
BERT在美团搜索核心排序的探索和实践
引言
美团搜索是美团App上最大的连接人和服务的入口,覆盖了团购、外卖、电影、酒店、买菜等各种生活服务。随着用户量快速增长,越来越多的用户在不同场景下都会通过搜索来获取自己想要的服务。理解用户Query,将用户最想要的结果排在靠前的位置,是搜索引擎最核心的两大步骤。但是,用户输入的Query多种多样,既有商户名称和服务品类的Query,也有商户别名和地址等长尾的Query,准确刻画Query与Doc之间的深度语义相关性至关重要。基于Term匹配的传统相关性特征可以较好地判断Query和候选Doc的字面相关性,但在字面相差较大时,则难以刻画出两者的相关性,比如Query和Doc分别为“英语辅导”和“新东方”时两者的语义是相关的,使用传统方法得到的Query-Doc相关性却不一致。
2018年底,以Google BERT[1]为代表的预训练语言模型刷新了多项NLP任务的最好水平,开创了NLP研究的新范式:即先基于大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成下游的NLP任务(文本分类、序列标注、句间关系判断和机器阅读理解等)。美团AI平台搜索与NLP部算法团队基于美团海量业务语料训练了MT-BERT模型,已经将MT-BERT应用到搜索意图识别、细粒度情感分析、点评推荐理由、场景化分类等业务场景中[2]。
作为BERT的核心组成结构,Transformer具有强大的文本特征提取能力,早在多项NLP任务中得到了验证,美团搜索也基于Transformer升级了核心排序模型,取得了不错的研究成果[3]。
BERT简介
近年来,以BERT为代表的预训练语言模型在多项 NLP 任务上都获得了不错的效果。下图1简要回顾了预训练语言模型的发展历程。2013年,Google提出的 Word2vec[4]通过神经网络预训练方式来生成词向量(Word Embedding),极大地推动了深度自然语言处理的发展。针对Word2vec生成的固定词向量无法解决多义词的问题,2018年,Allen AI团队提出基于双向LSTM网络的ELMo[5]。ELMo根据上下文语义来生成动态词向量,很好地解决了多义词的问题。2017年底,Google提出了基于自注意力机制的Transformer[6]模型。
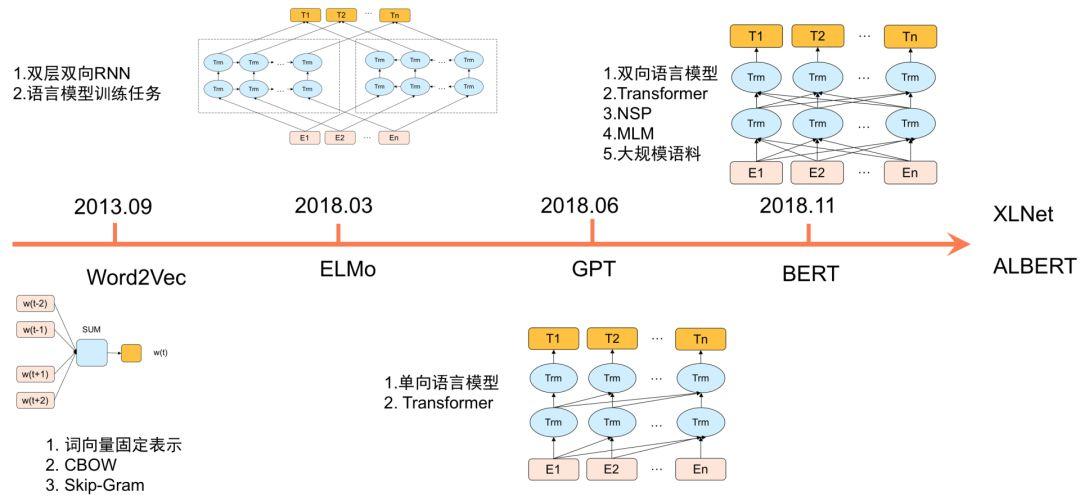
相比RNN模型,Transformer语义特征提取能力更强,具备长距离特征捕获能力,且可以并行训练,在机器翻译等NLP任务上效果显著。Open AI团队的GPT[7]使用Transformer替换RNN进行深层单向语言模型预训练,并通过在下游任务上Fine-tuning验证了Pretrain-Finetune范式的有效性。在此基础上,Google BERT引入了MLM(Masked Language Model)及NSP(Next Sentence Prediction,NSP)两个预训练任务,并在更大规模语料上进行预训练,在11项自然语言理解任务上刷新了最好指标。BERT的成功启发了大量后续工作,总结如下:
- 融合更多外部知识的百度ERNIE[8], 清华ERNIE[9]和K-BERT[10]等;
- 优化预训练目标的ERNIE 2.0[11],RoBERTa[12],SpanBERT[13],StructBERT[14]等;
- 优化模型结构或者训练方式的ALBERT[15]和ELECTRA[16]。关于预训练模型的各种后续工作,可以参考复旦大学邱锡鹏老师最近的综述[17],本文不再赘述。
基于预训练好的BERT模型可以支持多种下游NLP任务。BERT在下游任务中的应用主要有两种方式:即Feature-based和Finetune-based。其中Feature -based方法将BERT作为文本编码器获取文本表示向量,从而完成文本相似度计算、向量召回等任务。而Finetune-based方法是在预训练模型的基础上,使用具体任务的部分训练数据进行训练,从而针对性地修正预训练阶段获得的网络参数。该方法更为主流,在大多数任务上效果也更好。
由于BERT在NLP任务上的显著优势,一些研究工作开始将BERT应用于文档排序等信息检索任务中。清华大学Qiao等人[18]详细对比了Feature-based和Finetune-based两种应用方式在段落排序(Passage Ranking)中的效果。滑铁卢大学Jimmy Lin团队[19]针对文档排序任务提出了基于Pointwise和Pairwise训练目标的MonoBERT和DuoBERT模型。此外,该团队[20]提出融合基于BERT的Query-Doc相关性和Query-Sentence相关性来优化文档排序任务的方案。为了优化检索性能和效果,Bing广告团队[21]提出一种双塔结构的TwinBERT分别编码Query和Doc文本。2019年10月,Google在其官方博客介绍了BERT在Google搜索排序和精选摘要(Featured Snippet)场景的应用,BERT强大的语义理解能力改善了约10%的Google搜索结果[22],除了英文网页,Google也正在基于BERT优化其他语言的搜索结果。值得一提的是美团AI平台搜索与NLP部在WSDM Cup 2020检索排序评测任务中提出了基于Pairwise模式的BERT排序模型和基于LightGBM的排序模型,取得了榜单第一名的成绩[23]。
搜索相关性
美团搜索场景下相关性任务定义如下:给定用户Query和候选Doc(通常为商户或商品),判断两者之间相关性。搜索Query和Doc的相关性直接反映结果页排序的优劣,将相关性高的Doc排在前面,能提高用户搜索决策效率和搜索体验。为了提升结果的相关性,我们在召回、排序等多个方面做了优化,本文主要讨论在排序方面的优化。通过先对Query和Doc的相关性进行建模,把更加准确的相关性信息输送给排序模型,从而提升排序模型的排序能力。Query和Doc的相关性计算是搜索业务核心技术之一,根据计算方法相关性主要分为字面相关性和语义相关性。
字面相关性
早期的相关性匹配主要是根据Term的字面匹配度来计算相关性,如字面命中、覆盖程度、TFIDF、BM25等。字面匹配的相关性特征在美团搜索排序模型中起着重要作用,但字面匹配有它的局限,主要表现在:
- 词义局限:字面匹配无法处理同义词和多义词问题,如在美团业务场景下“宾馆”和“旅店”虽然字面上不匹配,但都是搜索“住宿服务”的同义词;而“COCO”是多义词,在不同业务场景下表示的语义不同,可能是奶茶店,也可能是理发店。
- 结构局限:“蛋糕奶油”和“奶油蛋糕”虽词汇完全重合,但表达的语义完全不同。 当用户搜“蛋糕奶油”时,其意图往往是找“奶油”,而搜“奶油蛋糕”的需求基本上都是“蛋糕”。
语义相关性
为了解决上述问题,业界工作包括传统语义匹配模型和深度语义匹配模型。传统语义匹配模型包括:
- 隐式模型:将Query、Doc都映射到同一个隐式向量空间,通过向量相似度来计算Query-Doc相关性,例如使用主题模型LDA[24]将Query和Doc映射到同一向量空间;
- 翻译模型:通过统计机器翻译方法将Doc进行改写后与Query进行匹配[25]。
这些方法弥补了字面匹配方法的不足,不过从实际效果上来看,还是无法很好地解决语义匹配问题。随着深度自然语言处理技术的兴起,基于深度学习的语义匹配方法成为研究热点,主要包括基于表示的匹配方法(Representation-based)和基于交互的匹配方法(Interaction-based)。
基于表示的匹配方法:使用深度学习模型分别表征Query和Doc,通过计算向量相似度来作为语义匹配分数。微软的DSSM[26]及其扩展模型属于基于表示的语义匹配方法,美团搜索借鉴DSSM的双塔结构思想,左边塔输入Query信息,右边塔输入POI、品类信息,生成Query和Doc的高阶文本相关性、高阶品类相关性特征,应用于排序模型中取得了很好的效果。此外,比较有代表性的表示匹配模型还有百度提出 SimNet[27],中科院提出的多视角循环神经网络匹配模型(MV-LSTM)[28]等。
基于交互的匹配方法:这种方法不直接学习Query和Doc的语义表示向量,而是在神经网络底层就让Query和Doc提前交互,从而获得更好的文本向量表示,最后通过一个MLP网络获得语义匹配分数。代表性模型有华为提出的基于卷积神经网络的匹配模型ARC-II[29],中科院提出的基于矩阵匹配的的层次化匹配模型MatchPyramid[30]。
基于表示的匹配方法优势在于Doc的语义向量可以离线预先计算,在线预测时只需要重新计算Query的语义向量,缺点是模型学习时Query和Doc两者没有任何交互,不能充分利用Query和Doc的细粒度匹配信号。基于交互的匹配方法优势在于Query和Doc在模型训练时能够进行充分的交互匹配,语义匹配效果好,缺点是部署上线成本较高。
BERT语义相关性
BERT预训练使用了大量语料,通用语义表征能力更好,BERT的Transformer结构特征提取能力更强。中文BERT基于字粒度预训练,可以减少未登录词(OOV)的影响,美团业务场景下存在大量长尾Query(如大量数字和英文复合Query)字粒度模型效果优于词粒度模型。此外,BERT中使用位置向量建模文本位置信息,可以解决语义匹配的结构局限。综上所述,我们认为BERT应用在语义匹配任务上会有更好的效果,基于BERT的语义匹配有两种应用方式:
- Feature-based:属于基于表示的语义匹配方法。类似于DSSM双塔结构,通过BERT将Query和Doc编码为向量,Doc向量离线计算完成进入索引,Query向量线上实时计算,通过近似最近邻(ANN)等方法实现相关Doc召回。
- Finetune-based:属于基于交互的语义匹配方法,将Query和Doc对输入BERT进行句间关系Fine-tuning,最后通过MLP网络得到相关性分数。
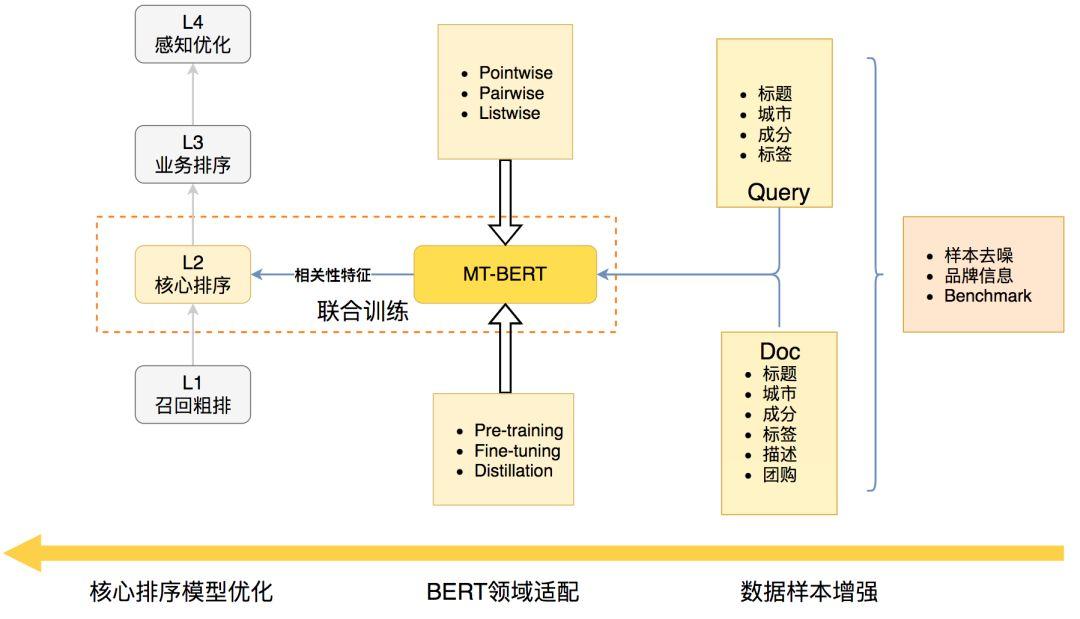
Feature-based方式是经过BERT得到Query和Doc的表示向量,然后计算余弦相似度,所有业务场景下Query-Doc相似度都是固定的,不利于适配不同业务场景。此外,在实际场景下为海量Doc向量建立索引存储成本过高。因此,我们选择了Finetune-based方案,利用搜索场景中用户点击数据构造训练数据,然后通过Fine-tuning方式优化Query-Doc语义匹配任务。图2展示了基于BERT优化美团搜索核心排序相关性的技术架构图,主要包括三部分:
- 数据样本增强:由于相关性模型的训练基于搜索用户行为标注的弱监督数据,我们结合业务经验对数据做了去噪和数据映射。为了更好地评价相关性模型的离线效果,我们构建了一套人工标注的Benchmark数据集,指导模型迭代方向。
- BERT领域适配:美团业务场景中,Query和Doc以商户、商品、团购等短文本为主,除标题文本以外,还存在商户/商品描述、品类、地址、图谱标签等结构化信息。我们首先改进了MT-BERT预训练方法,将品类、标签等文本信息也加入MT-BERT预训练过程中。在相关性Fine-tuning阶段,我们对训练目标进行了优化,使得相关性任务和排序任务目标更加匹配,并进一步将两个任务结合进行联合训练。此外,由于BERT模型前向推理比较耗时,难以满足上线要求,我们通过知识蒸馏将12层BERT模型压缩为符合上线要求的2层小模型,且无显著的效果损失。
- 排序模型优化:核心排序模型(本文记为L2模型)包括LambdaDNN[31]、TransformerDNN[3]、MultiTaskDNN等深度学习模型。给定,我们将基于BERT预测的Query-Doc相关性分数作为特征用于L2模型的训练中。
算法探索
数据增强
BERT Fine-tuning任务需要一定量标注数据进行迁移学习训练,美团搜索场景下Query和Doc覆盖多个业务领域,如果采用人工标注的方法为每个业务领域标注一批训练样本,时间和人力成本过高。我们的解决办法是使用美团搜索积累的大量用户行为数据(如浏览、点击、下单等), 这些行为数据可以作为弱监督训练数据。在DSSM模型进行样本构造时,每个Query下抽取1个正样本和4个负样本,这是比较常用的方法,但是其假设Query下的Doc被点击就算是相关的,这个假设在实际的业务场景下会给模型引入一些噪声。
此处以商家(POI)搜索为例,理想情况下如果一个POI出现在搜索结果里,但是没有任何用户点击,可认为该POI和Query不相关;如果该POI有点击或下单行为,可认为该POI和Query相关。下单行为数据是用户“用脚投票”得来的,具有更高的置信度,因此我们使用下单数据作为正样本,使用未点击过的数据构造负样本,然后结合业务场景对样本进一步优化。数据优化主要包括对样本去噪和引入品牌数据两个方面。此外,为了评测算法离线效果,我们从构造样本中随机采样9K条样本进行了人工标注作为Benchmark数据集。
样本去噪
无意义单字Query过滤。由于单字Query表达的语义通常不完整,用户点击行为也比较随机,如<优,花漾星球专柜(中央大道倍客优)>,这部分数据如果用于训练会影响最终效果。我们去除了包含无意义单字Query的全部样本。
正样本从用户下单的POI中进行随机采样,且过滤掉Query只出现在POI的分店名中的样本,如<大润发,小龙坎老火锅(大润发店)>,虽然Query和POI字面匹配,但其实是不相关的结果。
负样本尝试了两种构造方法:全局随机负采样和Skip-Above采样。
- 全局随机负采样:用户没有点击的POI进行随机采样得到负例。我们观察发现随机采样同样存在大量噪声数据,补充了两项过滤规则来过滤数据。① 大量的POI未被用户点击是因为不是离用户最近的分店,但POI和Query是相关的,这种类型的样例需要过滤掉,如<蛙小侠 ,蛙小侠(新北万达店)>。② 用户Query里包含品牌词,并且POI完全等同于品牌词的,需要从负样本中过滤,如<德克士吃饭 ,德克士>。
- Skip-Above采样:受限于App搜索场景的展示屏效,无法保证召回的POI一次性得到曝光。若直接将未被点击的POI作为负例,可能会将未曝光但相关的POI错误地采样为负例。为了保证训练数据的准确性,我们采用Skip-Above方法,剔除这些噪音负例,即从用户点击过的POI之上没有被点击过的POI中采样负例(假设用户是从上往下浏览的POI)。
品牌样本优化
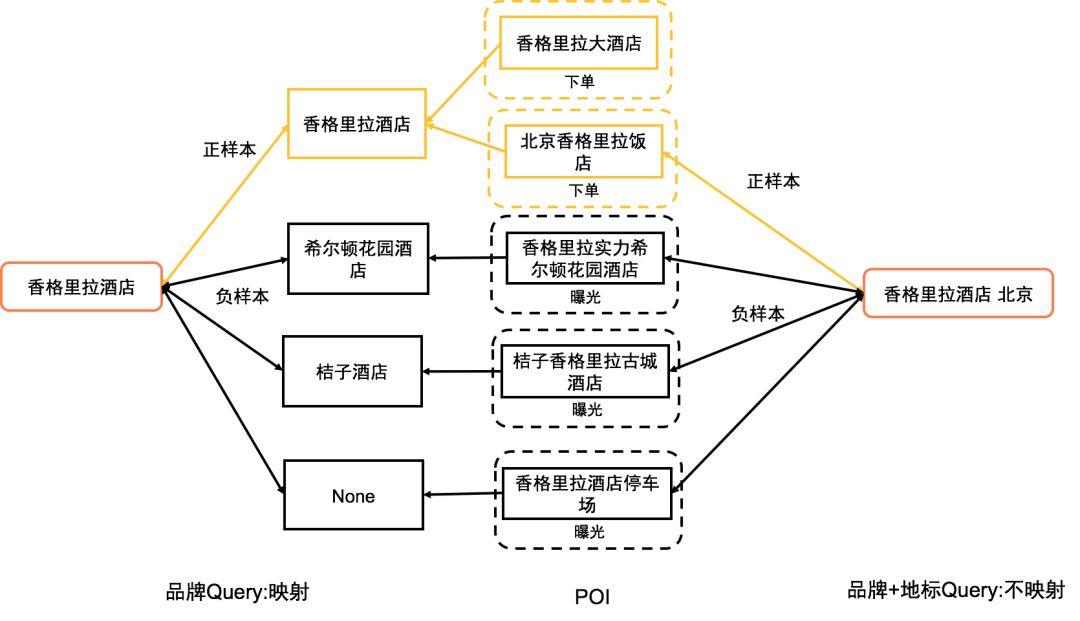
美团商家中有很多品牌商家,通常品牌商家拥有数百上千的POI,如“海底捞”、“肯德基”、“香格里拉酒店”等,品牌POI名称多是“品牌+地标”文本形式,如“北京香格里拉饭店”。对Query和POI的相关性进行建模时,如果仅取Query和POI名进行相关性训练,POI名中的“地标”会给模型带来很大干扰。例如,用户搜“香格里拉酒店”时会召回品牌“香格里拉酒店”的分店,如“香格里拉酒店”和“北京香格里拉饭店”等,相关性模型受地标词影响,会给不同分店会打出不同的相关性分数,进而影响到后续排序模型的训练。因此,我们对于样本中的品牌搜索样本做了针对性优化。搜索品牌词有时会召回多个品牌的结果,假设用户搜索的品牌排序靠后,而其他品牌排序靠前会严重影响到用户体验,因此对Query和POI相关性建模时召回结果中其他品牌的POI可认为是不相关样本。针对上述问题,我们利用POI的品牌信息对样本进行了重点优化。
- POI名映射到品牌:在品牌搜Query不包含地标词的时候,将POI名映射到品牌(非品牌POI不进行映射),从而消除品牌POI分店名中地标词引入的噪声。如Query是“香格里拉酒店”,召回的“香格里拉大酒店”和“北京香格里拉饭店”统一映射为品牌名“香格里拉酒店”。Query是“品牌+地标”形式(如“香格里拉饭店 北京”)时,用户意图明确就是找某个地点的POI,不需要进行映射,示例如下图3所示。
- 负样本过滤:如果搜索词是品牌词,在选取负样本的时候只在其他品牌的样本中选取。如POI为“香格里拉实力希尔顿花园酒店”、“桔子香格里拉古城酒店”时,同Query “香格里拉酒店”虽然字面很相似,但其明显不是用户想要的品牌。
经过样本去噪和品牌样本优化后,BERT相关性模型在Benchmark上的Accuracy提升23BP,相应地L2排序排序模型离线AUC提升17.2BP。
模型优化
知识融合
我们团队基于美团业务数据构建了餐饮娱乐领域知识图谱—“美团大脑”[32],对于候选Doc(POI/SPU),通过图谱可以获取到该Doc的大量结构化信息,如地址、品类、团单,场景标签等。美团搜索场景中的Query和Doc都以短文本为主,我们尝试在预训练和Fine-tuning阶段融入图谱品类和实体信息,弥补Query和Doc文本信息的不足,强化语义匹配效果。
引入品类信息的预训练
由于美团搜索多模态的特点,在某些情况下,仅根据Query和Doc标题文本信息很难准确判断两者之间的语义相关性。如<考研班,虹蝶教育>,Query和Doc标题文本相关性不高,但是“虹蝶教育”三级品类信息分别是“教育-升学辅导-考研”,引入相关图谱信息有助于提高模型效果,我们首先基于品类信息做了尝试。
在相关性判别任务中,BERT模型的输入是对。对于每一个输入的Token,它的表征由其对应的词向量(Token Embedding)、片段向量(Segment Embedding)和位置向量(Position Embedding)相加产生。为了引入Doc品类信息,我们将Doc三级品类信息拼接到Doc标题之后,然后跟Query进行相关性判断,如图4所示。
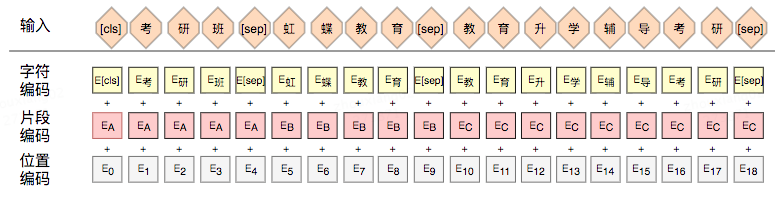
对于模型输入部分,我们将Query、Doc标题、三级类目信息拼接,并用[SEP]分割,区分3种不同来源信息。对于段向量,原始的BERT只有两种片段编码EA和EB,在引入类目信息的文本信息后,引入额外的片段编码EC。引入额外片段编码的作用是防止额外信息对Query和Doc标题产生交叉干扰。由于我们改变了BERT的输入和输出结构,无法直接基于MT-BERT进行相关性Fine-tuning任务。我们对MT-BERT的预训练方式做了相应改进,BERT预训练的目标之一是NSP(Next Sentence Prediction),在搜索场景中没有上下句的概念,在给定用户的搜索关键词和商户文本信息后,判断用户是否点击来取代NSP任务。
添加品类信息后,BERT相关性模型在Benchmark上的Accuracy提升56BP,相应地L2排序模型离线AUC提升6.5BP。
引入实体成分识别的多任务Fine-tuning
在美团搜索场景中,Query和Doc通常由不同实体成分组成,如美食、酒店、商圈、品牌、地标和团购等。除了文本语义信息,这些实体成分信息对于Query-Doc相关性判断至关重要。如果Query和Doc语义相关,那两者除了文本语义相似外,对应的实体成分也应该相似。例如,Query为“Helens海伦司小酒馆”,Doc为“Helens小酒馆(东鼎购物中心店)”,虽然文本语义不完全匹配,但二者的主要的实体成分相似(主体成分为品牌+POI形式),正确的识别出Query/Doc中的实体成分有助于相关性的判断。微软的MT-DNN[33]已经证明基于预训练模型的多任务Fine-tuning可以提升各项子任务效果。由于BERT Fine-tuning任务也支持命名实体识别(NER)任务,因而我们在Query-Doc相关性判断任务的基础上引入Query和Doc中实体成分识别的辅助任务,通过对两个任务的联合训练来优化最终相关性判别结果,模型结构如下图5所示:

多任务学习模型的损失函数由两部分组成,分别是相关性判断损失函数和命名实体识别损失函数。其中相关性损失函数由[CLS]位的Embedding计算得到,而实体成分识别损失函数由每个Token的Embedding计算得到。2种损失函数相加即为最终优化的损失函数。在训练命名实体识别任务时,每个Token的Embedding获得了和自身实体相关的信息,从而提升了相关性任务的效果。
引入实体成分识别的多任务Fine-tuning方式后,BERT相关性模型在Benchmark上的Accuracy提升219BP,相应地L2排序模型AUC提升17.8BP。
Pairwise Fine-tuning
Query-Doc相关性最终作为特征加入排序模型训练中,因此我们也对Fine-tuning任务的训练目标做了针对性改进。基于BERT的句间关系判断属于二分类任务,本质上是Pointwise训练方式。Pointwise Fine-tuning方法可以学习到很好的全局相关性,但忽略了不同样本之前的偏序关系。如对于同一个Query的两个相关结果DocA和DocB,Pointwise模型只能判断出两者都与Query相关,无法区分DocA和DocB相关性程度。为了使得相关性特征对于排序结果更有区分度,我们借鉴排序学习中Pairwise训练方式来优化BERT Fine-tuning任务。
Pairwise Fine-tuning任务输入的单条样本为三元组,对于同一Query的多个候选Doc,选择任意一个正例和一个负例组合成三元组作为输入样本。在下游任务中只需要使用少量的Query和Doc相关性的标注数据(有监督训练样本),对BERT模型进行相关性Fine-tuning,产出Query和Doc的相关性特征。Pairwise Fine-tuning的模型结构如下图6所示:
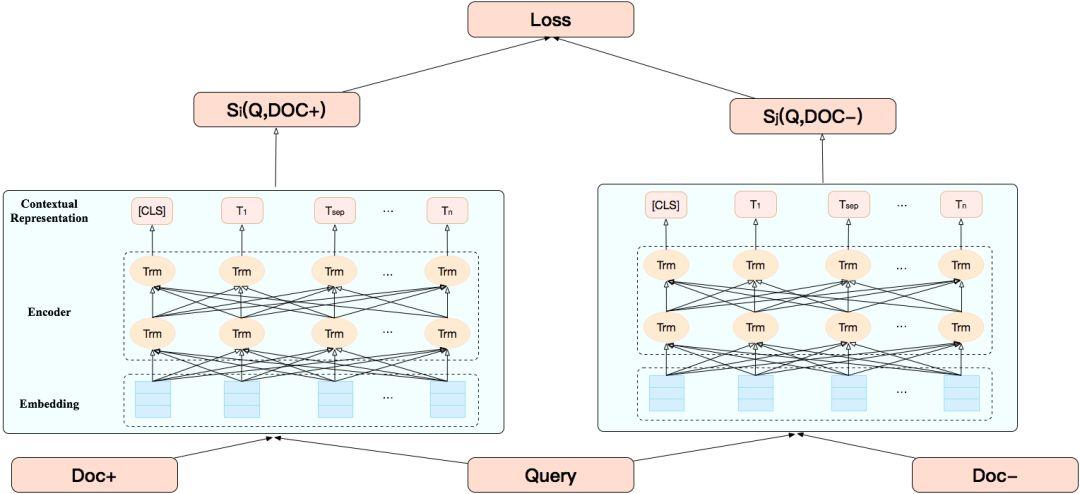
对于同一Query的候选Doc,选择两个不同标注的Doc,其中相关文档记为Doc+,不相关文档记Doc-。输入层通过Lookup Table 将Query, Doc+以及Doc-的单词转换为 Token 向量,同时会拼接位置向量和片段向量,形成最终输入向量。接着通过BERT模型可以分别得到(Query, Doc+)以及(Query, Doc-)的语义相关性表征,即BERT的CLS位输出。经过Softmax归一化后,可以分别得到(Query, Doc+)和(Query, Doc-)的语义相似度打分。
对于同一Query的候选Doc,选择两个不同标注的Doc,其中相关文档记为Doc+,不相关文档记Doc-。输入层通过Lookup Table 将Query, Doc+以及Doc-的单词转换为 Token 向量,同时会拼接位置向量和片段向量,形成最终输入向量。接着通过BERT模型可以分别得到(Query, Doc+)以及(Query, Doc-)的语义相关性表征,即BERT的CLS位输出。经过Softmax归一化后,可以分别得到(Query, Doc+)和(Query, Doc-)的语义相似度打分。
Pairwise Fine-tuning除了输入样本上的变化,为了考虑搜索场景下不同样本之间的偏序关系,我们参考RankNet[34]的方式对训练损失函数做了优化。令为同一个Query下相比更相关的概率,其中和分别为和的模型打分,则:
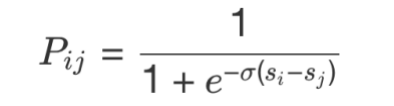
使用交叉熵损失函数,令表示样本对的真实标记,当比更相关时(即为正例而为负例),为1,否则为-1,损失函数可以表示为:
其中N表示所有在同Query下的Doc对。
使用Pairwise Fine-tuning方式后,BERT相关性模型在Benchmark上的Accuracy提升925BP,相应地L2排序模型的AUC提升19.5BP。
联合训练
前文所述各种优化属于两阶段训练方式,即先训练BERT相关性模型,然后训练L2排序模型。为了将两者深入融合,在排序模型训练中引入更多相关性信息,我们尝试将BERT相关性Fine-tuning任务和排序任务进行端到端的联合训练。
由于美团搜索涉及多业务场景且不同场景差异较大,对于多场景的搜索排序,每个子场景进行单独优化效果好,但是多个子模型维护成本更高。此外,某些小场景由于训练数据稀疏无法学习到全局的Query和Doc表征。我们设计了基于Partition-model的BERT相关性任务和排序任务的联合训练模型,Partition-model的思想是利用所有数据进行全场景联合训练,同时一定程度上保留每个场景特性,从而解决多业务场景的排序问题,模型结构如下图7所示:
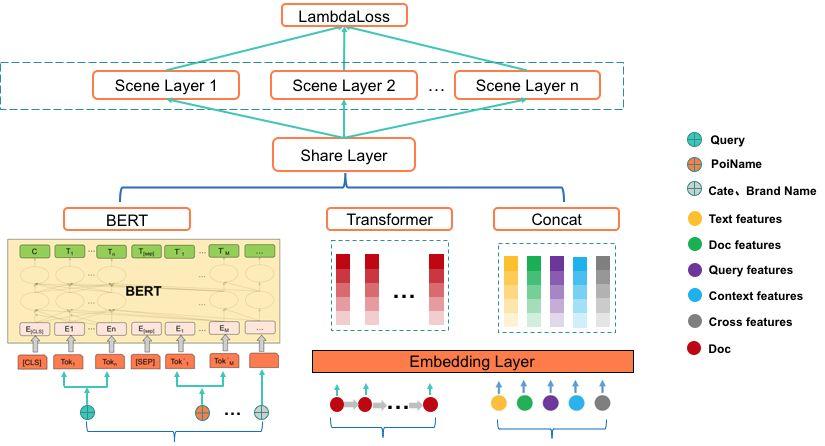
输入层:模型输入是由文本特征向量、用户行为序列特征向量和其他特征向量3部分组成。
- 文本特征向量使用BERT进行抽取,文本特征主要包括Query和POI相关的一些文本(POI名称、品类名称、品牌名称等)。将文本特征送入预训练好的MT-BERT模型,取CLS向量作为文本特征的语义表示。
- 用户行为序列特征向量使用Transformer进行抽取[3]。
- 其他特征主要包括:① 统计类特征,包含Query、Doc等维度的特征以及它们之间的交叉特征,使用这些特征主要是为了丰富Query和Doc的表示,更好地辅助相关性任务训练。② 文本特征,这部分的特征同1中的文本特征,但是使用方式不同,直接将文本分词后做Embedding,端到端的学习文本语义表征。③ 传统的文本相关性特征,包括Query和Doc的字面命中、覆盖程度、BM25等特征,虽然语义相关性具有较好的作用,但字面相关性仍然是一个不可或缺的模块,它起到信息补充的作用。
共享层:底层网络参数是所有场景网络共享。
场景层:根据业务场景进行划分,每个业务场景单独设计网络结构,打分时只经过所在场景的那一路。
损失函数:搜索业务更关心排在页面头部结果的好坏,将更相关的结果排到头部,用户会获得更好的体验,因此选用优化NDCG的Lambda Loss[34]。
联合训练模型目前还在实验当中,离线实验已经取得了不错的效果,在验证集上AUC提升了234BP。目前,场景切分依赖Query意图模块进行硬切分,后续自动场景切分也值得进行探索。
应用实践
由于BERT的深层网络结构和庞大参数量,如果要部署上线,实时性上面临很大挑战。在美团搜索场景下,我们对基于MT-BERT Fine-tuning好的相关性模型(12层)进行了50QPS压测实验,在线服务的TP99增加超过100ms,不符合工程上线要求。我们从两方面进行了优化,通过知识蒸馏压缩BERT模型,优化排序服务架构支持蒸馏模型上线。
模型轻量化
为了解决BERT模型参数量过大、前向计算耗时的问题,常用轻量化方法有三种:
- 知识蒸馏:模型蒸馏是在一定精度要求下,将大模型学到的知识迁移到另一个轻量级小模型上,目的是降低预测计算量的同时保证预测效果。Hinton在2015年的论文中阐述了核心思想[35],大模型一般称作Teacher Model,蒸馏后的小模型一般称作Student Model。具体做法是先在训练数据上学习Teacher Model,然后Teacher Model对无标注数据进行预测得到伪标注数据,最后使用伪标注数据训练Student Model。HuggingFace提出的DistilBERT[36]和华为提出的TinyBERT[37] 等BERT的蒸馏模型都取得了不错的效果,在保证效果的情况下极大地提升了模型的性能。
- 模型裁剪:通过模型剪枝减少参数的规模。
- 低精度量化:在模型训练和推理中使用低精度(FP16甚至INT8、二值网络)表示取代原有精度(FP32)表示。
在Query意图分类任务[2]中,我们基于MT-BERT裁剪为4层小模型达到了上线要求。意图分类场景下Query长度偏短,语义信息有限,直接裁剪掉几层Transformer结构对模型的语义表征能力不会有太大的影响。在美团搜索的场景下,Query和Doc拼接后整个文本序列变长,包含更复杂的语义关系,直接裁剪模型会带来更多的性能损失。因此,我们在上线Query-Doc相关性模型之前,采用知识蒸馏方式,在尽可能在保持模型性能的前提下对模型层数和参数做压缩。两种方案的实验效果对比见下表1:
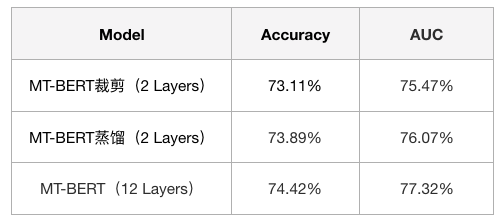
在美团搜索核心排序的业务场景下,我们采用知识蒸馏使得BERT模型在对响应时间要求苛刻的搜索场景下符合了上线的要求,并且效果无显著的性能损失。知识蒸馏(Knowledge Distillation)核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。首先我们基于MT-BERT(12 Layers),在大规模的美团点评业务语料上进行知识蒸馏得到通用的MT-BERT蒸馏模型(6 Layers),蒸馏后的模型可以作为具体下游任务Fine-tuning时的初始化模型。在美团搜索的场景下,我们进一步基于通用的MT-BERT蒸馏模型(6 Layers)进行相关性任务Fine-tuning ,得到MT-BERT蒸馏(2 Layers)进行上线。
排序服务架构优化
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java