
开源列式数据库 ClickHouse 初识。
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用:
- 今日头条 内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。
特别值得一提的是:国内云计算的领导厂商阿里云率先推出了自己的ClickHouse托管产品,产品首页地址为云数据库ClickHouse,可以点击链接申请参加免费公测,一睹为快!
在社区方面,github star数目增速惊人。
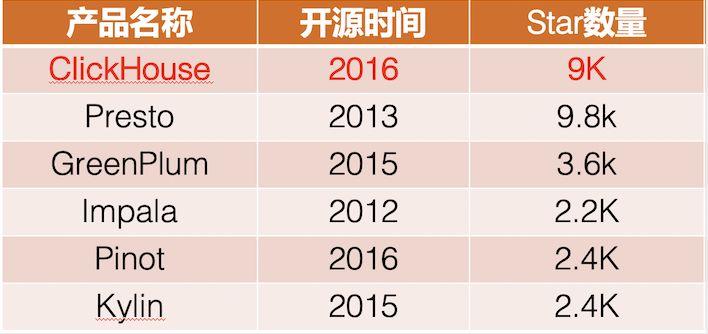
在DB-engines排名上,如下图中红色曲线所示。ClickHouse开源时间虽短,但是增势迅猛。

为何ClickHouse获得了如此广泛的关注,得到了社区的青睐,也得到了诸多大厂的应用呢?本文尝试从技术视角进行回答。
1、OLAP场景的特点
读多于写
不同于事务处理(OLTP)的场景,比如电商场景中加购物车、下单、支付等需要在原地进行大量insert、update、delete操作,数据分析(OLAP)场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。
数据一次性写入后,分析师需要尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息。这是一个需要反复试错、不断调整、持续优化的过程,其中数据的读取次数远多于写入次数。这就要求底层数据库为这个特点做专门设计,而不是盲目采用传统数据库的技术架构。
大宽表,读大量行但是少量列,结果集较小
在OLAP场景中,通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。对数据分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。而聚合计算的结果集相比于动辄数十亿的原始数据,也明显小得多。
数据批量写入,且数据不更新或少更新
OLTP类业务对于延时(Latency)要求更高,要避免让客户等待造成业务损失;而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐(Throughput),要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新、删除操作。
无需事务,数据一致性要求低
OLAP类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。多数OLAP系统都支持最终一致性。
灵活多变,不适合预先建模
分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
2、ClickHouse存储层
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
列式存储
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储。示例图如下:
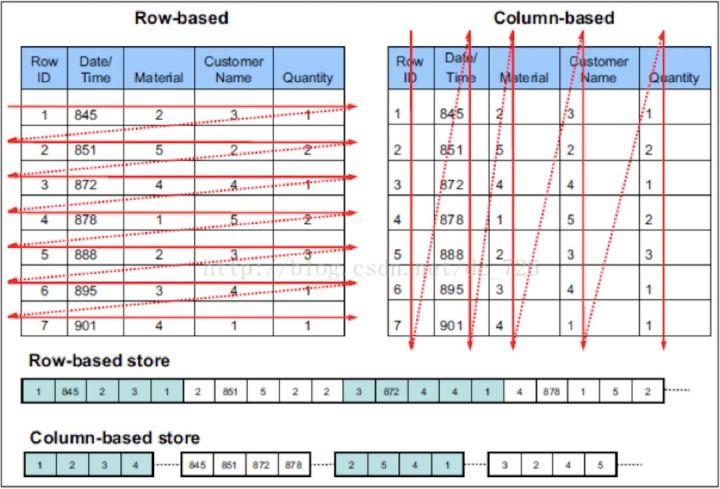
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
- 如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
- 自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
- 高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort
key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block,
大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary
key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL
Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index
granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。目前支持的稀疏索引类型包括:
- minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
- set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
- bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。
ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash
sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local
join;支持自定义sharding,可以为不同业务和SQL
Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding
expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
- 在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点
- 对partition进行TTL管理,淘汰过期的分区数据。
数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
高吞吐写入能力
ClickHouse采用类LSM
Tree的结构,数据写入后定期在后台Compaction。通过类LSM
tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge
sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
有限支持delete、update
在分析场景中,删除、更新操作并不是核心需求。ClickHouse没有直接支持delete、update操作,而是变相支持了mutation操作,语法为alter
table delete where filter_expr, alter table update col=val where
filter_expr。
目前主要限制为删除、更新操作为异步操作,需要后台compation之后才能生效。
主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题
3、ClickHouse计算层
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
多核并行ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略
随机下发:在多个replica中随机选择一个;
- 最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
- in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
- first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized
execution
engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache
miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java