
搜索引擎的倒排检索原理
我们知道,百度肯定是有爬虫,到处爬取网页,进行某种处理。然后通过你输入的关键词进行某种计算再返回给你的
我们先来看看什么是某种处理
某种处理
当百度爬取了海量网页后,每一个网页我们称为”文档“,不可能就杂乱无章的放着,它使用了文档集合,就是类似的文档放在一个集合中
那什么样的文档算类似呢?相信你猜到了,文档中有相同关键字的就可以放在一个集合中
来举例说明
假设全世界只有下面5个文档(网页),文档内容也很简单,就一句话(注意是文档内容,不是标题)
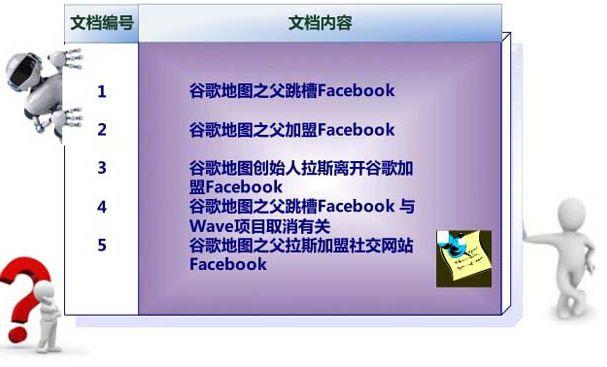
百度爬取后,将他们进行编号,然后对文档进行扫描分词,因为百度内部有词库,匹配上的词将被切分,所以文档1号将被切分为【谷歌,地图,之父,跳槽,FaceBook】,后面的文档也一样,然后对切分出来的单词进行倒排处理,形成倒排列表
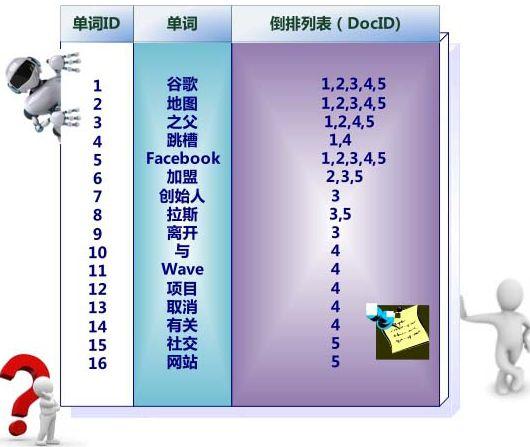
啥是倒排处理?右边这堆杂乱无章的数字咋来的?别急,仔细看,1号单词“谷歌”是不是在1,2,3,4,5号文档都出现过?9号单词“离开”是不是只在3号文档出现过?
是的,倒排列表所做的,就是保存对应单词所出现过的文档编号
我想你开始明白他的目的了,当我们搜索“谷歌”的时候,他就会获得“谷歌”这一单词对应的倒排列表,知道哪些文档包含他,然后将这些文档提取出来返回给你,这就是一种单词映射文档的方法
但是,没那么简单,因为只有这样的话,我在一篇博客上把所有的单词都写上,这样杂乱无章的文章岂不是要被推荐给全体中国人???
所以倒排列表还要保存下列信息
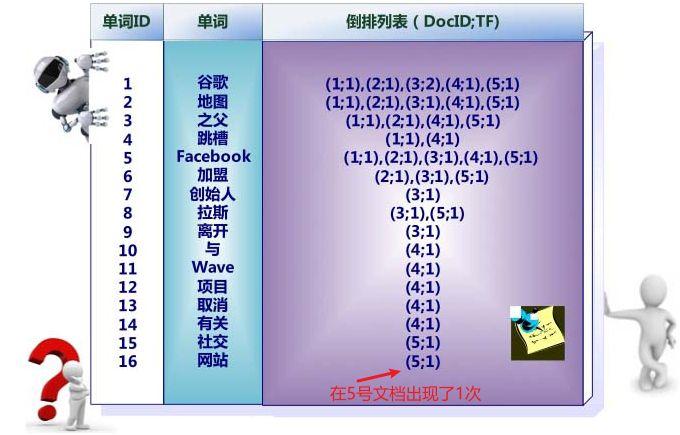
保留的信息变成了二元组,比如16号单词“网站”的(5:1),5表示出现的文档编号,1表示出现的次数,也就是说,有了这个信息,如果一个单词在文档中频率越高(英文缩写TF),搜索引擎就可以把他排在前面推给你
除了频率,还有位置,比如”谷歌“就是在1号文档中出现了一次的单词,位置在第一个,用<1>表示
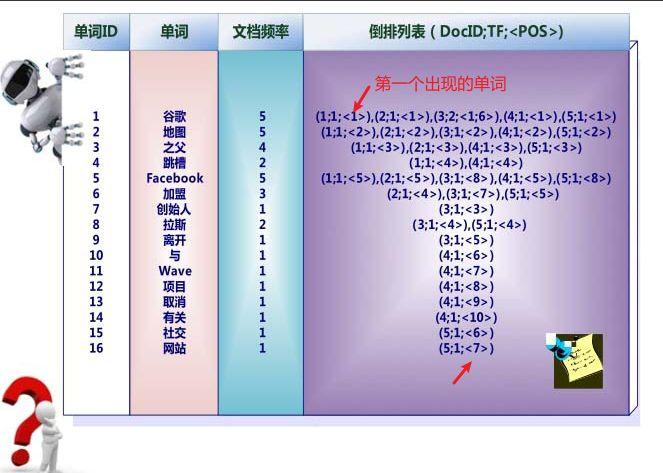
可能到这你有点记不住有哪些网页了,再看一遍比对下
这样子,搜素引擎就可以根据你的关键词在倒排列表中找到含有这个关键词的文档集合,然后根据关键词在文档集合中各个文档出现的频率和位置综合判断返回给你排序后的文档
上句话比较长,加粗部分连在一起读意思不变
实际上很多搜索引擎基本就是这样做的,只不过各家还有别的参考标准,比如百度还会参考热度,你的搜索记录,还有网站给的钱(你懂的)等等综合打分,按评分高低返回搜索结果的排序
上面的所以记录处理好后都会存放在磁盘中,然后等你关键词来后再调入内存
假设世界上只有5个文档,那么上面的东西完全够了,但实际上,世界上有亿万个文档,此时,问题的性质已经变了,不是找不找得到的问题,而是怎么找更快,更准的问题,这需要算法,也就是我们上面提到的某种计算
某种计算
第一个问题就是,词库那么多,当你输入“苹果”的时候,百度如何将你的关键词和他内部倒排列表的“苹果”一词联系起来?
计算机是不认识“苹果”的,这里,可以通过哈希的方法将“苹果”转换为一个编号
所谓哈希,即是将一个词通过某种算法映射为一个符号,比如“将单词转换为其长度”就是一种算法,虽然很low,这样“苹果”就是2,“梨”就是1,不同的哈希算法有不同的转换结果,但是必然会有一个东西——哈希冲突,比如“桃子”也是2,此时,需要使用链表,也称冲突表,将编号相同的单词链在一起
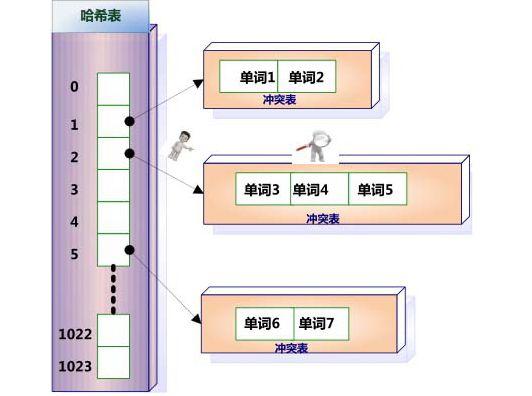
当我们搜索“苹果”的时候,经过哈希计算,得知其编号为2,然后发现2中有一个链表,里面可能保存着“苹果”,”桃子”,“蘑菇”等,然后再遍历链表找到苹果即可
这里和java8中的hashmap思想一致,不过链表也会过长,所以可以使用别的数据结构代替,比如红黑树,b树等
解决了第一个问题,我们就可以通过关键词获得他的Id,然后得到所建立的倒排列表了,比如“谷歌”

第二个问题,由于文档的数量庞大,我们获取的文档往往编号位数都很多,而不像上图那样1,2,3,4,5,导致倒排列表无谓的扩大,所以我们这里进行作差
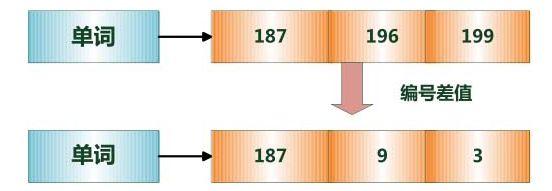
就是后面的文档编号减去前面的,在取文档(从磁盘中读取)的时候加回来即可
第三个问题,如何从磁盘中读取文档
现在我们已经有了倒排列表

可以有两种方法从磁盘中读取文档
两次遍历法
第一遍,扫描文档集合,找到文档数量N, 文档集合内所包含的不同单词数M,和每个单词出现的频率DF(如下图),以及一些别的必要信息,这些东西所占内存加起来,得到需要开辟的内存空间,

同时这个空间是以单词为单位划分,比如“谷歌”一词有5篇文档,
- 第一遍主要就是确定要开辟多大的内存空间来显示文档
- 第二遍扫描,就是边扫描,匹配对应的文档编号(三元组中的第一个数),载入内存
但是这个方法有一个问题,那就是文档集合有多大,内存就有多大,所以,很可能内存会溢出,不过都放在内存中速度也很快,这是一种空间换时间的方法
相信你发现了,但凡涉及到读取,一定有两种以上的方法,空间优先或是时间优先,第二种就是时间换空间——排序法
排序法
现在我们只用固定大小的内存,如何从上图中的倒排列表得知每个单词对应的文章集合所需要的内存空间有多少呢?
我们需要解析文档,构造(单词ID,文档ID,单词频率)三元组,然后进行排序,按单词ID,文档ID,单词频率先后排,最后如果规定的内存满了,就将这些三元组通通写入一个临时文件A中

本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java