
软件系统问题排查与系统优化手册
一 问题排查
1 常见问题
Know Your Enemy:知己知彼,百战不殆。
日常遇到的大部分问题,大致可以归到如下几类:
- 逻辑缺陷:e.g. NPE、死循环、边界情况未覆盖。
- 性能瓶颈:e.g. 接口 RT 陡增、吞吐率上不去。
- 内存异常:e.g. GC 卡顿、频繁 FGC、内存泄露、OOM
- 并发/分布式:e.g. 存在竞争条件、时钟不同步。
- 数据问题:e.g. 出现脏数据、序列化失败。
- 安全问题:e.g. DDoS 攻击、数据泄露。
- 环境故障:e.g. 宿主机宕机、网络不通、丢包。
- 操作失误:e.g. 配置推错、删库跑路(危险动作,请勿尝试..)。
上述分类可能不太完备和严谨,想传达的点是:你也可以积累一个这样的 checklist,当遇到问题百思不得其解时,耐心过一遍,也许很快就能对号入座。
2 排查流程
医生:小王你看,这个伤口的形状,像不像一朵漂浮的白云?
病人:...再不给我包扎止血,就要变成火烧云了。

快速止血
问题排查的第一步,一定是先把血止住,及时止损。如何快速止血?常见方式包括:
- 发布期间开始报错,且发布前一切正常?啥也别管,先回滚再说,恢复正常后再慢慢排查。
- 应用已经稳定运行很长一段时间,突然开始出现进程退出现象?很可能是内存泄露,默默上重启大法吧。
- 只有少数固定机器报错?试试隔离这部分机器(关闭流量入口)。
- 单用户流量突增导致服务不稳定?如果不是惹不起的金主爸爸,请勇敢推送限流规则。
- 下游依赖挂了导致服务雪崩?还想什么呢,降级预案走起。
保留现场
血止住了?那么恭喜你,至少故障影响不会再扩大了。卸下锅,先喘口气再说。下一步,就是要根据线索找出问题元凶了。作为一名排查老手,你需要有尽量保留现场的意识,例如:
- 隔离一两台机器:将这部分机器入口流量关闭,让它们静静等待你的检阅。
- Dump 应用快照:常用的快照类型一般就是线程堆栈和堆内存映射。
- 所有机器都回滚了,咋办?别慌,如果你的应用监控运维体系足够健全,那么你还有多维度的历史数据可以回溯:应用日志、中间件日志、GC 日志、内核日志、Metrics 指标等。
定位原因
OK,排查线索也有了,接下来该怎么定位具体原因?这个环节会综合考验你的技术深度、业务熟悉度和实操经验,因为原因往往都千奇百怪,需要 case by case 的追踪与分析。这里给出几个排查方向上的建议:
- 关联近期变更:90% 以上的线上问题都是由变更引发,这也是为什么集团安全生产的重点一直是在管控“变更”。所以,先不要急着否认(“肯定不是我刚加的那行代码问题!”),相信统计学概率,好好 review 下近期的变更历史(从近至远)。
- 全链路追踪分析:微服务和中台化盛行的当下,一次业务请求不经过十个八个应用处理一遍,都不好意思说自己是写 Java 的。所以,不要只盯着自己的应用不放,你需要把排查 scope 放大到全链路。
- 还原事件时间线:请把自己想象成福尔摩斯(柯南也行),摆在你面前的就是一个案发现场,你需要做的是把不同时间点的所有事件线索都串起来,重建和还原整个案发过程。要相信,时间戳是不会骗人的。
- 找到 Root Cause:排查问题多了你会发现,很多疑似原因往往只是另一个更深层次原因的表象结果之一。作为福尔摩斯,你最需要找到的是幕后凶手,而不是雇佣的杀人犯 —— 否则 TA 还会雇人再来一次。
- 尝试复现问题:千辛万苦推导出了根因,也不要就急着开始修 bug 了。如果可以,最好能把问题稳定复现出来,这样才更有说服力。这里提醒一点:可千万别在生产环境干这事(除非你真的 know what you're doing),否则搞不好就是二次伤害(你:哈哈哈,你看,这把刀当时就是从这个角度捅进去的,轨迹完全一样。用户:...)。
解决问题
最后,问题根因已经找到,如何完美解决收尾?几个基本原则:
- 修复也是一种变更,需要经过完整的回归测试、灰度发布;切忌火急火燎上线了 bugfix,结果引发更多的 bugs to fix。
- 修复发布后,一定要做线上验证,并且保持观察一段时间,确保是真的真的修复了。
- 最后,如果问题已经上升到了故障这个程度,那就拉上大伙好好做个故障复盘吧。整个处理过程一定还有提升空间,你的经验教训对其他同学来说也是一次很好的输入和自查机会:幸福总是相似的,故障也是。
3 排查工具
手里只有锤子,那看什么都像钉子。作为工程师,你需要的是一整套工具箱。

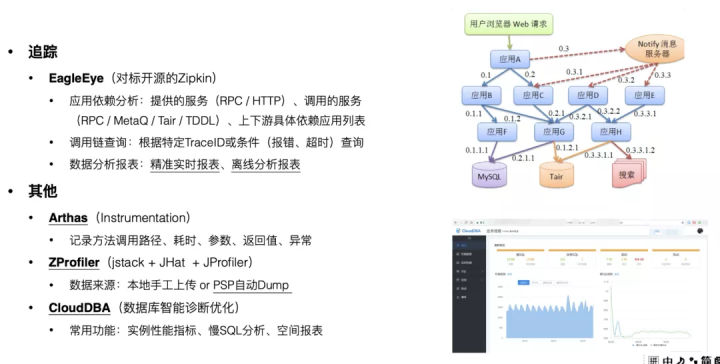
问题排查其实就是一次持续观测应用行为的过程。为了确保不遗漏关键细节,你需要让自己的应用变得更“可观测(Observable)。
提升应用可观测性有三大利器:日志(Logging)、监控(Metrics)、追踪(Tracing)。在我之前所做的项目中,这三块能力分别是由 SLS、Alimonitor / AliMetrics / Tsar、EagleEye 提供的,这里就不再展开描述了。
另外也很推荐 Arthas 这个工具,非常实用和顺手,相信很多同学都已经用过。
二 系统优化
只学会了问题排查还远远不够(当然技能必须点满,shit always happen),再熟练也只是治标不治本。如果想从根源上规避问题,必须从系统本身出发:按照性能、稳定性和可维护性三个方向,持续优化你的系统实现,扼杀问题于摇篮之中,让自己每天都能睡个安稳觉。
老板:既要快,又要稳,还要好。哦,工资的事你别担心,下个月一定能发出来。
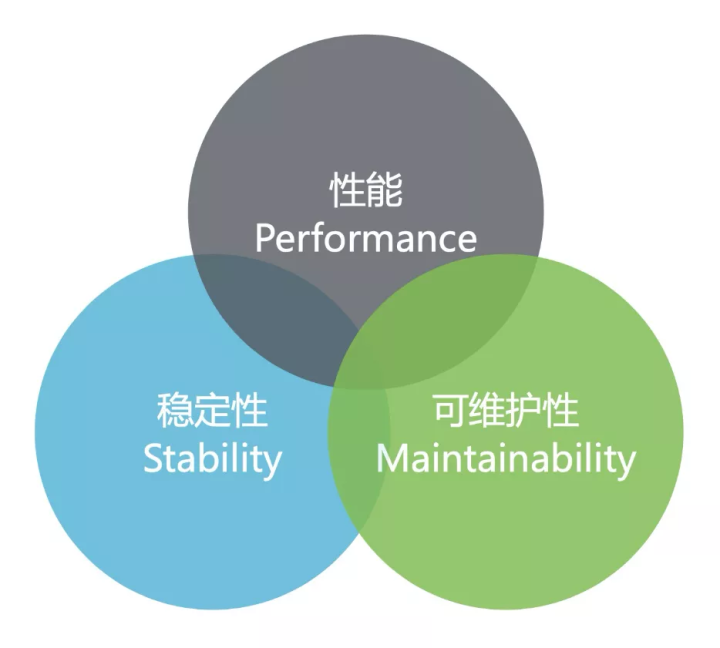
系统优化的三个基本方向:性能(Performance)、稳定性(Stability)、可维护性(Maintainability)。三者之间并不是完全独立的,而是存在着复杂的相互作用关系,有时甚至会此消彼长。
最优秀的软件系统,并非要把这三个方向都做到极致,而是会根据自己实际的业务需求和场景合理取舍,在这三者之间达到一个综合最优的动态平衡状态,让各方面都能做到足够好即可。
所以,优化不只是一门科学,也是一门艺术。
1 性能优化
问:要跑出最快的圈速,是车手重要,还是赛车重要?
答:全都重要。
没有哪个男人会不喜欢高性能跑车,也没有哪个女人会希望在看李佳琦直播时突然卡顿。
性能,是各行各业工程师们共同追求的终极浪漫。
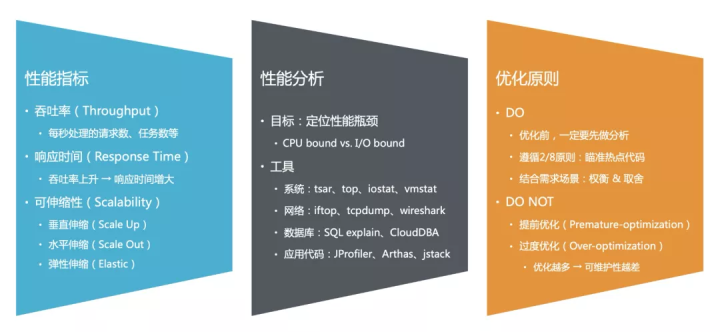
性能指标
指标(Indicators)是衡量一件事物好坏的科学量化手段。对于性能而言,一般会使用如下指标评估:
- 吞吐率(Throughput):系统单位时间内能处理的工作负载,例如:在线 Web 系统 - QPS/TPS,离线数据分析系统 - 每秒处理的数据量。
- 响应时间(Response Time):以 Web 请求处理为例,响应时间(RT)即请求从发出到收到的往返时间,一般会由网络传输延迟、排队延迟和实际处理耗时几个部分共同组成。
- 可伸缩性(Scalability):系统通过增加机器资源(垂直/水平)来承载更多工作负载的能力;投入产出比越高(理想情况是线性伸缩),则说明系统的可伸缩性越好。
此外,同一个系统的吞吐率与响应时间,一般还会存在如下关联关系:吞吐率小于某个临界值时,响应时间几乎不变;一旦超出这个临界值,系统将进入超载状态(overloaded),响应时间开始线性增长。对于一个有稳定性要求的系统,需要在做性能压测和容量规划时充分考虑这个临界值的大小。
注:其实按更严谨的说法,性能就是单指一个系统有多“快”;上述部分指标并不纯粹只代表系统快慢,但也都与快慢息息相关。
性能分析
古人有句老话,If you can't measure it, you can't improve It.
要优化一个系统的性能(例如Web请求响应时间),你必须首先准确地测量和分析出,当前系统的性能究竟差在哪:是请求解析不够快,还是查询 DB 太慢?如果是后者,那又是扫描数据条目阶段太慢,还是返回结果集太慢?或者会不会只是应用与 DB 之间的网络延迟太大?
任何复杂请求的处理过程,最终都可以拆解出一系列并行/串行的原子操作。如果只是逮住哪个就去优化哪个,显然效率不会太高(除非你运气爆棚)。更合理的做法,应该是坚持 2/8 原则:优先分析和优化系统瓶颈,即当前对系统性能影响最大的原子操作;他们很可能就是 ROI 最高的优化点。
具体该如何去量化分析性能?这里列出了一些工具参考:
- 系统层面:tsar、top、iostat、vmstat
- 网络层面:iftop、tcpdump、wireshark
- 数据库层面:SQL explain、CloudDBA
- 应用代码层面:JProfiler、Arthas、jstack
其中很多工具也是问题排查时常用的诊断工具;毕竟,无论是性能分析还是诊断分析,目的都是去理解一个系统和他所处的环境,所需要做的事情都是相似的。
优化原则
你应该做的:上面已经提了很多,这里再补充一点:性能优化与做功能需求一样,都是为业务服务的,因此优化时千万不要忙着自嗨,一定要结合目标需求和应用场景 —— 也许这块你想做的优化,压根线上就碰不到;也许那块很难做的优化,可以根据流量特征做非通用的定制优化。
你不应该做的:即老生常谈的提前优化(Premature-optimization)与过度优化(Over-optimization) —— 通常而言(并不绝对),性能优化都不是免费的午餐,优化做的越多,往往可维护性也会越差。
优化手段
常用的性能优化手段有哪些?我这里总结了 8 个套路(最后 1 个是小霸王多合一汇总套路)。
1)简化
有些事,你可以选择不做。
- 业务层面:e.g. 流程精简、需求简化。
- 编码层面:e.g. 循环内减少高开销操作。
- 架构层面:e.g. 减少没必要的抽象/分层。
- 数据层面:e.g. 数据清洗、提取、聚合。
2)并行
有些事,你可以找人一起做。
方式:单机并行(多线程)、多机并行(分布式)。
优点:充分利用机器资源(多核、集群)。
缺点:同步开销、线程开销、数据倾斜。
- 同步优化:乐观锁、细粒度锁、无锁。
- 线程替代(如协程:Java WISP、Go routines、Kotlin coroutines)。
- 数据倾斜:负载均衡(Hash / RR / 动态)。
3)异步
有些事,你可以放手,不用死等。
方式:消息队列 + 任务线程 + 通知机制。
优点:提升吞吐率、组件解耦、削峰填谷。
缺点:排队延迟(队列积压)。
- 避免过度积压:Back-pressure(Reactive思想)。
4)批量
有些事,你可以合起来一起做。
方式:多次单一操作 → 合并为单次批量操作。
案例:TCP Nagel 算法;DB 的批量读写接口。
优点:避免单次操作的固有开销,均摊后总开销更低。
缺点:等待延迟 + 聚合延迟。
- 减少等待延迟:Timeout 触发提交,控制延迟上限。
5)时间空间互换
游戏的本质:要么有闲,要么有钱。
- 空间换时间:避免重复计算、拉近传输距离、分流减少压力。
案例:缓存、CDN、索引、只读副本(replication)。
- 时间换空间:有时候也能达到“更快”的效果(数据量减少 → 传输时间减少)。
案例:数据压缩(HTTP/2 头部压缩、Bitmap)。
6)数据结构与算法优化
程序 = 数据结构 + 算法
- 多了解一些“冷门”的数据结构 :Skip list、Bloom filter、Time Wheel 等。
- 一些“简单”的算法思想:递归、分治、贪心、动态规划。
7)池化 & 局部化
共享经济 & 小区超市
池化(Pooling):减少资源创建和销毁开销。
- 案例:线程池、内存池、DB 连接池、Socket 连接池。
局部化(Localization):避免共享资源竞争开销。
- 案例:TLB(ThreadLocalBuffer)、多级缓存(本地局部缓存 -> 共享全局缓存)。
8)更多优化手段
- 升级红利:内核、JRE、依赖库、协议。
- 调参大师:配置、JVM、内核、网卡。
- SQL 优化:索引、SELECT *、LIMIT 1。
- 业务特征定制优化:e.g. 凌晨业务低峰期做日志轮转。
- Hybrid 思想(优点结合):JDK sort() 实现、Weex/RN。
2 稳定性优化
稳住,我们能赢。—— by [0 杀 10 死] 正在等待复活的鲁班七号
维持稳定性是我们程序员每天都要思考和讨论的大事。
什么样的系统才算稳定?我自己写了个小工具,本地跑跑从来没出过问题,算稳定吗?淘宝网站几千人维护,但双十一零点还是经常下单失败,所以它不稳定喽?
稳定是相对的,业务规模越大、场景越复杂,系统越容易出现不稳定,且带来的影响也越严重。

衡量指标
不同业务所提供的服务类型千差万别,如何用一致的指标去衡量系统稳定性?标准做法是定义服务的可用性(Availability):只要对用户而言服务“可用”,那就认为系统当前是稳定的;否则就是不稳定。用这样的方式,采集和汇总后就能得到服务总的可用/不可用比例(服务时长 or 服务次数),以此来监测和量化一个系统的稳定性。
可是,通过什么来定义某个服务当前是否可用呢?这一点确实跟业务相关,但大部分同类业务都可以用类似的方式去定义。例如,对于一般的 Web 网站,我们可以按如下方式去定义服务是否可用:API 请求都返回成功,且页面总加载时间 < 3 秒。
对于阿里云对外提供的云产品而言,服务可用性是一个更加需要格外重视并持续提升的指标:阿里云上的很多用户会同时使用多款云产品,其中任何一款产品出现可用性问题,都会直接被用户的用户感知和放大。所以,越是底层的基础设施,可用性要求就越高。关于可用性的更多细节指标和概念(SLI / SLO / SLA),可进一步参考云智能 SLA 了解。
可用性测量
有了上述可用性指标定义后,接下来该如何去准确测量系统的可用性表现?一般有如下两种方式。
1)探针模拟
从客户端侧,模拟用户的调用行为。
- 优点:数据真实(客户端角度)
- 缺点:数据不全面(单一客户数据)
2)服务端采集
从服务端侧,直接分析日志和数据。
- 优点:覆盖所有调用数据。
- 缺点:缺失客户端链路数据。
对可用性数据要求较高的系统,也可以同时运用上述两种方式,建议结合你的业务场景综合评估选择。
优化原则
你应该做的:关注 RT 的数据分布(如:p50/p99/p999 分位点),而不是平均值(mean) —— 平均值并没有太大意义,更应该去关注你那 1%、0.1% 用户的准确感受。
你不应该做的:不要尝试承诺和优化可用性到 100% —— 一方面是无法实现,存在太多客观不可控因素;另一方面也没有意义,客户几乎关注不到 0.001% 的可用性差别。
优化手段
常用的稳定性优化手段有哪些?这里也总结了 8 个套路:
1)避免单点
父母:一个人在外漂了这么多年,也该找个人稳定下来了。
如何避免?
- 集群部署
- 数据副本
- 多机房容灾
只堆量不够,还需要具备故障转移能力(Failover)。
- 接入层:DNS、VipServer、SLB。
- 服务层:服务发现 + 健康检查 + 剔除机制。
- 应用层:无状态设计(Stateless),便于随时和快速切换。
2)流控/限流
计划生育、上学调剂、车牌限号、景区限行... 人生处处被流控。
- 类型:QPS 流控、并发度流控。
- 工具:RateLimiter、信号量、Sentinel。
- 粒度:全局、用户级、接口级。
- 热点流控:避免意料之外的突增流量。
3)熔断
上午买的股票熔断,晚上家里保险丝熔断... 淡定,及时止损而已。
- 目的:防止连锁故障(雪崩效应)。
- 工具:Hystrix、Failsafe、Resilience4j。
- 功能:自动绕开异常服务并检测恢复状态。
- 流程:关闭 → 打开 → 半开。
4)降级
没时间做饭了,今天就吃外卖吧... 对于健康问题,还是得少一点降级。
触发原因:流控、熔断、负载过高。
常见降级方式:
- 关闭非核心功能:停止应用日志打印
- 牺牲数据时效性:返回缓存中旧数据
- 牺牲数据精确性:降低数据采样频率
5)超时/重试
钉钉不回怎么办?每 10 分钟 ping 一次,超过 1 小时打电话。
超时:避免调用端陷入永久阻塞。
- 超时时间设置:全链路自上而下规划
- Timeout vs. Deadline:使用绝对时间会更好
重试:确保可重试操作的幂等性。
- 消息去重
- 异步重试
- 指数退避
6)资源设限
双 11 如何避免女友败家?提前把自己信用卡额度调低。
- 目的:防止资源被异常流量耗尽
- 资源类型:线程、队列、DB 连接
- 设限方式:资源池化、有界队列
- 超限处理:返回 ServiceUnavailable / QuotaExceeded
7)资源隔离
双 12 女友还是要败家?得嘞刷你自个的卡吧,别动我的。
- 目的:防止资源被部分异常流量耗尽;为 VIP 客户提供服务质量保证(QoS)。
- 隔离方式:队列划分、独立集群;注意处理优先级和资源分配比例。
8 )安全生产
女友哭着说再让我最后剁一次手吧?安全第一,宁愿心疼也不要肉疼。
程序动态性:开关、配置、热升级。
- Switch:类型安全;侵入性小。
审核机制:代码 Review、发布审批。
灰度发布;分批部署;回滚预案。
- DUCT:自动/手动调整 HSF 节点权重。
可维护性优化
前人栽树,后人乘凉。
前人挖坑,后人凉凉。
维护的英文是 maintain,也能翻译成:维持、供给。所以软件维护能有多重要?它就是软件系统的呼吸机和食物管道,维持软件生命的必要供给。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java