支持;
- 在基础设施层面,注册中心/配置中心均是微服务生态中重要组件;此外为了保证应用的可用性,完整的监控体系也必不可少,如指标监控、日志监控、链路追踪等;
- 最后,为了方便运维人员管理微服务应用,还需要一套功能完善的管理平台,其中包括了服务管理、配置下发、监控告警及一些对开发人员的支持功能。
可以看到,整个微服务的生态体系还是非常庞大的,限于篇幅,以下的演讲会主要会集中在以下几个方面展开:
- Dubbo SDK 的扩展
生态体系建设
- 注册中心的演进
- 监控体系的建设
- 熔断限流方面的支持
1. Dubbo SDK 的扩展
根据爱奇艺内部的实际情况,以及各个业务团队的需求,我们主要对 Dubbo SDK 做了以下几方面的扩展:
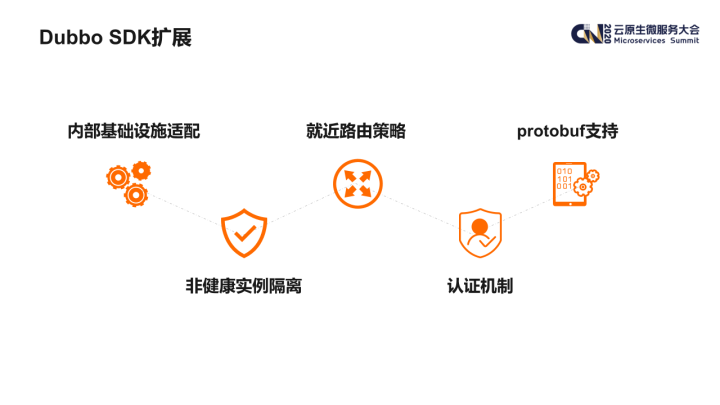
- 基础设施的适配:包括注册中心、监控系统、内部的容器平台等等;
- 可用性增强:包括非健康实例隔离以及区域就近路由的机制;
- 安全性增强:支持了服务间调用的认证机制;
- 序列化:增加了对 protobuf 序列化方式的支持。
1)非健康实例隔离机制
首先介绍非健康实例隔离机制。
Dubbo SDK 默认采用随机的负载均衡策略,并通过失败重试的策略来保证调用的成功率。通过实践发现,生产环境中有时会出现少数 Provider 节点虽然已经处于不健康的状态(比如磁盘写满等),但是还是能与注册中心进行正常通信,这样 Consumer 端还是能发现这些实例,导致部分请求还是会被分发过去。这些请求由于实例本身的问题,可能会出现响应时间变慢或者错误率上升,从而引起整个服务质量的下降(响应时间抖动或整体调用成功率下降)。
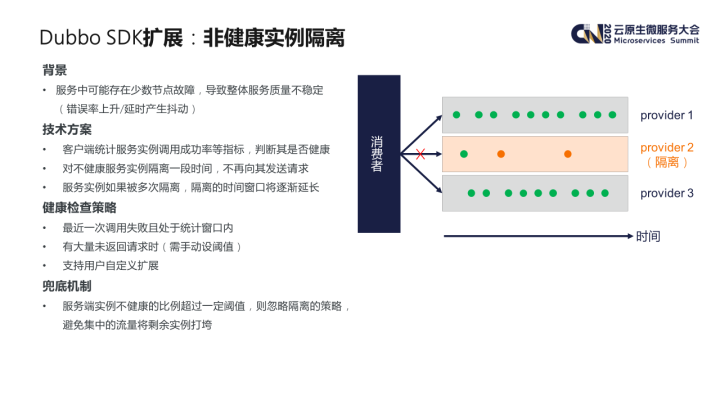
为了解决这样一个问题,我们的思路是引入客户端健康检查机制,即 Consumer 端会对每个 Provider 实例的请求成功率进行统计,判断其是否健康;对于不健康的 Provider 实例,Consumer 端会对其进行隔离一段时间,后续的请求不再通过负载均衡策略发送到这些实例上。另外 Consumer 端会维护每个 Provider 实例被隔离的次数,如果某个实例被多次隔离,每次隔离的时间也会相应变长。
我们的扩展机制中提供了默认的健康检查策略,包括检查最近一次调用是否出现服务端异常,或者一段时间内是否有大量发出的请求未被返回。用户也可以通过扩展我们提供的接口来实现自己的检查策略。
为了避免因为网络抖动等造成的意外影响,我们还设计了一套兜底机制。即当 Provider 实例中不健康的比例超过一定阈值时,Consumer 会忽略实例隔离的策略,避免集中的流量将剩余的实例打垮。
2)区域就近路由机制
接下来介绍一下区域就近路由机制。
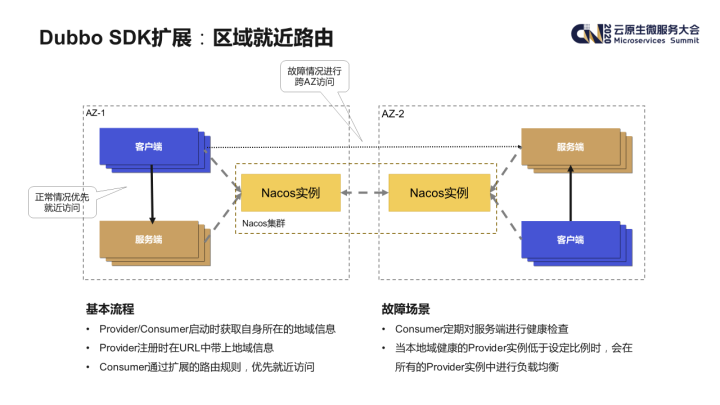
爱奇艺在多地都建有机房,为了确保在单个机房出现故障时各业务系统仍能正常工作,核心业务一般会采用两地三中心的架构进行部署。在这种场景下,系统如果产生跨地域的访问请求,由于网络延时的原因势必导致请求延时增大,所以各业务一般都有客户端就近访问服务端实例的需求。
我们通过扩展 Dubbo 的路由机制实现了这样的策略。大致的实现原理是,Provider 和 Consumer 实例在启动时,会先从一个公共的地域服务中获取实例当前所在地域信息(比如可用区等)。Provider 实例在服务注册时会将上述的地域信息作为 URL 的一部分注册到注册中心,这样 Consumer 实例就能够在服务发现时获知每个 Provider 实例的地域信息并和自身的地域信息进行比对,优先选择临近的实例就近访问。
此外,Consumer 实例也会通过上文中提到的健康检查机制对服务端实例进行检查,如果发现本地域健康的 provider 实例低于设定比例时,则会忽略就近路由的策略,改为在所有的 Provider 实例中进行负载均衡,从而实现自动的 failover 机制。
3)认证机制
部分内部服务有安全认证相关的需求,不希望非授权应用对其进行访问。为了解决这个问题,我们开发了一套基于数字签名及 AK/SK 的认证体系。
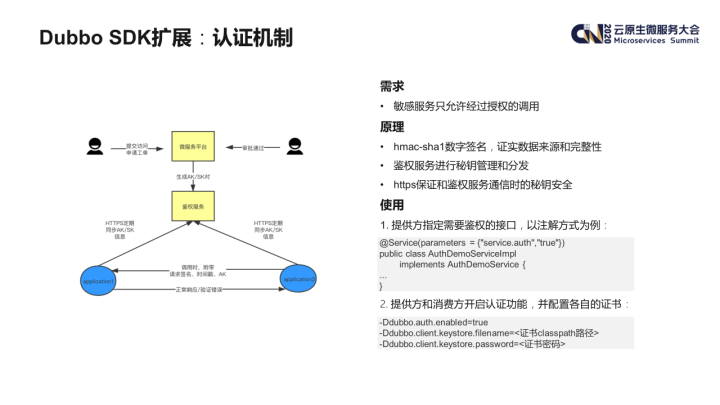
其基本原理是:
- Provider 服务可以通过配置在某个service上开启鉴权;
- 需要访问敏感服务的 Consumer 应用,需要在微服务平台上进行申请,审批后会在这个授权关系上生成一对 AK/SK 并同步至鉴权服务;
- Provider/Consumer 与鉴权服务进行通信,获取相关的 AK/SK,这个过程使用 HTTPS 进行通信;
- Consumer 在发起调用时,会对请求参数等生成一个数字签名,连同时间戳、AK 等信息一起发送给 Provider 端;
- Provider 在收到请求时,会对其数字签名等信息进行核对,确认请求信息的来源及数据的完整性。
以上介绍的是我们针对 Dubbo SDK 的扩展内容,接下来主要介绍我们在微服务生态方面的建设。
2. 生态体系建设
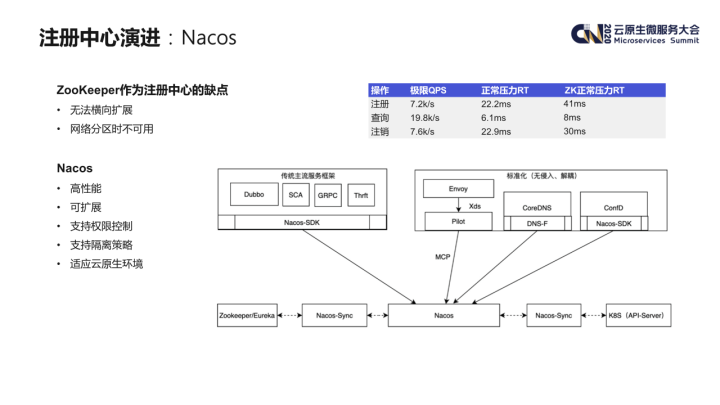
注册中心在微服务应用中是最重要的基础设施之一,在 Dubbo SDK 引入之初,为了快速落地,我们使用了 ZooKeeper 作为注册中心。当然实际上 ZooKeeper 并不是微服务注册中心的最佳选型,它的主要缺点包括:
- 无法横向扩展;
- 作为一个一致性的系统,在网络分区会产生不可用。
1)注册中心演进
在调研了业界的各个方案后,我们选用了 Nacos 作为我们下一代的微服务注册中心。下图右下角是 Nacos 的整体介绍图,选用 Nacos 的主要原因是:
- 高性能,可以横向扩展;
- 既适用于传统为服务架构,也能适用于云原生环境,包括支持与 Istio 控制面对接;
- 提供了 Nacos-Sync 组件,可以用较低的成本进行注册中心的迁移。
在部署 Nacos 服务时,我们充分考虑了服务部署架构方面的高可用性。目前我们的 Nacos 服务是一个大集群,实例分布在多个不同的可用区中,在每个可用区内部,我们会申请不同的 VIP,最终的内网域名是绑定在这些 VIP 上。另外其底层所使用的 MySQL 也采用了多机房部署。这样的架构可以避免单个 Nacos 实例或者单机房故障造成整个 Nacos 服务的不可用。
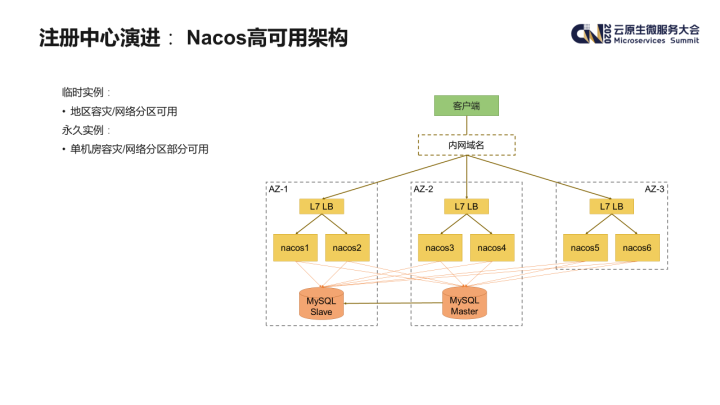
以下是一些可能的故障场景的模拟:
- 单个 Nacos 实例故障:利用 Load Balancer 集群提供的健康检查能力自动从 VIP 中摘除;
- 某个 VIP 集群故障:利用客户端重试机制解决;
- 单个 AZ 故障:利用客户端重试机制解决;
- MySQL 集群故障:MySQL 与注册发现过程无关,不受影响;
- 整个 Nacos 服务故障:客户端兜底机制,如服务实例缓存等。
接下来将简单介绍一下如何使用 Nacos-Sync 进行注册中心的平滑迁移。
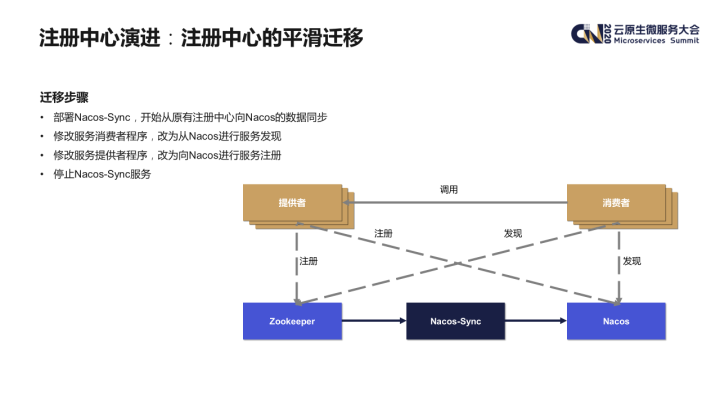
- 首先要部署一个 Nacos-Sync 服务,从旧的注册中心向 Nacos 同步数据。Nacos-Sync 支持集群化部署,部署多个实例时,其向新注册中心的写入时幂等的,并且它原生支持 Dubbo 的注册数据格式;
- 检查数据无误后,首先升级 Consumer 端,改为从 Nacos 注册中心进行发现。这时的服务发现的数据均是由 Nacos-Sync 从旧的注册中心同步过来的;
- 再升级 Provider 端,改为向 Nacos 进行服务注册;
- 下线 Nacos-Sync 服务及旧的注册中心,整个迁移流程就结束了。
2)监控体系建设
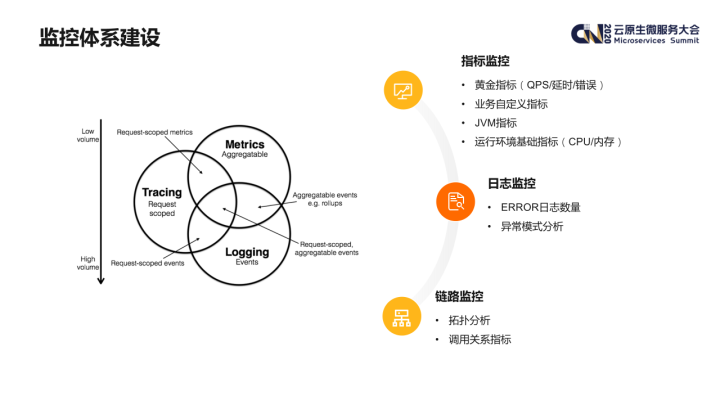
接下来主要介绍我们内部微服务监控体系的建设。完整的微服务监控体系一般由以下 3 个方面组成:
- 指标监控:包括 QPS / 响应延时 / 错误率等黄金指标、业务的自定义指标、JAVA 应用的 JVM 指标,此外还需要采集和基础环境的相关指标,包括 CPU / 内存利用率等;
- 日志监控:如错误日志的数量;也可以利用 AI 技术,对日志的模式进行统计分析等;
- 链路监控:由于微服务调用关系的复杂性,调用链追踪也是非常必要的,它可以帮助业务人员更好地分析应用间的依赖关系,并能够监控各个调用关系上的核心指标。
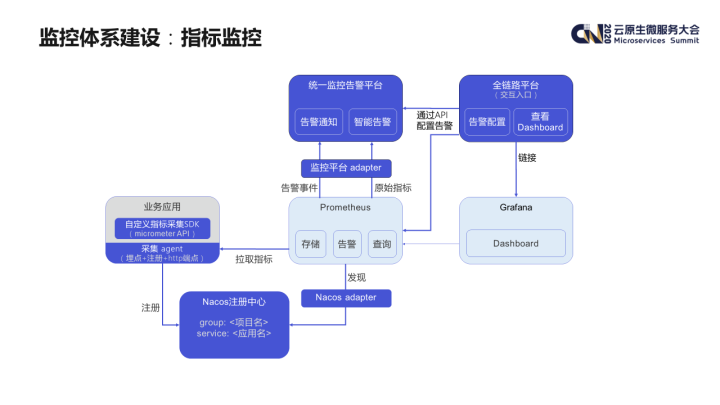
指标监控方面,我们内部围绕着 Prometheus 建设了一套较为完整的监控和告警的方案。这里面要解决几个问题:
首先是指标计算的问题,为了降低侵入性,我们在 skywalking agent 的基础上进行了二次开发,可以自动拦截 Dubbo 的调用,统计其调用次数、处理耗时、是否错误等等。
其次是指标采集的问题,Prometheus 是采用拉模式采集指标的,对于微服务场景一般是利用 Prometheus 的服务发现机制。Prometheus 默认集成了 consul、K8s 等服务发现方式,不过并未对 Nacos 注册中心直接提供支持,我们在开源的 Nacos adapter 的基础上进行了改造,使得 Prometheus 能够从 Nacos 中发现要采集的应用实例信息。
指标查看主要采用了 grafana,我们提供了一套通用化的配置模板,业务也可以根据需要自行扩展。
告警方面,我们将告警策略设置在 Prometheus 中,具体的告警会由 alert-manager 通过 adapter 发送给内部的监控告警平台。
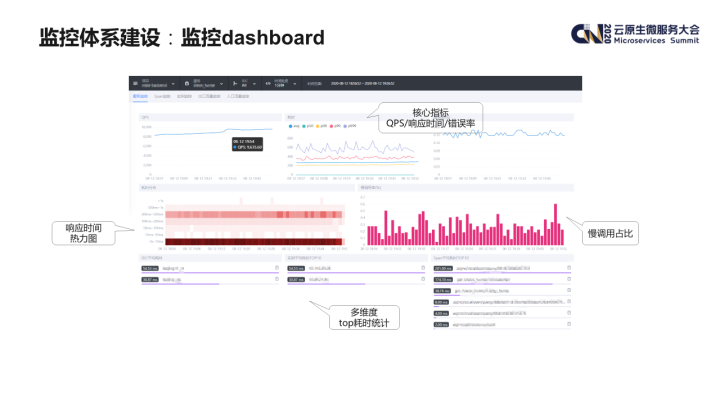
监控 dashboard 查看、告警策略设置、订阅的入口统一设置在我们内部的全链路监控平台上,用户可以在该平台上查看进行相应的操作。
下图展示的是服务监控界面:
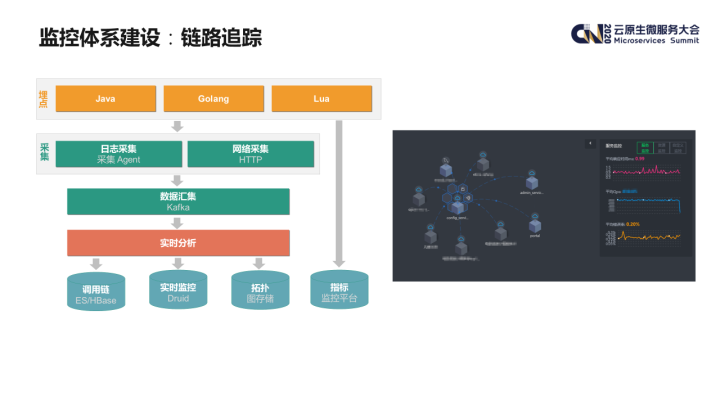
链路追踪的基本原理也和 google 关于 Dapper 的论文一致,应用程序通过埋点的 agent 产生调用链数据,通过日志采集或者网络直接上报的方式统一汇总至 kafka,通过我们的实时分析程序进行分析。
分析结果大致可以分为三类:
- 原始的调用链数据我们会使用 ES+HBase 进行存储;
- 调用关系上的实时监控数据我们采用时序数据库 druid 进行存储;
- 拓扑关系采用图数据存储。
3)熔断限流
最后简单介绍一下利用 sentinel 框架进行熔断和限流的相关内容。
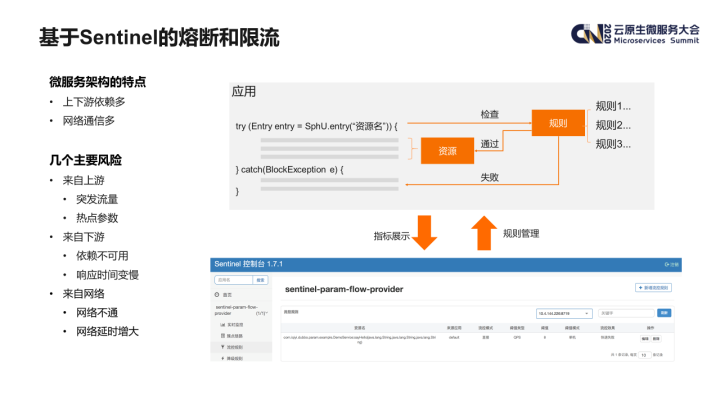
由于微服务架构的特点,上下游依赖和网络通信都比较多,这些因素都会对应用本身产生一定的风险,比如上游系统的突发流量或者热点参数;下游系统服务不可用、延时增大、错误率升高等等。如果缺少对自身系统的保护,有可能产生雪崩的效应。为了应对这些场景,我们主要引入了 Sentinel 框架进行解决。
Sentinel 的核心原理是用户可以定义各类资源(资源可以是本地的一个接口,或者远程的某个依赖),并在资源上设置各种规则(比如限流规则),在访问某个资源时,Sentinel 组件会检查这些规则是否满足,在不满足的情况下会抛出特定的异常。用户可以通过捕捉这些异常实现快速失败或者降级等业务逻辑。Sentinel 还提供了一个控制台,可以用来管理规则的参数设置以及查看实时监控等。

本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java