
Spark的读写流程分析
导读:
众所周知,在大数据/数据库领域,数据的存储格式直接影响着系统的读写性能。spark是一种基于内存的快速、通用、可扩展的大数据计算引擎,适用于新时代的数据处理场景。在“spark的文件组织方式”中,我们分析了spark的多种文件存储格式,以及分区和分桶的设计。接下来,本文通过简单的例子来分析在Spark中的读写流程,主要聚焦于Spark中的高效并行读写以及在写过程中如何保证事务性。
1、文件读
如何在Spark中做到高效的查询处理呢?这里主要有两个优化手段:
1)减少不必要的数据处理。数据处理涉及文件的IO以及计算,它们分别需要耗费大量的IO带宽和CPU计算。在实际的生产环境中,这两类资源都是有限的,同时这些操作十分耗时,很容易成为瓶颈,所以减少不必要的数据处理能有效提高查询的效率;
以下面的查询为例:
spark.read.parquet("/data/events")
.where("year = 2019")
.where("city = 'Amsterdam'")
.select("timestamp")由于在events表中按照year字段做了分区,那么首先通过 year 字段我们就可以过滤掉所有year字段不为 2019 的分区:
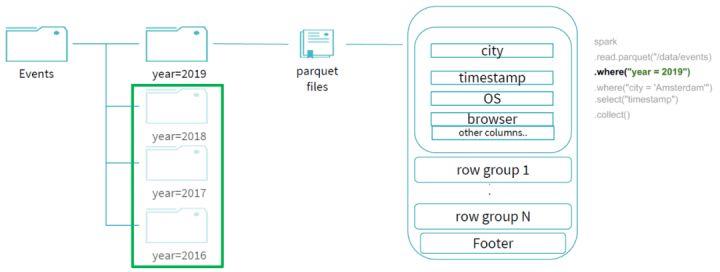
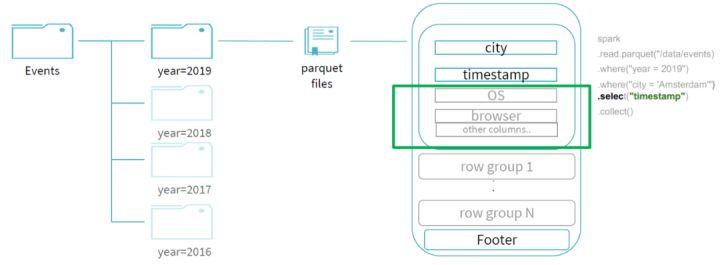
因为文件是parquet的文件格式,通过谓词下推可以帮助我们过滤掉 city 字段不是 "Amsterdam" 的 row groups;同时,由于我们的查询最终需要输出的投影字段只有 "timestamp" ,所以我们可以进行列裁剪优化,不用读取其他不需要的字段,所以最终整个查询所读的数据只有剩下的少部分,过滤掉了大部分的数据,提升了整体的查询效率:
2)并行处理,这里主流的思想分为两类:任务并行和数据并行。任务并行指充分利用多核处理器的优势,将大的任务分为一个个小的任务交给多个处理器执行并行处理;数据并行指现如今越来越丰富的SIMD指令,一次动作中处理多个数据,比如AVX-512可以一次处理16个32bit的整型数,这种也称为向量化执行。当然,随着其他新硬件的发展,并行也经常和GPU联系在一起。本文主要分析Spark读流程中的任务并行。
下面是Spark中一个读任务的过程,它主要分为三个步骤:
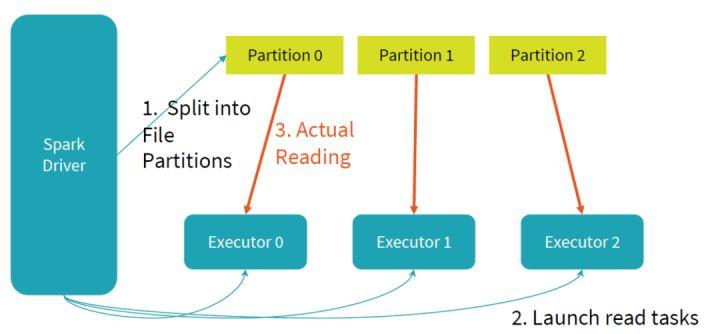
(1)将数据按照某个字段进行hash,将数据尽可能均匀地分为多个大小一致的Partition;
(2)发起多个任务,每个任务对应到图中的一个Executor;
(3)任务之间并行地进行各自负责的Partition数据读操作,提升读文件效率。
2、文件写
Spark写过程的目标主要是两个:并行和事务性。其中并行的思想和读流程一样,将任务分配给不同的Executor进行写操作,每个任务写各自负责的数据,互不干扰。
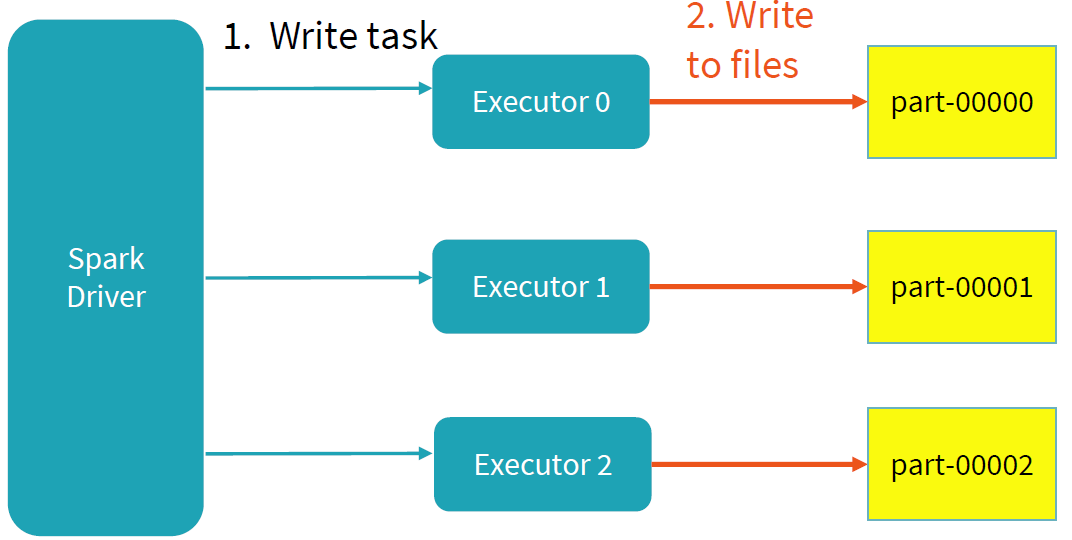
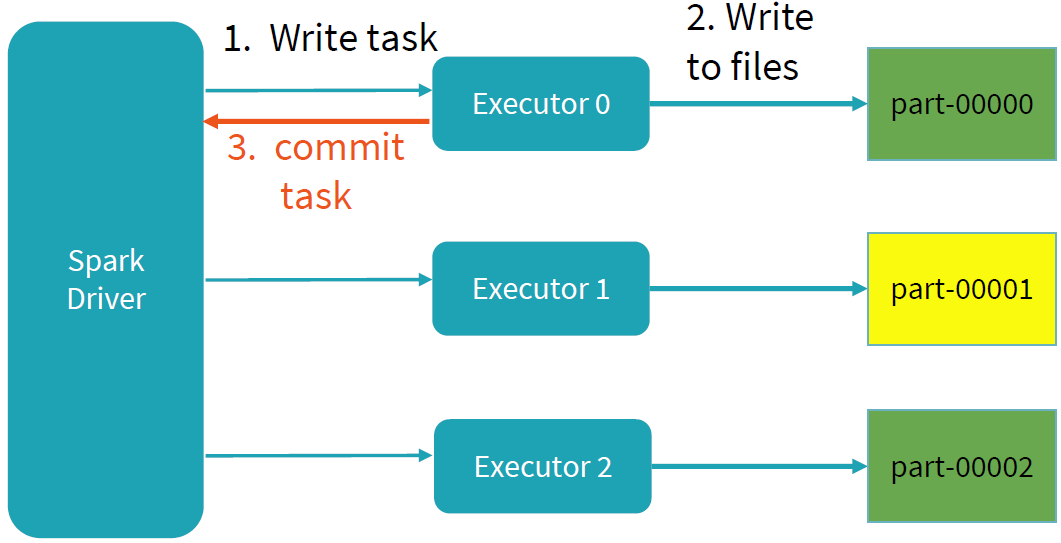
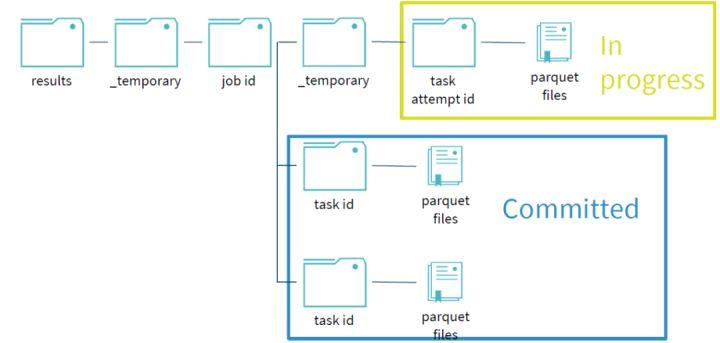
为了保证写过程的事务性,Spark在写过程中,任何未完成的写都是在临时文件夹中进行写文件操作。如下图所示:写过程中,results文件夹下只存在一个临时的文件夹_temporary;不同的job拥有各自job id的文件目录,相互隔离;同时在各目录未完成的写操作都是存在临时文件夹下,task的每次执行都视为一个taskAttempt,并会分配一个task attempt id,该目录下的文件是未commit之前的写文件。

当task完成自己的写任务时,会进行commit操作,commit成功后,该任务目录下的临时文件夹会移动,写文件移到对应的位置,表示该任务已经写完成。
当写任务失败时,首先需要删除之前写任务的临时文件夹和未完成的文件,之后重新发起该写任务(relaunch),直到写任务commit提交完成。
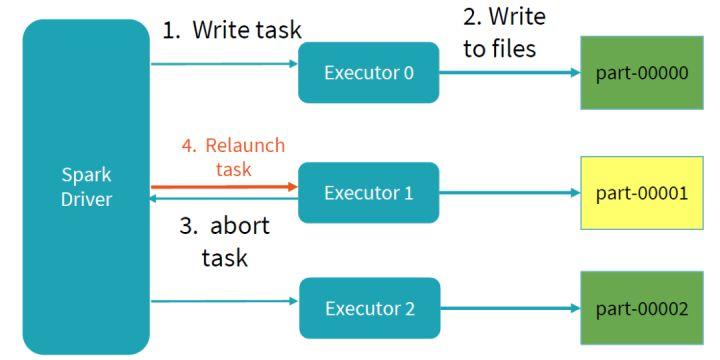
整个任务的描述可用下图表示,如果commit成功,将写完成文件移动到最终的文件夹;如果未commit成功,写失败,删除对应的文件,重新发起写任务。当写未完成时,所有写数据都存在对应的临时文件中,其他任务不可见,直到整个写commit成功,保证了写操作的事务性。

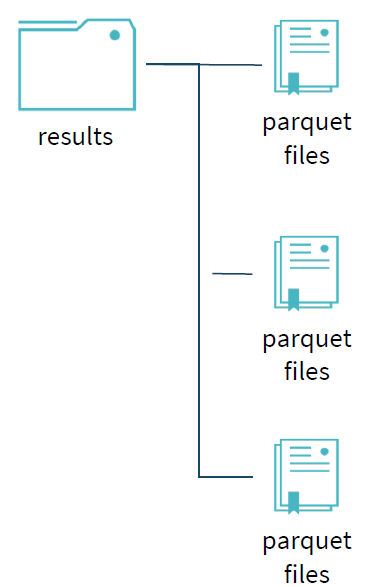
当所有任务完成时,所有的临时文件夹都移动,留下最终的数据文件,它是最终commitJob之后的结果。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java