
分布式SQL查询引擎 Presto 性能调优的五大技巧
概述
Presto架构
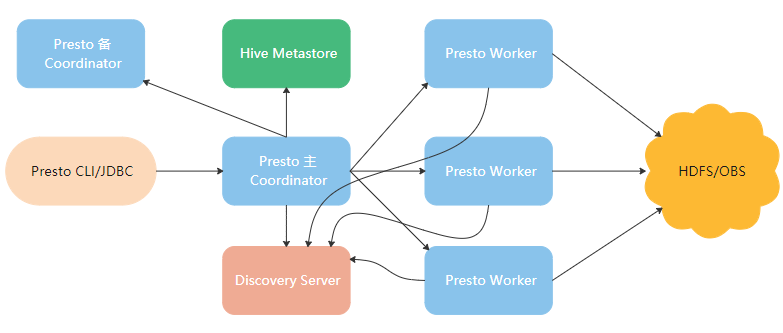
Presto是一个分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。
Presto的架构分为:
Coodinator:解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。
Discovery Server:Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。
Worker:负责执行实际查询任务,访问底层存储系统。
存储:Presto的数据可以存储在HDFS/OBS,推荐热数据存储在HDFS,冷数据存储在OBS。
内存调优
内存管理原理
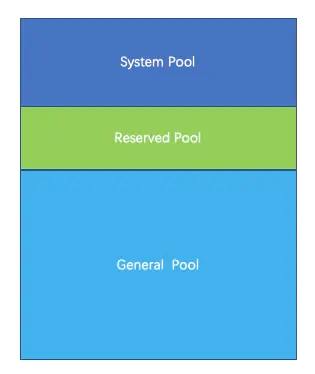
Presto有三种内存池,分别为GENERAL_POOL、RESERVED_POOL、SYSTEM_POOL。
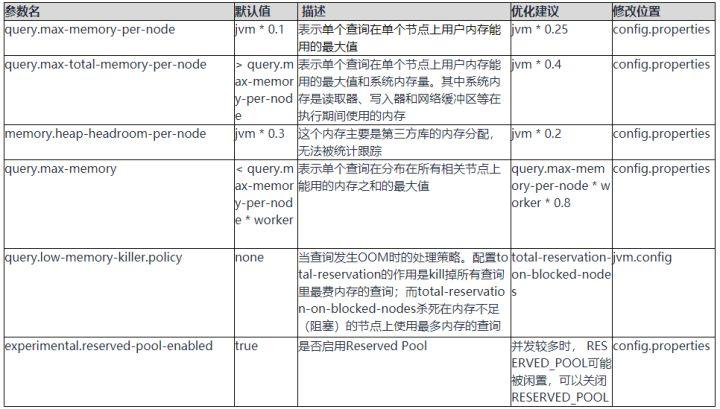
GENERAL_POOL:用于普通查询的physical operators。GENERAL_POOL值为 总内存(Xmx值)- 预留的(max-memory-per-node)- 系统的(0.4 * Xmx)。
SYSTEM_POOL:系统预留内存,用于读写buffer,worker初始化以及执行任务必要的内存。大小由config.properties里的resources.reserved-system-memory指定。默认值为JVM max memory * 0.4。
RESERVED_POOL:大部分时间里是不参与计算的,只有当同时满足如下情形下,才会被使用,然后从所有查询里获取占用内存最大的那个查询,然后将该查询放到 RESERVED_POOL 里执行,同时注意RESERVED_POOL只能用于一个Query。大小由config.properties里的query.max-memory-per-node指定,默认值为:JVM max memory * 0.1。
1、GENERAL_POOL有节点出现阻塞节点(block node)情况,即该node内存不
2、RESERVED_POOL没有被使用
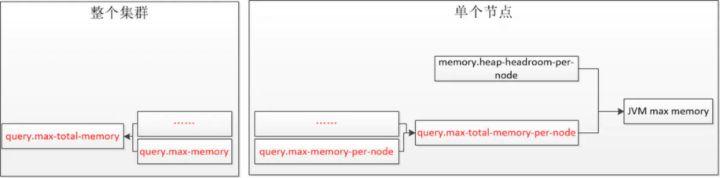
- query.max-memory:表示单个查询在分布在所有相关节点上能用的内存之和的最大值。
- query.max-memory-per-node:表示单个查询在单个节点上用户内存能用的最大值。
- query.max-total-memory-per-node:表示单个查询在单个节点上用户内存能用的最大值和系统内存量。其中系统内存是读取器、写入器和网络缓冲区等在执行期间使用的内存。
- memory.heap-headroom-per-node:这个内存主要是第三方库的内存分配,无法被统计跟踪,默认值是-Xmx * 0.3
注意点:
1、query.max-memory-per-node小于query.max-total-memory-per-node。
2、query.max-total-memory-per-node 与memory.heap-headroom-per-node 之和必须小于 jvm max memory 也就是jvm.config 中配置的-Xmx。
Presto内存配置
内存调优参数
操作场景
Presto由于是完全基于内存的计算,经常出现OOM,需要调整内存。
修改参数
常见OOM报错
Query exceeded per-node total memory limit of xx
适当增加query.max-total-memory-per-node。
Query exceeded distributed user memory limit of xx
适当增加query.max-memory。
Could not communicate with the remote task. The node may have crashed or be under too much load
内存不够,导致节点crash,可以查看/var/log/message。
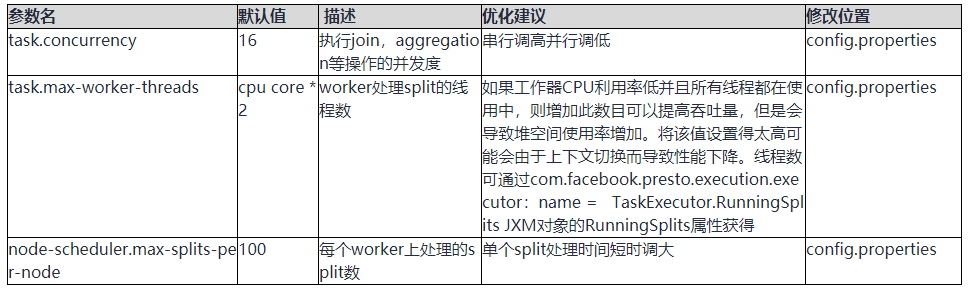
并行度
操作场景
调整线程数增大task的并发以提高效率。
修改参数
元数据缓存
操作场景
Presto支持Hive connector,元数据存储在Hive metastore中,调整元数据缓存的相关参数可以提高访问元数据的效率。
修改参数
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java