
大数据实时技术
数据价值是具有时效性的,在一条数据产生的时候,如果不能及时处理并在业务系统中使用,就不能让数据保持最高的“新鲜度”和价值最大化。
相对于离线批处理技术,流式实时处理技术作为一个非常重要的技术补充,在阿里巴巴集团内被广泛使用。
在大数据业界中,流计算技术的研究是近年来非常热门的课题。
业务诉求是希望能在第一时间拿到经过加工后的数据,以便实时监控当前业务状态并做出运营决策,引导业务往好的方向发展。比如网站上一个访问量很高的广告位,需要实时监控广告位的引流效果,如果转化率非常低的话,运营人员就需要及时更换为其他广告,以避免流量资源的浪费。在这个例子中,就需要实时统计广告位的曝光和点击等指标作为运营决策的参考。
按照数据的延迟情况,数据时效性一般分为三种(离线、准实时、实时):
- 离线:在今天(T)处理N天前(T-N,N≥1)的数据,延迟时间粒度为天。
- 准实时:在当前小时(H)处理N小时前(H-N,N>0,如0.5小时、1小时等)的数据,延迟时间粒度为小时。
- 实时:在当前时刻处理当前的数据,延迟时间粒度为秒;
离线和准实时都可以在批处理系统中实现(比如Hadoop、MaxCompute、Spark等系统),只是调度周期不一样而已,而实时数据则需要在流式处理系统中完成。简单来说,流式数据处理技术是指业务系统每产生一条数据,就会立刻被采集并实时发送到流式任务中进行处理,不需要定时调度任务来处理数据。
整体来看,流式数据处理一般具有以下特征。
1.时效性高
数据实时采集、实时处理,延时粒度在秒级甚至毫秒级,业务方能够在第一时间拿到经过加工处理后的数据。
2.常驻任务
区别于离线任务的周期调度,流式任务属于常驻进程任务,一旦启动后就会一直运行,直到人为地终止,因此计算成本会相对比较高。这一特点也预示着流式任务的数据源是无界的,而离线任务的数据源是有界的。这也是实时处理和离线处理最主要的差别,这个特性会导致实时任务在数据处理上有一定的局限性。
3.性能要求高
实时计算对数据处理的性能要求非常严格,如果处理吞吐量跟不上采集吞吐量,计算出来的数据就失去了实时的特性。比如实时任务1分钟只能处理30秒采集的数据,那么产出的数据的延时会越来越长,不能代表当前时刻的业务状态,有可能导致业务方做出错误的运营决策。在互联网行业中,需要处理的数据是海量的,如何在数据量快速膨胀的情况下也能保持高吞吐量和低延时,是当前面临的重要挑战。因此,实时处理的性能优化占了任务开发的很大一部分工作。
4.应用局限性
实时数据处理不能替代离线处理,除了计算成本较大这个因素外,对于业务逻辑复杂的场景(比如双流关联或者需要数据回滚的情况),其局限性导致支持不足。另外,由于数据源是流式的,在数据具有上下文关系的情况下,数据到达时间的不确定性导致实时处理跟离线处理得出来的结果会有一定的差异。
流式技术架构
在流式计算技术中,需要各个子系统之间相互依赖形成一条数据处理链路,才能产出结果最终对外提供实时数据服务。在实际技术选型时,可选的开源技术方案非常多,但是各个方案的整体架构是类似的,只是各个子系统的实现原理不太一样。另外,流式技术架构中的系统跟离线处理是有交叉的,两套技术方案并不是完全独立的,并且在业界中有合并的趋势。
各个子系统按功能划分的话,主要分为以下几部分:
1.数据采集
数据的源头,一般来自于各个业务的日志服务器(例如网站的浏览行为日志、订单的修改日志等),这些数据被实时采集到数据中间件中,供下游实时订阅使用。
2.数据处理
数据被采集到中间件中后,需要下游实时订阅数据,并拉取到流式计算系统的任务中进行加工处理。这里需要提供流计算引擎以支持流式任务的执行。
**3.数据存储
**
数据被实时加工处理(比如聚合、清洗等)后,会写到某个在线服务的存储系统中,供下游调用方使用。这里的写操作是增量操作,并且是源源不断的。
4.数据服务
在存储系统上会架设一层统一的数据服务层(比如提供HSF接口、HTTP服务等),用于获取实时计算结果。
整体技术架构如图所示:
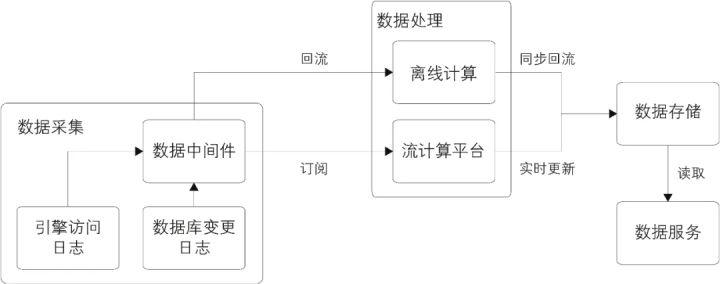
从图可以看出,在数据采集和数据服务部分实时和离线是公用的,因为在这两层中都不需要关心数据的时效性。这样才能做到数据源的统一,避免流式处理和离线处理的不一致。
流式数据模型
在流式计算技术中,需要各个子系统之间相互依赖形成一条数据处理链路,才能产出结果最终对外提供实时数据服务。在实际技术选型时,可选的开源技术方案非常多,但是各个方案的整体架构是类似的,只是各个子系统的实现原理不太一样。另外,流式技术架构中的系统跟离线处理是有交叉的,两套技术方案并不是完全独立的,并且在业界中有合并的趋势。
各个子系统按功能划分的话,主要分为以下几部分:
数据模型设计是贯通数据处理过程的,流式数据处理也一样,需要对数据流建模分层。实时建模跟离线建模非常类似,数据模型整体上分为五层(ODS、DWD、DWS、ADS、DIM)。
由于实时计算的局限性,每一层中并没有像离线做得那么宽,维度和指标也没有那么多,特别是涉及回溯状态的指标,在实时数据模型中几乎没有。
整体来看,实时数据模型是离线数据模型的一个子集,在实时数据处理过程中,很多模型设计就是参考离线数据模型实现的。
1.数据分层
在流式数据模型中,数据模型整体上分为五层。
ODS层:跟离线系统的定义一样,ODS层属于操作数据层,是直接从业务系统采集过来的最原始数据,包含了所有业务的变更过程,数据粒度也是最细的。在这一层,实时和离线在源头上是统一的,这样的好处是用同一份数据加工出来的指标,口径基本是统一的,可以更方便进行实时和离线间数据比对。例如:原始的订单变更记录数据、服务器引擎的访问日志。
DWD层:DWD层是在ODS层基础上,根据业务过程建模出来的实时事实明细层,对于访问日志这种数据(没有上下文关系,并且不需要等待过程的记录),会回流到离线系统供下游使用,最大程度地保证实时和离线数据在ODS层和DWD层是一致的。例如:订单的支付明细表、退款明细表、用户的访问日志明细表。
DWS层:订阅明细层的数据后,会在实时任务中计算各个维度的汇总指标。如果维度是各个垂直业务线通用的,则会放在实时通用汇总层,作为通用的数据模型使用。比如电商网站的卖家粒度,只要涉及交易过程,就会跟这个维度相关,所以卖家维度是各个垂直业务的通用维度,其中的汇总指标也是各个业务线共用的。例如:电商数据的几大维度的汇总表(卖家、商品、买家)。
ADS层:个性化维度汇总层,对于不是特别通用的统计维度数据会放在这一层中,这里计算只有自身业务才会关注的维度和指标,跟其他业务线一般没有交集,常用于一些垂直创新业务中。例如:手机淘宝下面的某个爱逛街、微淘等垂直业务。
DIM层:实时维表层的数据基本上都是从离线维表层导出来的,抽取到在线系统中供实时应用调用。这一层对实时应用来说是静态的,所有的ETL处理工作会在离线系统中完成。维表在实时应用的使用中跟离线稍有区别,后面章节中会详细说明。例如:商品维表、卖家维表、买家维表、类目维表。
2.多流关联
在流式计算中常常需要把两个实时流进行主键关联,以得到对应的实时明细表。在离线系统中两个表关联是非常简单的,因为离线计算在任务启动时已经可以获得两张表的全量数据,只要根据关联键进行分桶关联就可以了。但流式计算不一样,数据的到达是一个增量的过程,并且数据到达的时间是不确定的和无序的,因此在数据处理过程中会涉及中间状态的保存和恢复机制等细节问题。
比如A表和B表使用ID进行实时关联,由于无法知道两个表的到达顺序,因此在两个数据流的每条新数据到来时,都需要到另外一张表中进行查找。如A表的某条数据到达,到B表的全量数据中查找,如果能查找到,说明可以关联上,拼接成一条记录直接输出到下游;但是如果关联不上,则需要放在内存或外部存储中等待,直到B表的记录也到达。多流关联的一个关键点就是需要相互等待,只有双方都到达了,才能关联成功。
下面通过例子(订单信息表和支付信息表关联)来说明,如图示。
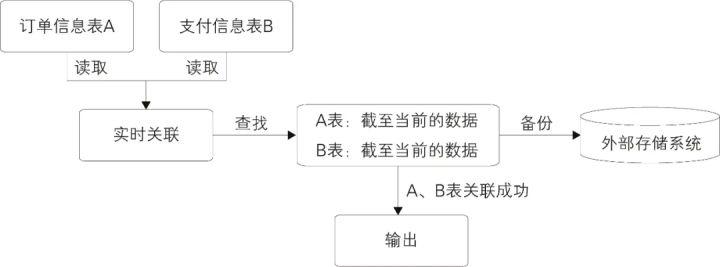
在上面的例子中,实时采集两张表的数据,每到来一条新数据时都在内存中的对方表截至当前的全量数据中查找,如果能查找到,则说明关联成功,直接输出;如果没查找到,则把数据放在内存中的自己表数据集合中等待。另外,不管是否关联成功,内存中的数据都需要备份到外部存储系统中,在任务重启时,可以从外部存储系统中恢复内存数据,这样才能保证数据不丢失。因为在重启时,任务是续跑的,不会重新跑之前的数据。
另外,订单记录的变更有可能发生多次(比如订单的多个字段多次更新),在这种情况下,需要根据订单ID去重,避免A表和B表多次关联成功;否则输出到下游就会有多条记录,这样得到的数据是有重复的。
以上是整体的双流关联流程,在实际处理时,考虑到查找数据的性能,实时关联这个步骤一般会把数据按照关联主键进行分桶处理,并且在故障恢复时也根据分桶来进行,以降低查找数据量和提高吞吐量。
3.维表使用
在离线系统中,一般是根据业务分区来关联事实表和维表的,因为在关联之前维表的数据就已经就绪了。而在实时计算中,关联维表一般会使用当前的实时数据(T)去关联T-2的维表数据,相当于在T的数据到达之前需要把维表数据准备好,并且一般是一份静态的数据。
为什么在实时计算中这么做呢?主要基于以下几点的考虑。
数据无法及时准备好:当到达零点时,实时流数据必须去关联维表(因为不能等待,如果等就失去了实时的特性),而这个时候T-1的维表数据一般不能在零点马上准备就绪(因为T-1的数据需要在T这一天加工生成),因此去关联T-2维表,相当于在T-1的一天时间里加工好T-2的维表数据。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java