
BERT 舆情识别
近来 BERT等大规模预训练模型在 NLP 领域各项子任务中取得了不凡的结果,但是模型海量参数,导致上线困难,不能满足生产需求。舆情审核业务中包含大量的垃圾舆情,会耗费大量的人力。本文在垃圾舆情识别任务中尝试 BERT 蒸馏技术,提升 textCNN 分类器性能,利用其小而快的优点,成功落地。
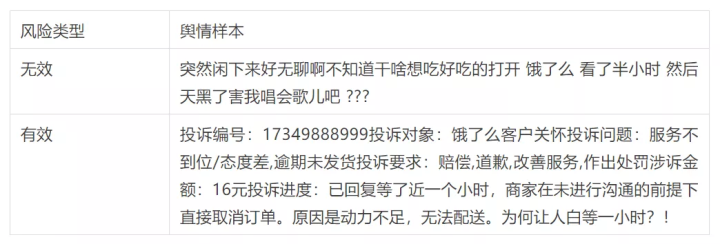
风险样本如下:
一 传统蒸馏方案
目前,对模型压缩和加速的技术主要分为四种:
- 参数剪枝和共享
- 低秩因子分解
- 转移/紧凑卷积滤波器
- 知识蒸馏
知识蒸馏就是将教师网络的知识迁移到学生网络上,使得学生网络的性能表现如教师网络一般。本文主要集中讲解知识蒸馏的应用。
1 soft label
知识蒸馏最早是 2014 年 Caruana 等人提出方法。通过引入 teacher network(复杂网络,效果好,但预测耗时久) 相关的软标签作为总体 loss 的一部分,来引导 student network(简单网络,效果稍差,但预测耗时低) 进行学习,来达到知识的迁移目的。这是一个通用而简单的、不同的模型压缩技术。
- 大规模神经网络 (teacher network)得到的类别预测包含了数据结构间的相似性。
- 有了先验的小规模神经网络(student network)只需要很少的新场景数据就能够收敛。
- Softmax函数随着温度变量(temperature)的升高分布更均匀。
Loss公式如下:
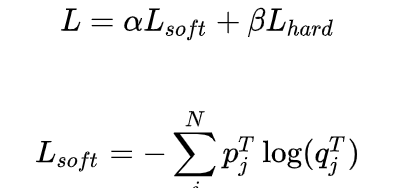
其中,
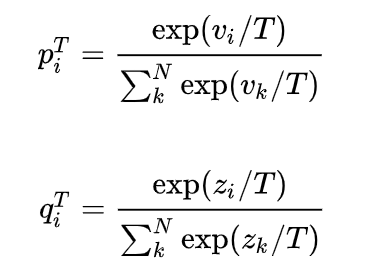
由此我们可以看出蒸馏有以下优点:
- 学习到大模型的特征表征能力,也能学习到one-hot label中不存在的类别间信息。
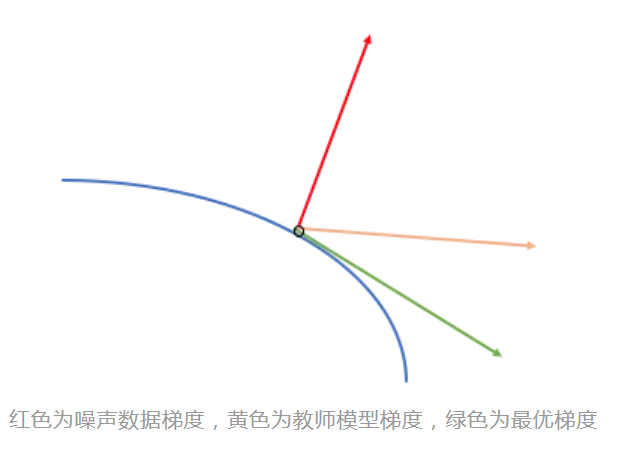
- 具有抗噪声能力,如下图,当有噪声时,教师模型的梯度对学生模型梯度有一定的修正性。
- 一定的程度上,加强了模型的泛化性。
2 using hints
(ICLR 2015) FitNets Romero等人的工作不仅利用教师网络的最后输出logits,还利用了中间隐层参数值,训练学生网络。获得又深又细的FitNets。
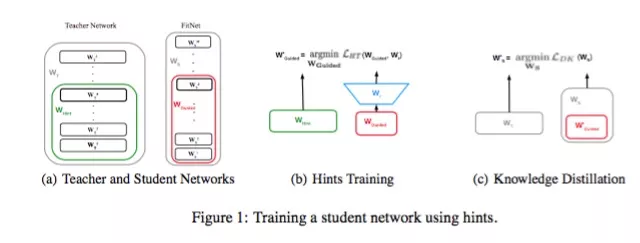
中间层学习loss如下:
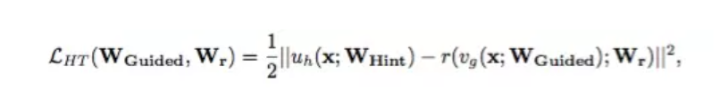
作者通过添加中间层loss的方式,通过teacher network 的参数限制student network的解空间的方式,使得参数的最优解更加靠近到teacher network,从而学习到teacher network的高阶表征,减少网络参数的冗余。
3 co-training
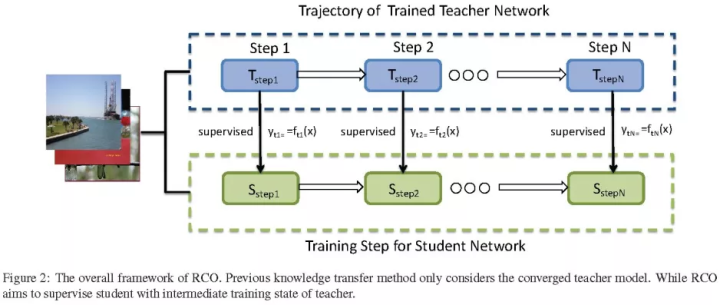
(arXiv 2019) Route Constrained Optimization (RCO) Jin和Peng等人的工作受课程学习(curriculum learning)启发,并且知道学生和老师之间的gap很大导致蒸馏失败,导致认知偏差,提出路由约束提示学习(Route Constrained Hint Learning),把学习路径更改为每训练一次teacher network,并把结果输出给student network进行训练。student network可以一步一步地根据这些中间模型慢慢学习,from easy-to-hard。
训练路径如下图:
二 Bert2TextCNN蒸馏方案
为了提高模型的准确率,并且保障时效性,应对GPU资源紧缺,我们开始构建bert模型蒸馏至textcnn模型的方案。
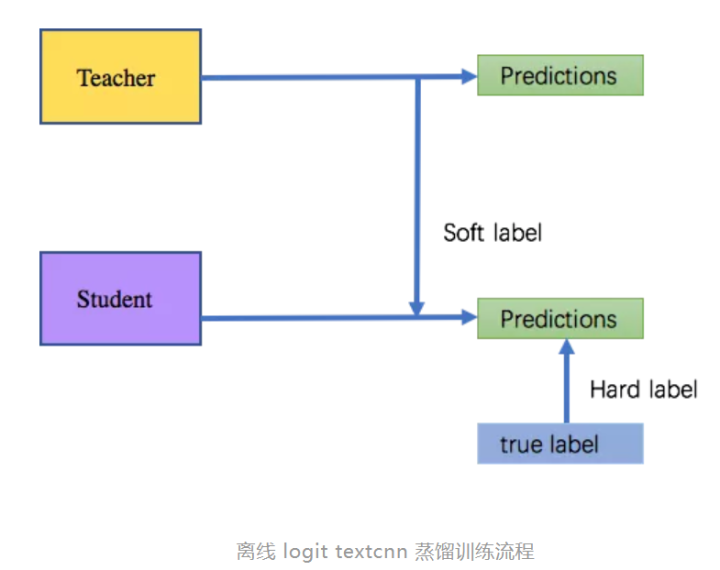
方案1:离线logit textcnn 蒸馏
使用的是Caruana的传统方法进行蒸馏。
方案2:联合训练 bert textcnn 蒸馏
参数隔离:teacher model 训练一次,并把logit传给student。teacher 的参数更新至受到label的影响,student 参数更新受到teacher loigt的soft label loss 和label 的 hard label loss 的影响。
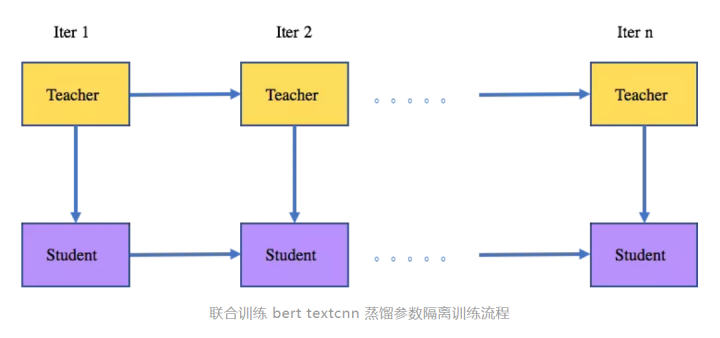
方案3:联合训练 bert textcnn 蒸馏
参数不隔离: 与方案2类似,主要区别在于前一次迭代的student 的 soft label 的梯度会用于teacher参数的更新。
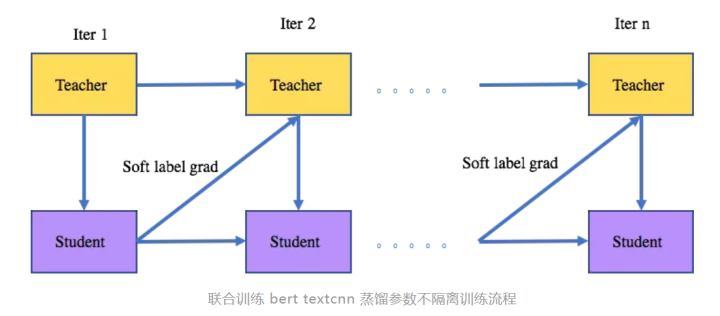
方案4:联合训练 bert textcnn loss 相加
teacher 和student 同时训练,使用mutil-task的方式。
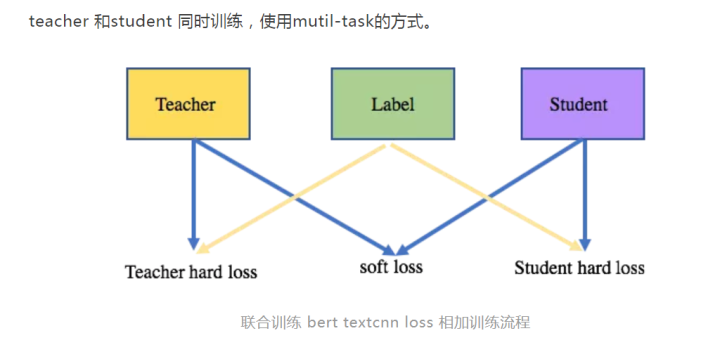
方案5:多teacher
大部分模型,在更新时候需要覆盖线上历史模型的样本,使用线上历史模型作为teacher,让模型学习原有历史模型的知识,保障对原有模型有较高的覆盖。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java