
谈谈计算机的视觉目标跟踪。
一 什么是视觉目标跟踪
视觉目标跟踪的定义
在计算机视觉领域中并没有对视觉目标跟踪(简称跟踪,下同)的唯一定义。通常来说,跟踪的目标是视频帧或图像中的某个区域或物体,不需要其语义信息(类别等),此概念被形象地描述为“万物跟踪”。同时,也存在一些特例,通常被应用在一些特定场景中对已知类型物体的跟踪,例如工厂流水线监控中对某些特定产品的跟踪(如零部件等)。
很多学者对跟踪有着不同的阐释,包括:“跟踪是视频序列中识别感兴趣区域
(region of interest) 的过程”[1],或者“给定目标在视频中某一帧的状态(位置、尺寸等),跟踪是估计 (estimate)
该目标在后续帧中的状态”[2]等。这些定义看似大相径庭,但其实有很多共同点。通过提取这些共同点,我们将跟踪问题定义为:
跟踪是在一个视频的后续帧中找到在当前帧中定义的感兴趣物体 (object of interest) 的过程。
可以发现,上述定义主要关注跟踪的三方面问题,即“找到”、“感兴趣物体”、和“后续帧”。注意,这里的当前帧可以是视频中的任意一帧。通常来说,跟踪是从视频的第二帧开始的,第一帧用来标记目标的初始位置 (ground truth)。下面,我们利用博尔特参加男子百米短跑的例子来解释这三方面问题。

图1. 博尔特参加男子百米短跑的视频截图[3]
视觉目标跟踪的基本原理
“找到”:如何locate博尔特?
假设在视频上一帧我们找到了博尔特所在的位置,我们要做的是在当前帧中继续找到博尔特所在的位置。如前所述,视觉是跟踪问题(视觉目标跟踪)的限定条件,其带来了可以利用的性质。在这里,我们可以利用的de facto rules是:在同一段视频中,相同的物体在前后两帧中的尺寸和空间位置不会发生巨大的变化[4]。比如我们可以做出如下判断:博尔特在当前帧中的空间位置大概率会在跑道中,而几乎不可能在旁边的草坪内。也就是说,如果我们想知道博尔特在当前帧中的空间位置,我们只需要在跑道中生成一些候选位置,然后在其中进行寻找即可。上述过程引出了跟踪中一个重要的子问题,即candidate generation,通常被表述为候选框生成。
“感兴趣物体”:如何shape博尔特?
博尔特就是图像中个子最高,并且穿着黄色和绿色比赛服的人。但是,我们忽略了一个问题,就是我们对于博尔特的“定义”其实已经包含了很多高度抽象的信息,例如个子最高,还有黄色和绿色的比赛服。在计算机视觉领域中,我们通常将这些高度抽象的信息称之为特征。对于计算机而言,如果没有特征,博尔特和草坪、跑道、或者图像中其他对于人类有意义的物体没有任何区别。因此,想让计算机对博尔特进行跟踪,特征表达/提取 (feature representation/extraction) 是非常重要的一环,也是跟踪中第二个重要的子问题。
“后续帧”:如何distinguish博尔特 (from others) ?
在这里,我们将“后续帧”关注的问题定义为如何利用前一帧中的信息在当前帧中鉴别 (distinguish) 目标。我们不仅需要在“后续帧”中的每一帧都能完成对目标的跟踪,还强调连续帧之间的上下文关系对于跟踪的意义。直观理解,该问题的答案非常简单:在当前帧中找到最像上一帧中的跟踪结果的物体即可。这就引出了跟踪中第三个重要的子问题:决策 (decision making)。决策是跟踪中最重要的一个子问题,也是绝大多数研究人员最为关注的问题。通常来说,决策主要解决匹配问题,即将当前帧中可能是目标的物体和上一帧的跟踪结果进行匹配,然后选择相似度最大的物体作为当前帧的跟踪结果。
联系
在上述三个小节中我们分别介绍了跟踪基本原理中的三个子问题:候选框生成、特征表达/提取、及决策。需要注意的是,这三个子问题并非彼此独立。有时候,决策问题的解决方案会包含更为精确的候选框生成和/或更为抽象的特征提取,利用端到端 (end-to-end) 的思想解决跟踪问题,来提高跟踪系统和算法的性能。这在近几年流行的基于深度学习的跟踪算法中非常常见[1]。
视觉目标跟踪的应用
从某种意义来说,在回答“视觉目标跟踪有哪些应用”的问题之前,我们应该先讨论学术研究方法论中“为什么”的问题,即“为什么要做视觉目标跟踪”。
跟踪在计算机视觉科学的经典应用领域,包括安防领域(车辆跟踪、车牌识别等)、监控领域(人脸识别、步态识别等)、巡检领域(无人机追踪、机器人导航等)、以及新兴的智慧生活(人机交互、VR/AR等)、智慧城市(流量监测等)、以及智慧工业(远程医疗等)等。跟踪问题的主要应用可以总结为:
跟踪主要应用于对视频或连续有语义关联的图像中任意目标的空间位置、形状和尺寸的获知。
作为检测算法的补充,其可以在视频或连续有语义关联的图像中提供目标的空间位置,降低整个系统的复杂度(例如检测仅应用于视频第一帧识别出目标,以及后续帧中的某些帧来确定目标位置,然后在其余帧中应用跟踪确定目标位置)。
二 如何进行视觉目标跟踪
视觉目标跟踪的系统架构
候选框生成、特征表达/提取、和决策构成了一条完整的逻辑链路。具体来说,对于视频中的每一帧(通常不包括第一帧),跟踪的系统流程可以用图3中的架构来表示:

如图所示,在跟踪系统中,上一帧(含跟踪结果,如图中input frame)和当前帧会被作为系统输入,然后分别经过运动模型 (motion model)、特征模型 (feature model)、和观测模型 (observation model),最终作为当前帧对目标位置的预测 (final prediction) 输出。其中,候选框生成、特征表达/提取、和决策三个子问题分别在上述三个模型中被解决,其输入与输出的对应关系如表1。
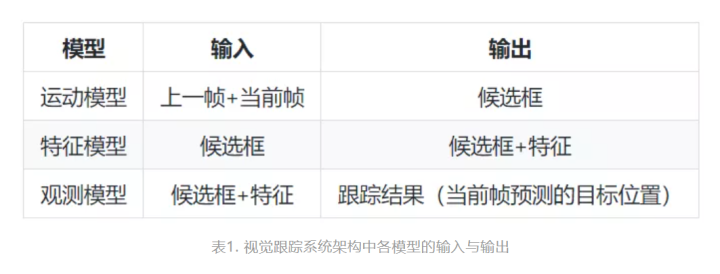
注意,图3中的跟踪系统架构应用了假设检验 (hypothesis testing) 模型。该模型是统计推断中的常用方法,其基本原理是先对系统的特征做出某种假设,然后通过研究抽样的统计分布,判断应该接受还是拒绝此假设。该模型能够很好地应用于跟踪问题,即假设当前帧的某个候选框是预测目标,然后通过特征表达/提取和决策,来判断该候选框是否可以作为当前帧目标位置的合理预测。
运动模型 — where?
1)目标表达形式
目标在当前帧中的大概位置是运动模型中主要被解决的问题,即候选框生成 (where)。在讨论如何生成的问题之前,我们首先需要明确的是什么是候选框。候选框是对于目标包围盒 (bounding box) 的假设 (hypothesis)。此处的表达与特征模型中的特征表达有所区别,其关注的主要是如何在视频帧或图像中“描绘”目标。常见的表达形式如图4所示。
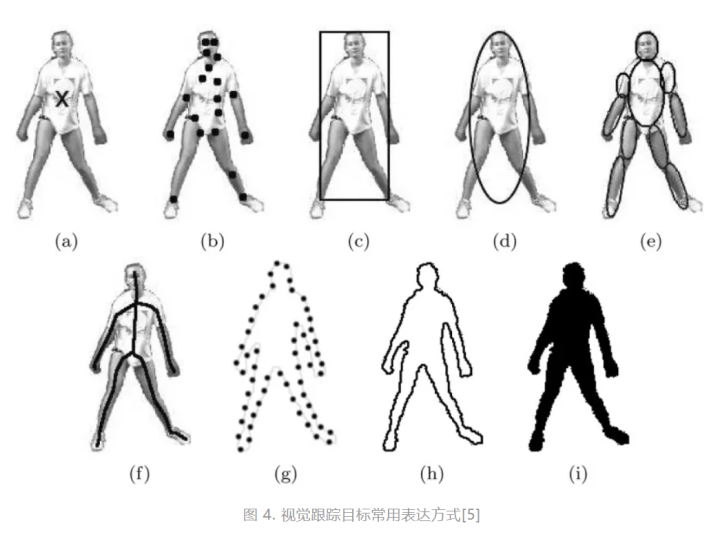
如图所示,目标可以被矩形框 (4c)、骨架 (4f)、或轮廓 (4h) 等不同形式所表达。其中,广泛被计算机视觉研究中所采用的是如4(c)中的矩形框(即bounding box,一译包围盒)表达。这种表达形式的优点包括易生成(如最小外接矩形)、易表达(如左上角+右下角坐标,或中心点坐标+宽高)、易评估(如IOU (intersection over union),一译交并比)等。详细的信息见[5]。
2)De facto rules:尺寸变化小,位置移动慢
在确定好目标的表达形式(候选框)后,接下来我们需要关注如何生成候选框。在很多学术文章中,深度学习训练过程中的正负样本生成有时也被称作候选框生成。这种候选框生成和我们在该小节中讨论的候选框生成是两个概念。下面介绍两种候选框生成分别是什么,以及如何区分,避免混淆。
- 推理过程:即图3中的系统流程,用于预测当前帧的目标位置,任何跟踪算法都需要。在该过程中,运动模型生成候选框,然后经过特征模型进行特征表达/提取,将含有特征的候选框输入观测模型进行决策(对目标位置的预测)。如视觉目标跟踪的定义一节所述,de facto rules 是在同一段视频中,相同的目标在前后两帧中的尺寸和空间位置不会发生巨大的变化。基于此,我们可以大大减少候选框的数量和种类,即我们只需要在上一帧预测的目标位置附近生成和其尺寸近似的候选框,从而提高整个跟踪系统的效率。
- 训练过程:通常在基于判别式方法的跟踪算法中需要,属于跟踪系统学习如何区分目标和非目标的过程,将在视觉目标跟踪的算法分类一节中详述。在该过程中,所谓的候选框生成应该被称作“正负样本生成”。在这里,正样本可以近似地理解为目标,负样本可以近似地理解为非目标的干扰项,例如背景或其他像目标但不是目标的物体。为了提高该类算法的跟踪系统对于正负样本的判别能力,在生成负样本时通常会在整个图像中寻找,而不仅限于上一帧预测的目标位置附近。
总结来说,候选框生成被应用在推理过程,用来生成当前帧目标的潜在位置;正负样本生成被应用在基于判别式方法的跟踪算法的训练过程,用来生成正负样本训练跟踪系统,使得系统习得区分目标与分目标的能力。
3)运动模型系统架构与分类
图5示出了运动模型的系统架构以及如何得到候选框的方法分类。如图所示,前一帧(第n帧)中预测目标的位置被输入模型中,输出当前帧(第n+1帧)的候选框。这些候选框可能有位置变化、尺度变化、和旋转等,如图中绿色和橙色虚线框所示。
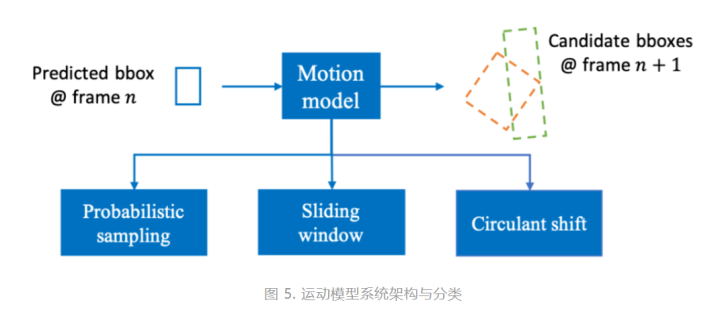
在运动模型中,主要的候选框生成方法有如下三种:
a) 概率采样 (probabilistic sampling)
通过仿射变换生成候选框。具体来说,假设输入的上一帧预测目标的位置矩形框坐标为
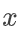 、仿射变换的参数矩阵为
、仿射变换的参数矩阵为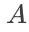 、以及输出的(一个)候选框的坐标为
、以及输出的(一个)候选框的坐标为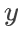 ,则
,则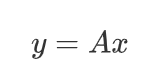
其中,
中的参数包括候选框位置变换、尺度变换、旋转变换、和长宽比变换等信息,仿射变换的示例如图5所示。这里,概率体现在上述参数都是符合某种概率分布(通常是高斯分布)的随机变量,而采样则体现在生成不同数量的候选框。
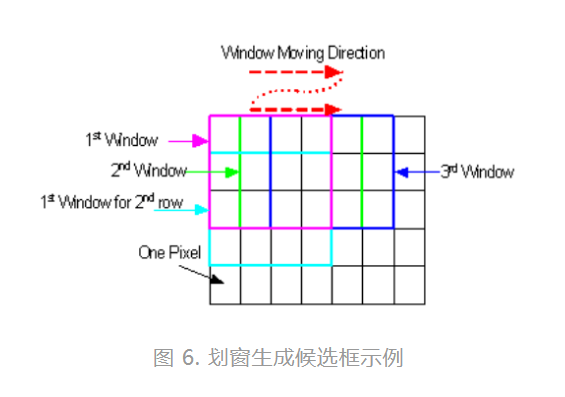
b) 滑窗 (sliding window)
如图6所示,以某个形状和大小的结构元素(形象地被称之为窗)在当前帧中按一定的空间间隔移动,每次移动后覆盖的图像中的相应像素即为生成的候选框。通常来说,通过此种方法生成的候选框和前一帧的矩形框相比仅有位置变换,其他变化(如旋转变换)需要进行额外的处理。
c) 循环移位 (circulant shift)
如图7所示,如果我们将上一帧预测的目标位置的矩形框中的像素按照某种排列变成图中base sample所示,那么每次右移一个像素,即可生成一个候选框的对应排列。通过生成该排列的反变换,即可得到一个候选框。通常来说,通过此种方法生成的候选框和前一帧的矩形框相比仅有位置变换(如旋转变换),其他变化需要进行额外的处理。值得强调的是,循环移位是滑窗的一个特例,但是其在基于相关滤波的跟踪算法中与快速傅里叶变换 (fast Fourier transformation) 结合能够极大地提高算法效率,使其无需再使用传统的滑窗操作生成候选框,因此在此被单列出来。

特征模型 — how look like?
1)什么是图像特征
对于人类来说,图像特征是对于图像的直观感受。对于计算机来说,图像特征是图像内的一些区域/整个图像和其他区域/其他图像的差异。常用的图像特征包括颜色特征、形状特征、空间特征、纹理特征、以及在深度学习中通过卷积神经网络得到的深度特征等。博尔特的黄色和绿色的比赛服即属于颜色特征,而个子高则结合了空间特征和纹理特征。通常来说,特征越“深”(抽象且不直观的的特征,如深度特征),对目标的判别能力越好;反之,特征越“浅”(具体且直观的特征,如颜色等),对目标的空间位置信息保留越好。因此,特征表达/提取通常需要在两者之间做权衡,才能达到更好的跟踪效果。
2)什么是图像特征表达
了解什么是图像特征之后,特征表达/提取要解决的问题是如何来描述这些特征,即用计算机能够理解的语言来描述这些特征的数学特性的一个或多个维度。常用的特征表达/提取方法包括朴素方法(naive,如像素值)、统计方法(statistics,如直方图)、和变换(transformation,如像素值的梯度)等。
特征和特征表达被统称为特征模型。特征模型可以对从运动模型中得到的候选框进行分析,得到相应的候选框特征表达/提取,如图8所示。
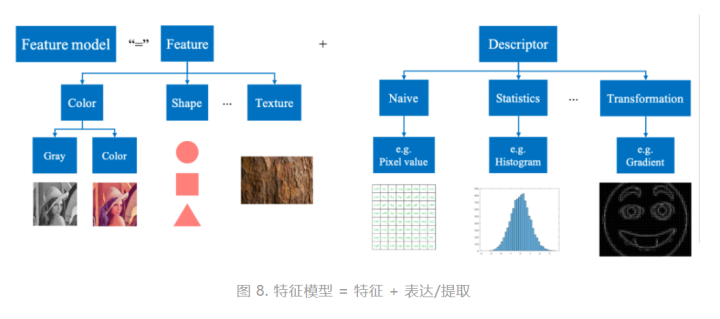
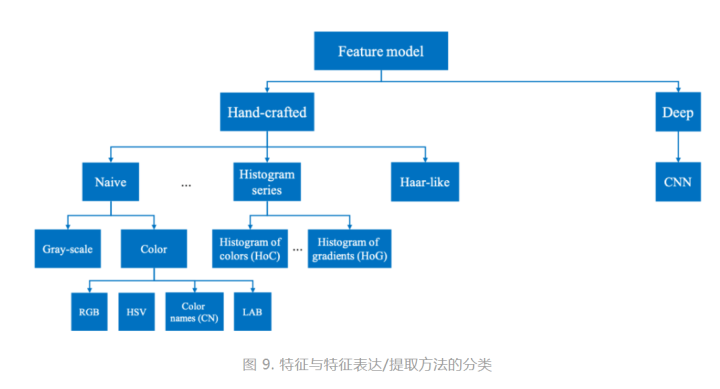
3)特征模型的分类
图9示出了如何得到对特征进行表达/提取的方法分类。可以看到的是,在应用卷积神经网络 (CNN) 得到深度特征 (deep) 之前,手工的 (hand-crafted) 特征表达/提取方法是跟踪问题中对于图像特征进行处理的主流方法,其包括上述提到的各种特征和表达方式。在诸多特征和表达方式中,应用最多的是颜色特征和梯度直方图。颜色特征比较容易理解,其不仅符合人类对于图像的直观理解,同时也是最简单的计算机表征图像的方法,即像素值。梯度直方图是关于梯度的直方图,其中梯度是图像像素值在某个特定空间方向上的变化,例如水平相邻像素之间的像素值差;而直方图是一种常用的数据分布的图像表示,可以直观地表示出一组数据在其取值范围内的数量变化。请各位同学参考[7]获取更多关于图像特征的信息。目前,基于深度学习的方法逐渐成为跟踪问题研究的主流,其通过卷积神经网络 (CNN) 得到的深度特征 (deep) 极大地提高了跟踪算法对目标的判别能力,所达到的性能也超过应用手工特征的跟踪算法。
观测模型 — which?
1)如何做决策
在观测模型中,如何在诸多候选框中选出一个作为我们对目标位置在当前帧的预测是在观测模型需要解决的主要问题,即做决策(“哪一个”)。直观理解,我们只需要在当前帧的候选框中找出最“像”前一帧的预测目标的候选框就可以,然而最“像”并不是仅有一种定义。
通常来说,在计算机视觉领域中解决最“像”问题可以被归类为匹配问题,即在候选框中找到和前一帧目标最为匹配的那个。匹配问题是整个跟踪问题的核心,也是绝大多数跟踪算法解决的主要的问题,其解决方案的效果直接影响整个跟踪算法的性能。有时候,即使在候选框生成和特征表达/提取方面做得不够好,例如候选框的形状和尺寸与实际有出入,或提取的特征的判别程度不高,优秀的匹配算法也可以在一定程度上弥补前两个模型中存在的不足,维持跟踪算法的整体性能。
2)如何做匹配
前述中提到的最“像”或匹配问题在本质上是一个相似度度量 (similarity measurement) 问题。在解决相似度问题的时候,我们需要一个衡量机制,来计算两个相比较的个体的相似度。在跟踪问题中,被比较的个体通常是候选框和前一帧的预测结果(或者是ground truth),而衡量机制可以被抽象成距离 (distance)。这里的距离不仅仅是空间距离,即框与框之间在图像中相隔多少个像素,还包括两个概率分布的距离。
由于空间距离相对好理解,我们在这里仅对概率分布距离稍作解释:每一帧的跟踪结果是一个预测值,即每一个候选框是目标的概率。如果综合所有候选框,就可以构成一个概率分布。从概率分布的角度理解匹配问题,跟踪问题就转换成在当前帧寻找和上一帧的候选框概率分布“最接近”的一组候选框分布,该“最接近”即是概率分布距离。常用的空间距离有Minkowski distance(Manhattan distance和Euclidean distance是其特殊情况),常用的概率分布距离有Kullback–Leibler (KL) 散度、Bhattacharyya distance、交叉熵、以及Wasserstein distance等。参考[8]。
3)观测模型系统架构与分类
图10示出了观测模型的系统架构。如图所示,前一帧(第n帧)中预测的目标位置、当前帧(第n+1帧)的候选框、和候选框的特征被输入模型,输出当前帧(第n+1帧)的预测结果(目标位置)。这些候选框可能有位置变化、尺度变化、和旋转等,如图中绿色和橙色虚线框所示。
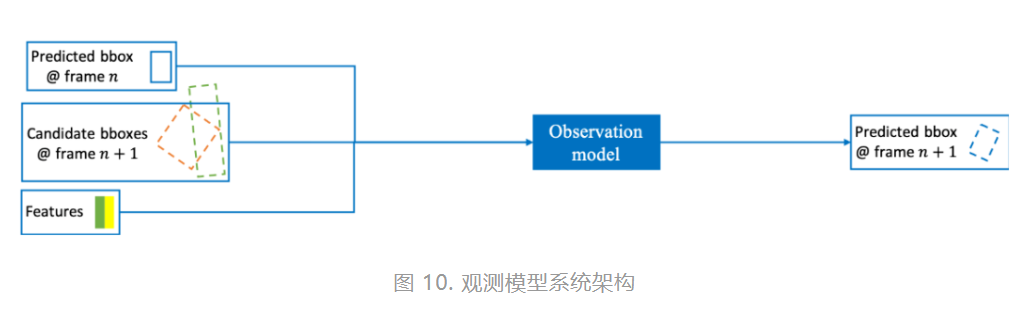
图11示出了观测模型的模块拆解和分类。如图所示,观测模型的核心模块是匹配 (match)。对于匹配方法的分类,业界的主流观点是:生成式方法 (generative) 和判别式方法 (discriminative)[1, 2, 4, 9]。这两种方法的主要区别在于是否有背景信息的引入。具体来说,生成式方法使用数学工具拟合目标的图像域特征,并在当前帧寻找拟合结果最佳(通常是拟合后重建误差最小的)的候选框。而判别式方法则是不同的思路,其将目标视为前景,将不包含目标的区域视为背景,从而将匹配问题转换成了将目标从背景中分离的问题。
对比起来,判别式方法具有更好的判别能力,即将目标和其他干扰项区分开的能力,这也是这一类匹配方法得名的由来。作为上述观点的论据支撑,应用判别式方法的跟踪算法的性能已经大幅度超越应用生成式方法的跟踪算法,成为学术界研究的主流方向[9]。总结来说,生成式方法把跟踪问题建模成拟合或多分类问题,而判别式方法把跟踪问题定义为二分类问题。
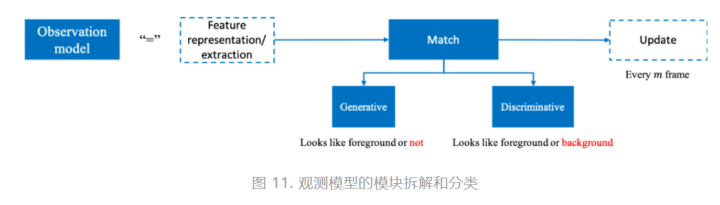
此外,在图11中我们注意到还有两个虚线框示出的模块,分别代表特征表达/提取 (feature representation/extraction) 和更新 (update)。在这里,虚线表示这两个步骤不是必须被执行的。对于有的算法而言,通过特征模型得到的特征会被进一步抽象,来获取目标更深层次的特征信息,然后再被送进匹配模块执行匹配算法。同时,更新的步骤也非必须的,其存在的意义是获得更为准确的预测结果。
具体来说,匹配算法得到了一系列的参数,应用这些参数即可对当前帧的目标位置进行预测。如果在后续所有帧的预测过程中都应用这些参数,可能会出现的结果是预测趋向不准确,最终导致跟踪的失败。其可能的原因包括累积误差、外因(如遮挡、光照变化)、以及内因(如目标外观变化、快速运动)等。如果引入更新模块,在每若干帧之后根据之前的预测结果更新匹配算法的参数,则可以减小误差,提高跟踪的准确性。
视觉目标跟踪的算法分类
跟踪算法根据其观测模型被分为两大类:生成式方法 (generative) 和判别式方法 (discriminative)。值得注意的是,在这里我们强调分类的依据是观测模型,是为了将整个跟踪系统架构中的不同模型解耦合。具体来说,即使两个算法分别应用了生成式方法和判别式方法作为相似度匹配的解决方案,其可能都应用了相同的特征,例如颜色直方图。如果我们将应用在跟踪算法中的特征作为分类的依据,这两个算法应该被归为一类。很显然,这是另一种算法分类的角度,但是却存在将两个大相径庭的算法归为一类的可能性。
在这里,我们并非否认按照特征分类的合理性,而是将关注的重点放在算法本质上的区别,即其观测模型。然而,大多数跟踪算法的综述文章都直接将跟踪算法简单的分为生成式和判别式,并没有强调这仅仅是其观测模型,让人产生为什么应用了相同特征的算法会被归为不同的类别的疑问。这种不明确对于刚开始接触跟踪领域的同学是不友好的。
在明确了我们分类的前提之后,图12示出了我们对于跟踪算法的分类以及各分类下的一些经典算法。值得注意的是,在这里我们仅将分类细化到第二层,即将生成式和判别式做进一步分类。根据不同算法的具体细节,图中的分类可以继续深化,但是这有别于此文的宗旨,即对跟踪问题的系统性的概括。
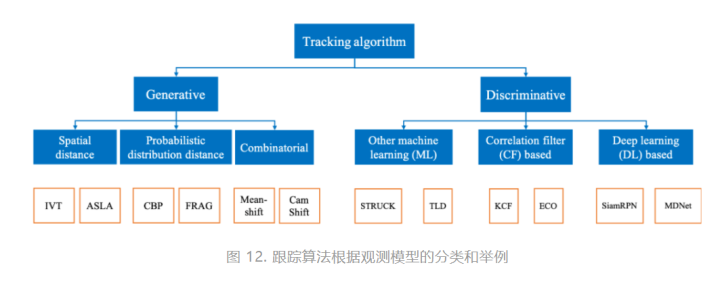
关于生成式方法,其核心思想即衡量前一帧的预测目标与当前帧候选框的相似度,然后选择最为相似的候选框作为当前帧的跟踪结果(即预测目标在当前帧的位置)。生成式方法被进一步分成下述三类:
1)空间距离 (spatial distance)
即用空间距离衡量相似度的解决方案,通常利用最优化理论将跟踪问题转换成空间距离最小化问题。利用此方法的经典算法包括IVT (Incremental learning Visual Tracking) [10] 和ASLA(Adaptive Structural Local sparse Appearance model tracking) [11]。其算法的核心思想是:计算当前帧候选框的像素灰度值与上一帧预测目标的像素灰度值之间的Euclidean distance,然后取距离最小的候选框作为当前帧的预测目标。在特征提取时应用了奇异值分解等技术来减小计算复杂度。
2)概率分布距离 (probabilistic distribution distance)
即用概率分布距离衡量相似度的解决方案,通常利用最优化理论将跟踪问题转换成概率分布距离最小化问题。利用此方法的经典算法包括CBP (Color-Based Probabilistic) [12]和FRAG (robust FRAGments-based) [13]。其算法的核心思想是:计算当前帧候选框的颜色直方图分布与上一帧预测目标的颜色直方图分布之间的Bhattacharyya distance,然后取距离最小的候选框作为当前帧的预测目标。
3)综合 (combinatorial)
这部分解决方案以MeanShift[14]和CamShift算法为代表,其模糊了对于相似度匹配的距离衡量,甚至没有显式地候选框生成过程,而是借鉴了机器学习中meanshift聚类算法的思想,在每一帧中利用上一帧预测目标的颜色直方图分布,计算该帧中相应位置的像素的颜色直方图分布,然后进行聚类得到其分布的均值,其对应的像素位置是该帧中预测目标的中心位置,然后加上候选框宽高等信息即可得到当前帧预测目标的空间位置。在MeanShift算法中,宽高信息是固定的,因此其无法应对目标尺度和旋转变化,而CamShift通过将图像矩引入相似度匹配[7],得到目标尺度和旋转信息,进一步提高了算法的性能。
如前所述,判别式方法侧重于将目标视作前景,然后将其从其它被视作背景的内容中分离出来。从某种程度上来说,判别式方法应用了分类算法的思想,将跟踪问题转换成二分类问题。众所周知,基于经典机器学习(即不包含深度学习的机器学习)和深度学习的算法对于分类问题有着非常出色的表现,因此,这些算法的思想被引入跟踪问题的解决方案是非常自然的事情。此外,判别式方法的本质仍然是解决匹配问题,而一种解决匹配问题非常有效的方法就是相关 (correlation),即用一个模板与输入进行相关操作,通过得到的响应(输出)来判断该输入与模板的相似程度,即相关性。因此,基于相关操作的算法也同样被引入跟踪问题的解决方案。判别式方法被进一步分成下述三类:
1)经典机器学习方法 (machine learning)
应用机器学习算法的思想将目标作为前景从背景中提取出来的方法。利用此方法的经典算法包括STRUCK (STRUCtured output tracking with Kernels) [15]和Tracking-Learning-Detection (TLD) [16]。STRUCK和 TLD算法分别采用经典机器学习算法中的支持向量机 (support vector machine) 和集成学习 (ensemble learning) 进行分类,并采取了一系列优化方法来提高算法的性能。
2)相关滤波方法 (correlation filter)
应用相关操作计算候选框与预测目标匹配度的方法。
3)深度学习方法 (deep learning)
上述提到的应用深度学习算法的思想将目标作为前景从背景中提取出来的方法。
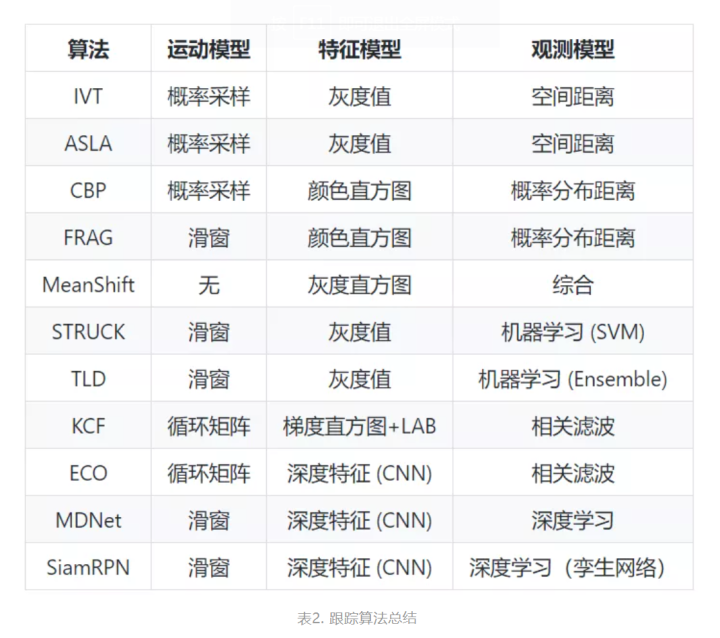
更多优秀的跟踪算法参见[1, 2, 4, 5, 9, 23]。我们将上述提到的算法总结在表2中,包括了被应用在这些算法中的运动模型、特征模型、和观测模型。表2体现了我们对整个跟踪系统架构中的不同模型的解耦合。通过表2我们可以清晰地了解每个算法在不同模型中应用了哪些方法,这有助于我们从不同的角度对算法进行分类,提炼同类算法中的共同点,以及对不同类算法进行有效地区分和对比。
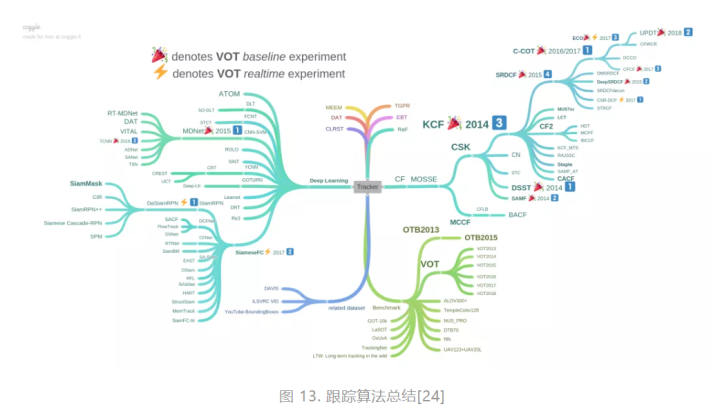
下图展示了[17]对于跟踪算法的总结:
三 如何评估视觉目标跟踪性能
评估指标
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java