
支付宝二维码扫码优化技术方案
一、背景
随着支付宝的线下场景不断扩大,收钱码、口碑、共享单车、充电宝、停车缴费等产品让我们的生活越来越便利。二维码因为成本低、兼容性好成为了线上线上最主要的连接工具,也因此面临更多新的挑战。因为二维码是一种点阵式信息编码方式,任何视觉上的缺损、弯曲以及光线作用都会极大的影响识别成功率,如果识别困难也就意味着用户可能选择放弃,影响支付体验也影响用户心智。
用户扫码体验的最关键的主要有以下几个因素:
1. 识别率:这是扫码服务的基础指标,识别率能直接体现识别能力,识别率如果无法提高意味着大量的用户将无法使用更便捷的服务;
2. 识别耗时:包括 app 启动耗时以及图像识别耗时,这是衡量一个用户从点击 app 到正确识别到内容耗时,每增加 1s,将有相当大量的用户放弃等待并离开;
3. 精准反馈:识别结果不仅需要及时反馈给用户,还需要非常精准,特别是在目前线下有多个二维码的场景下,需要避免用户二次操作;
本文将从以上三个方面,分享支付宝扫码技术团队是如何为用户打造一个又准又快又稳的极致扫码体验。
二、提高识别率
我们对用户反馈进行了大量统计分析,发现绝大部分识别失败都是因为二维码并不标准,并且很遗憾的是在使用我们早期的扫码版本进行识别率测试时发现识别率只有 60%;
策略1:优化桩点查找算法长宽比耐受
以往的扫码算法,检查长宽比例时允许差异 40%,但是由于使用前向误差,判断结果跟长宽的先后顺序相关,这会导致有些长宽比失调的码,横着扫不出来,但是旋转 90 度竖着却能扫出来了(^OMG^)。
<br> (二维码自动识别)
优化策略
- 通过修改长宽比的判定规则,长宽比将不再受先后顺序影响;
- 对于已知长度,修改规则将可接受的宽度范围扩大,增强长宽比的耐受;
在我们对比测试集中,识别率提高了 1% 左右。
策略2:新增1:5:1桩点识别模式模式
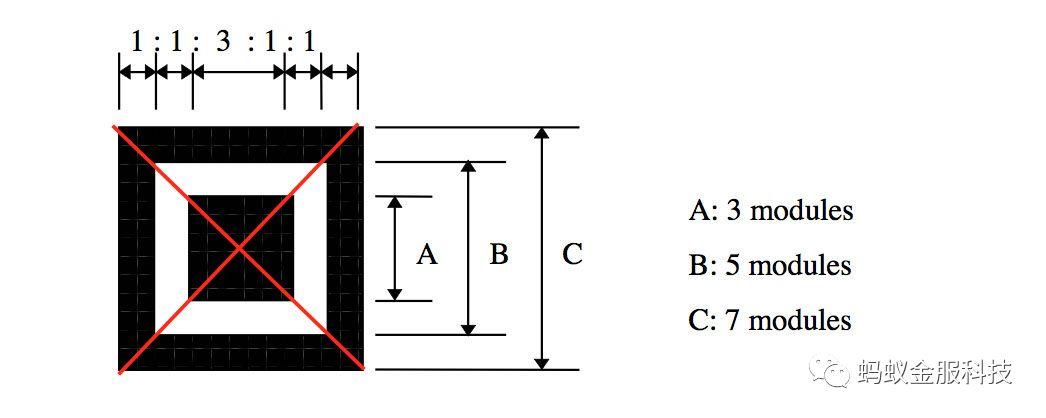
在一张图片中,要找到二维码,关键在找二维码特征定位点:
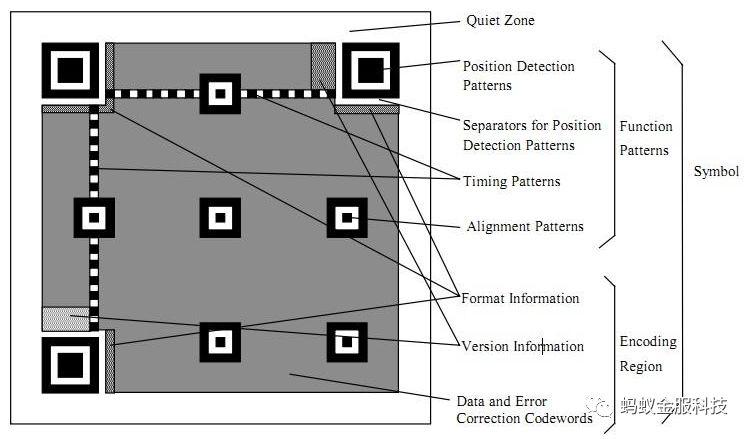
三个角的回字型图案,这就是二维码特征定位点。中间区域的黑白色块比例是1:1:3:1:1
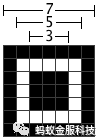
以往的扫码算法,桩点识别是通过状态机 查找11311模式后 取中间位置确定x位置(此时扫描线在第一行11311比例处)在x位置纵向搜索11311模式, 确定y位置再以(x,y)位置横向搜索11311比例,修正x位置。这种模式在桩点污损的情况下,识别能力较差只要在任何一次11311模式搜索中遇到干扰点,哪怕是一个像素的椒盐噪声也能使桩点查找失败。(支付宝蓝的桩点,会在蓝色区域产生大量噪点,导致识别率低下)
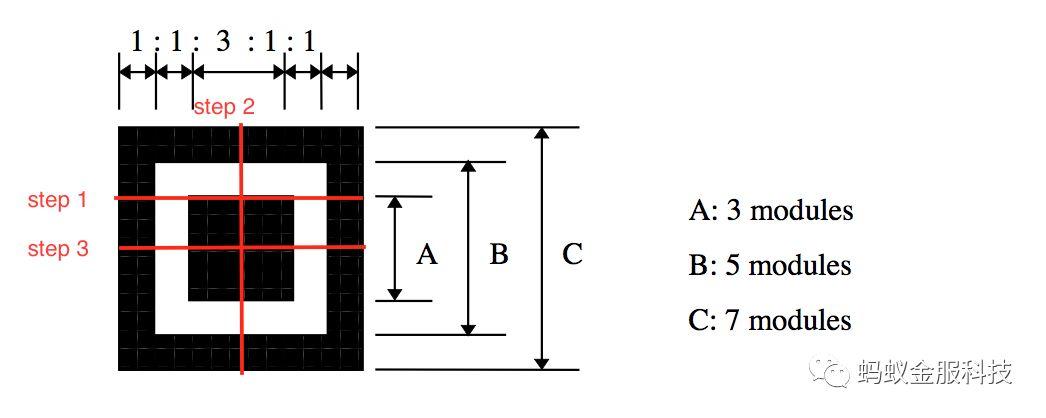
为此,我们新增了一种桩点识别方式。在状态机达到151模式的时候,开始尝试确认桩点。(此时扫描线在第一行151比例处)。
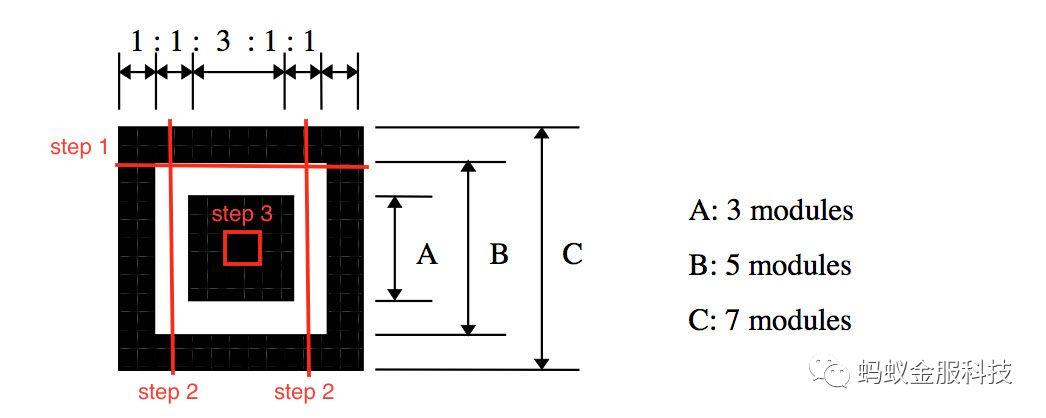
优化效果
- 新的查找方法将不再受桩点中心或边缘部分被污损的影响,支付宝蓝色桩点码识别率明显提升;
- 修改后识别率整体提升了接近 1%,但识别失败的耗时有所提升;
策略3:添加一种对角线过滤规则
在枚举所有可能桩点组合 O(N^3) 之前,对所有可疑桩点进行一次对角线检查过滤。由于桩点对角线也应该满足 11311模式 ,用这个规则做一次过滤可疑有效减少运算量,也就有效降低了识别成功和失败的耗时。
策略4:基于 Logistic Regression 的二维码分类器
在以往的扫码算法中在拿到三个桩点后,基于夹角,长度偏差,单位长度查三个数值,用简单公式计算得到阈值,判断是否为可能的二维码,误判概率较大。
为此,我们引入机器学习中的逻辑回归算法模型。基于支付宝丰富的二维码数据集,训练出逻辑回归模型,作为二维码分类器,明显降低了误判概率,也将明显降低无二维码时识别失败的耗时。
策略5:修改跳行扫描的间隔数
由于输入的相机帧分辨率高,像素点多,运算量大,以往的扫码算法在水平跟垂直方向跳行采样进行计算。但在实际运算中,由于跳过了太多列,错过了11311模式中某些1位置的点,导致桩点查找失败。
我们通过将跳行计算行数修改为可配置项,通过线上 AB 灰度测试得到最合适的跳行策略,整体配置此跳行策略后,识别率得到明显提升。
上述优化在测试集的表现

综上优化,扫码核心识别能力,在7744张图片测试集上提高了6.95个百分点。
特殊策略优化
除此上述通用扫码优化之外,我们还对特殊场景扫码能力进行提高。
1.畸变?不怕不怕!
线下场景复杂多变。饮料瓶身上变形的二维码、超市小票卷起边角弯曲的二维码、路边小贩凹凸不平甚至折叠的二维码......这些畸变的二维码容易增加识别难度,甚至导致识别失败。
以往的扫码算法抗畸变策略中,先用透视变换关系建立映射关系。优点是:适应性好,满足大多数应用场景。不足也明显:对 Version 1 的码,因为映射关系退化为仿射变换,效果较差,手机必须和码平面平行才能方便识别。当物料表面不是平面的时候,效果较差。
优化策略
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java