
谈谈分布式锁。
一 从单机锁到分布式锁
在单机环境中,当共享资源自身无法提供互斥能力的时候,为了防止多线程/多进程对共享资源的同时读写访问造成的数据破坏,就需要一个第三方提供的互斥的能力,这里往往是内核或者提供互斥能力的类库,如下图所示,进程首先从内核/类库获取一把互斥锁,拿到锁的进程就可以排他性的访问共享资源。演化到分布式环境,我们就需要一个提供同样功能的分布式服务,不同的机器通过该服务获取一把锁,获取到锁的机器就可以排他性的访问共享资源,这样的服务我们统称为分布式锁服务,锁也就叫分布式锁。

由此抽象一下分布式锁的概念,首先分布式锁需要是一个资源,这个资源能够提供并发控制,并输出一个排他性的状态,也就是:
锁 = 资源 + 并发控制 + 所有权展示
以常见的单机锁为例:
- Spinlock = BOOL +CAS(乐观锁)
- Mutex = BOOL + CAS + 通知(悲观锁)
Spinlock 和 Mutex 都是一个 Bool 资源,通过原子的 CAS 指令:当现在为 0 设置为 1,成功的话持有锁,失败的话不持有锁,如果不提供所有权的展示,例如 AtomicInteger,也是通过资源(Interger)+ CAS,但是不会明确的提示所有权,因此不会被视为一种锁,当然,可以将“所有权展示”这个更多地视为某种服务提供形式的包装。
单机环境下,内核具备“上帝视角”,能够知道进程的存活,当进程挂掉的时候可以将该进程持有的锁资源释放,但发展到分布式环境,这就变成了一个挑战,为了应对各种机器故障、宕机等,就需要给锁提供了一个新的特性:可用性。
如下图所示,任何提供三个特性的服务都可以提供分布式锁的能力,资源可以是文件、KV 等,通过创建文件、KV 等原子操作,通过创建成功的结果来表明所有权的归属,同时通过 TTL 或者会话来保证锁的可用性。

二 分布式锁的系统分类
根据锁资源本身的安全性,我们将分布式锁分为两个阵营:
- 基于异步复制的分布式系统,例如 mysql,tair,redis 等。
- 基于 paxos 协议的分布式一致性系统,例如 zookeeper,etcd,consul 等。
基于异步复制的分布式系统,存在数据丢失(丢锁)的风险,不够安全,往往通过 TTL 的机制承担细粒度的锁服务,该系统接入简单,适用于对时间很敏感,期望设置一个较短的有效期,执行短期任务,丢锁对业务影响相对可控的服务。
基于 paxos 协议的分布式系统,通过一致性协议保证数据的多副本,数据安全性高,往往通过租约(会话)的机制承担粗粒度的锁服务,该系统需要一定的门槛,适用于对安全性很敏感,希望长期持有锁,不期望发生丢锁现象的服务。
三 存储分布式锁
存储在长期的实践过程中,在如何提升分布式锁使用时的正确性、保证锁的可用性以及提升锁的切换效率方面积累比较多的经验。
1 严格互斥性
互斥性作为分布式锁最基本的要求,对用户而言就是不能出现“一锁多占”,那么存储分布式锁是如何避免该情况的呢?
答案是,服务端每把锁都和唯一的会话绑定,客户端通过定期发送心跳来保证会话的有效性,也就保证了锁的拥有权。当心跳不能维持时,会话连同关联的锁节点都会被释放,锁节点就可以被重新抢占。这里有一个关键的地方,就是如何保证客户端和服务端的同步,在服务端会话过期的时候,客户端也能感知。
如下图所示,在客户端和服务端都维护了会话的有效期的时间,客户端从心跳发送时刻(S0)开始计时,服务端从收到请求(S1)开始计时,这样就能保证客户端会先于服务端过期。 用户在创建锁之后,核心工作线程在进行核心操作之前可以判断是否有足够的有效期,同时我们不再依赖墙上时间,而是基于系统时钟来对时间进行判断,系统时钟更加精确,且不会向前或者向后移动(秒级别误差毫秒级,同时在 NTP 跳变的场景,最多会修改时钟的速率)。
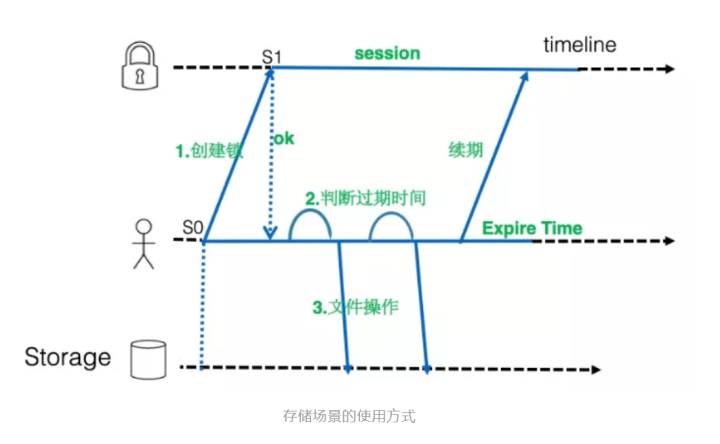
在分布式锁互斥性上,我们是不是做到完美了?并非如此,还是存在一种情况,业务基于分布式锁服务的访问互斥会被破坏。
我们来看下面的例子:如下图所示,客户端在时间点(S0)尝试去抢锁,在时间点(S1)在后端抢锁成功,因此也产生了一个分布式锁的有效期窗口。在有效期内,时间点(S2)做了一个访问存储的操作,很快完成,然后在时间点(S3)判断锁的有效期依旧成立,继续执行访问存储操作,结果这个操作耗时良久,超过了分布式锁的过期时间,那么可能这个时候,分布式锁已经被其他客户端抢占成功,进而出现两个客户端同时操作同一批数据的可能性,这种可能性是存在的,虽然概率很小。
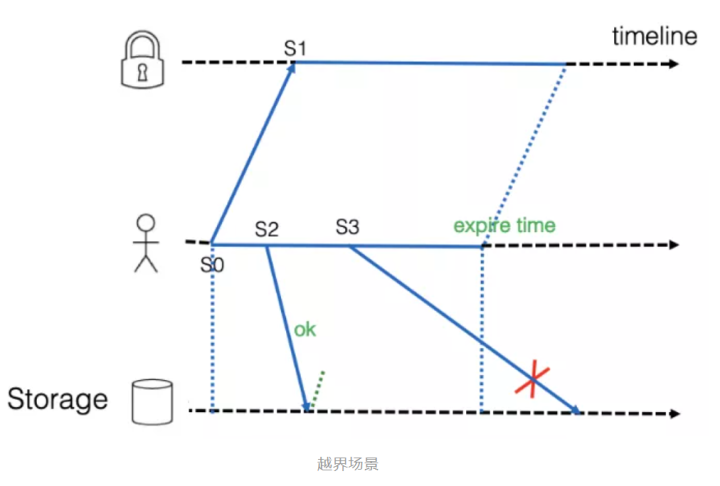
针对这个场景,具体的应对方案是在操作数据的时候确保有足够的锁有效期窗口,当然如果业务本身提供回滚机制的话,那么方案就更加完备,该方案也在存储产品使用分布式锁的过程中被采用。
还有一个更佳的方案,即,存储系统本身引入 IOFence 能力。这里就不得不提 Martin Kleppmann 和 redis 的作者 antirez 之间的讨论了。redis 为了防止异步复制导致的锁丢失的问题,引入了 redlock,该方案引入了多数派的机制,需要获得多数派的锁,最大程度的保证了可用性和正确性,但仍然有两个问题:
- 墙上时间的不可靠(NTP 时间)
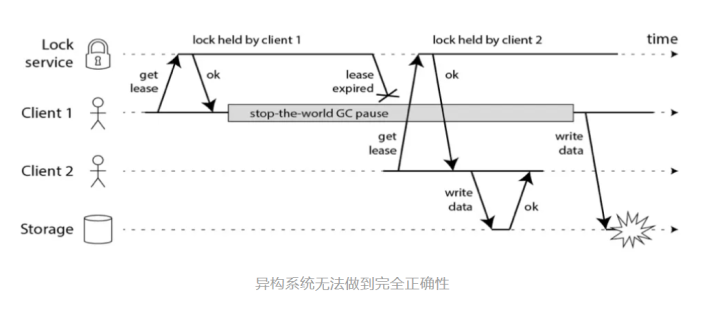
- 异构系统的无法做到严格正确性
墙上时间可以通过非墙上时间 MonoticTime 来解决(redis 目前仍然依赖墙上时间),但是异构系统只有一个系统并没有办法保证完全正确。如下图所示,Client1 获取了锁,在操作数据的时候发生了 GC,在 GC 完成时候丢失了锁的所有权,造成了数据不一致。
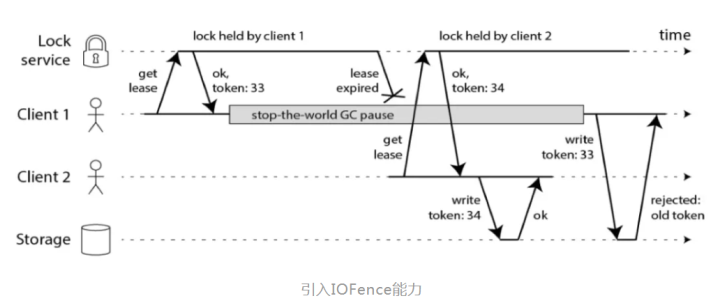
因此需要两个系统同时协作来完成一个完全正确的互斥访问,在存储系统引入 IOFence能力,如下图所示,全局锁服务提供全局自增的 token,Client 1 拿到锁返回的 token 是 33,并带入存储系统,发生 GC,当 Client 2 抢锁成功返回 34,带入存储系统,存储系统会拒绝 token 较小的请求,那么经过了长时间 full gc 重新恢复后的 Client 1 再次写入数据的时候,因为存储层记录的 token 已经更新,携带 token 值为 33 的请求将被直接拒绝,从而达到了数据保护的效果(chubby 的论文中有讲述,也是 Martin Kleppmann 提出的解决方案)。
这与阿里云分布式存储平台盘古的设计思路不谋而合,盘古支持了类似 IO Fence 的写保护能力,引入 Inline File 的文件类型,配合 SealFile 操作,这就有着类似 IO Fence 的写保护能力。首先,SealFile 操作用来关闭已经打开的 cs 上面的文件,防止旧的 Owner 继续写数据;其次,InlineFile 可以防止旧的 Owner 打开新的文件。这两个功能事实上也是提供了存储系统中的 Token 支持。
2 可用性
存储分布式锁通过持续心跳来保证锁的健壮性,让用户不用投入很多精力关注可用性,但也有可能异常的用户进程持续占据锁。针对该场景,为了保证锁最终可以被调度,提供了可以安全释放锁的会话加黑机制。
当用户需要将发生假死的进程持有的锁释放时,可以通过查询会话信息,并将会话加黑,此后,心跳将不能正常维护,最终导致会话过期,锁节点被安全释放。这里我们不是强制删除锁,而是选用禁用心跳的原因如下:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java