
说说数据库的事务隔离级别
谈到事务隔离级别,开发同学都能说个八九不离十。脏读、不可重复读、RC、RR...这些常见术语也大概知道是什么意思。但是做技术,严谨和细致很重要。如果对事务隔离级别的认识,仅仅停留在大概知道的程度,数据库内核研发者可能开发出令用户费解的隔离级别表现,业务研发者可能从数据库中查出与预期不符的结果。
那么如何判断自己是不是对事务隔离级别有了较为深入的理解了呢?开发同学可以问自己这样两个问题:(1)事务隔离级别分为几类?分别能解决什么问题?是否有明确定义?这样的定义是否准确?(2)当前主流数据库(Oracle/MySQL...)的隔离级别表现和实现是怎样的?是否与“官方”定义一致?
如果能清楚明白的回答这两个问题,恭喜,你对事务隔离级别认识已经非常深刻了。如果不能,也没有关系,读完本文你就有答案了。
1.事务隔离级别
事务隔离级别,主要保障关系数据库ACID特性的I(Isolation),既针对存在冲突的并发事务,提供一定程度的安全保证。ANSI(American National Standards Institute) SQL 92标准首先定义了3种并发事务可能导致的不一致异象:
Dirty read: SQL-transaction T1 modifies a row. SQL- transaction T2 then reads that row before T1 performs a COMMIT. If T1 then performs a ROLLBACK, T2 will have read a row that was never committed and that may thus be considered to have never existed.
Non-repeatable read: SQL-transaction T1 reads a row. SQL- transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted.
Phantom: SQL-transaction T1 reads the set of rows N that satisfy some . SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy the used by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same , it obtains a different collection of rows.
嫌弃以上定义冗长,可以直接看以下形式化描述:
A1 Dirty Read:w1[x] ... r2[x] ... (a1 and c2 in any order)
A2 Fuzzy Read:r1[x] ... w2[x] ... c2 ... r1[x] ... c1
A3 Phantom Read:r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1
其中w1[x]表示事务1写入记录x,r1表示事务1读取记录x,c1表示事务1提交,a1表示事务1回滚,r1[P]表示事务1按照谓词P的条件读取若干条记录,w1[y in P]表示事务1写入记录y满足谓词P的条件。
据此,ANSI定义了四种隔离级别,分别解决以上三种异常:
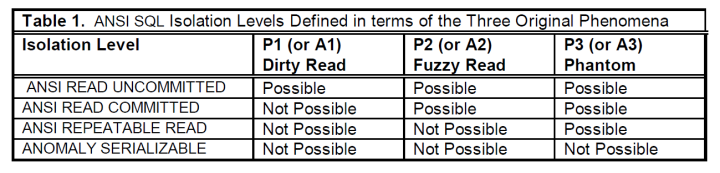
根据上述几种异常现象定义隔离级别,可谓十分不严谨,Jim Gray大名鼎鼎的论文A Critique of ANSI SQL Isolation Levels(后文简称Critique)就对此做了批判。
不严谨之一:禁止了P1/P2/P3的事务,即满足了Serializable级别。但是在ANSI标准中又明确描述Serializable级别为“多个并发事务执行的效果与某种串行化执行的效果等价”。显然这两者是矛盾的,禁止P1/P2/P3的事务,不一定能满足“等价于某种串行执行”。所以Critique将ANSI定义的禁止了P1/P2/P3的隔离级别称为Anomaly Serializable。
不严谨之二:异常现象定义不准确,如下例并未被A1囊括,却仍然出现了Dirty Read(Txn2读到x+y!=100)。同样,A2/A3也能举出这样的例子,感兴趣的同学可以自己尝试列举,这里不再详述。
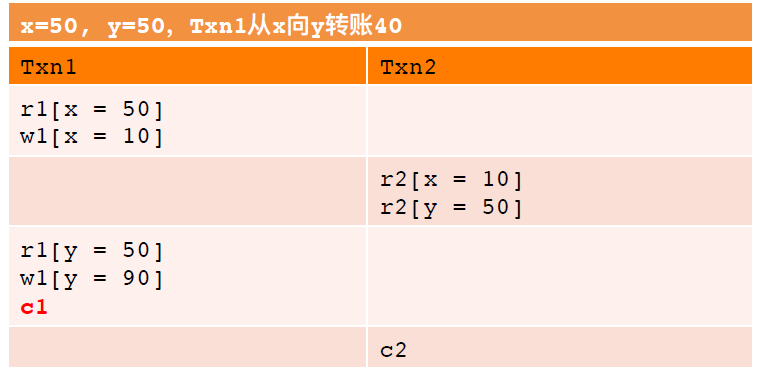
究其原因,ANSI对异象的定义太为严格,如果除去对事务提交、回滚和数据查询范围的要求,仅保留关键的并发事务之间读写操作的顺序,更为宽松且准确的异象定义如下:
P1 Dirty Read: w1[x]...r2[x]...(c1 or a1)
P2 Fuzzy Read: r1[x]...w2[x]...(c1 or a1)
P3 Phantom: r1[P]...w2[y in P]...(c1 or a1)
不严谨之三:三种异象仅针对S(ingle) V(alue)系统,不足以定义M(ulti)V(ersion)系统的隔离性。很多商业数据库所实现的SI,未违反P1、P2和P3,但又可能出现Constraint violation,不可串行化。除了P1/P2/P3,还可能出现哪些异常呢?
P4 Lost Update:r1[x]...w2[x]...w1[x]...c1
A5A Read Skew:r1[x]…w2[x]... w2[y]…c2…r1[y] …(c1 or a1)
A5B Write Skew:r1[x]…r2[y]…w1[y]…w2[x]…(c1 and c2 occur)
A5B2 Write Skew2:r1[P]... r2[P]…w1[y in P]…w2[x in P]...(c1 and c2 occur)
对这四种情况,分别举一个例子:
r1[x=50] r2[x=50] w2[x=60] c2 w1[x=70] c1
Lost Update:事务1和事务2同时向同一个账户x分别充20和10块,事务1后提交,将70块写入数据库,事务2提交结果60块被覆盖。正确的情况下,事务1和2提交成功,账户里应该有80块。
(x+y=100) r1[x=50] w2[x=10] w2[y=90] c2 r1[y=90] c1
Read Skew: x和y账户分别有50块钱,加起来共100块。事务1读x(50块)后,事务2将x账户的40块转到y账户,事务2提交后,事务1读y(90块)。在事务1看来,x+y=140,出现了不一致。
(x+y>=60) r1[x=50] r2[y=50] w1[y=10] c1 w2[x=10] c2
Write Skew:x和y账户分别有50块钱,加起来共100块。假设存在某种约束,x和y账户的钱加起来不得少于60块。事务1和事务2在自认为不破坏约束的情况下(分别读了x账户和y账户),再分别从y账户和x账户取走40。但事实上,这两个事务完成后,x+y=20,约束条件被破坏。
(count(P)<=4):r1[count(P)=3],r2[count(P)=3],insert1[x in P],insert2[y in P],c1,c2,
Write Skew2:将Write Skew的条件改为范围。
2.隔离级别实现
上一节介绍了ANSI定义的3种异象,及根据禁止异象的个数而定义的事务隔离级别。因为不存在严格、严谨的“官方”定义,各主流数据库隔离级别的表现也略有不同,一些现象甚至让用户感到困惑。我认为相较于纠结隔离级别的准确定义,认识各数据库隔离级别的表现和实现,在生产环境中正确的使用它们才是更应该关注的事情。本节将以大篇幅具体的例子为切入点,介绍几种主流数据库隔离级别的表现,及内部对应的实现。
2.1 Lock-based 隔离级别实现
在展示Lock-based隔离级别实现前,先介绍几个与锁相关的概念:
Item Lock:对访问行加锁,可以防止dirty/fuzzy read。
Predicate Lock(gap lock):对search的范围加锁,全表扫描直接对整张表加锁,可防止phantom read。
Short duration:语句结束后释放锁。
Long duration:事务提交或回滚后释放锁。
上述锁操作组合,便可实现不同级别的事务隔离标准,如下表所示。
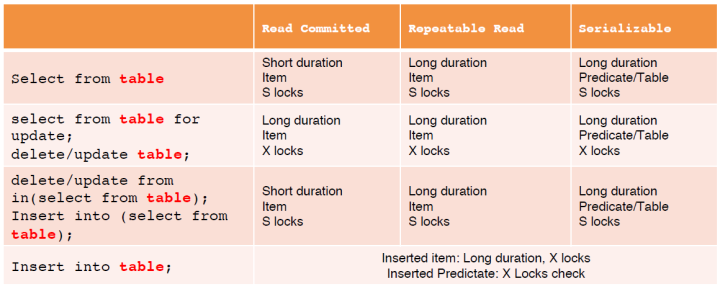
其中S lock代表共享锁,X lock代表排它锁。
首先所有写操作加X locks时,都会选择Long duration,否则short duration锁被释放后,在事务提交前该条更改可能被其它事务写操作覆盖,造成脏写(dirty write)。
其次对于读操作:
Short duration Item S lock 禁止了 P1发生,读操作如果遇到正在修改的行(写事务加了X Lock),阻塞在S Lock,直到写事务提交。
Long duration Item S lock 禁止了P2发生,写操作遇到读事务(S Lock),阻塞在X Lock上直到读事务提交或回滚。
Long duration Predicate/Table S Lock 禁止了P3发生,(范围)写操作遇到范围读操作(加Predicate S Lock),会被阻塞,直到读事务提交或回滚。
基于锁实现的三种隔离级别分别能禁止的异象如下表所示:
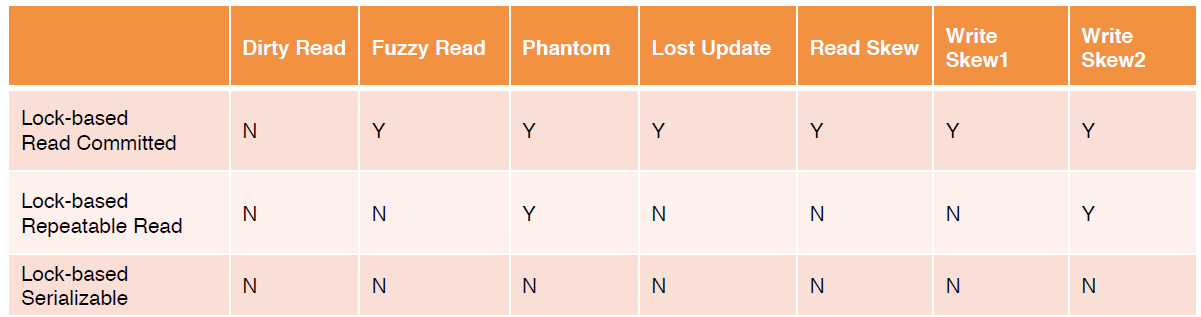
然而当今数据库基于性能等多方面考虑,很少有完全基于锁实现隔离级别的,MVCC+Lock的方式,可以满足读请求不加锁,是主流的实现方式。
2.2 Oracle隔离级别的实现
Oracle仅支持两种隔离级别:Read Committed与Serializable。尽管官方这样描述,Oracle的Serializable实际是基于MVCC+Lock based的SI(Snapshot Isolation)隔离级别。
为实现快照读,内部维护了全局变量SCN(System Commit/Change Number),在事务提交时递增。读请求获取Snapshot便是获取当前最新的SCN。Oracle实现MVCC的方式是将block分为两类:(1)Current blocks为当前最新的页面,与持久化态数据保持一致。(2)Consistent Read blocks,根据snapshot SCN生成相应的一致性版本页面。
以下两个具体的例子展示了:不同隔离级别下,读写语句在数据库内部发生了什么。

Oracle在read
committed隔离级别下,每条语句都会获取最新的snapshot,读请求全部是snapshot读。写请求在更新行之前,需要加行锁。由于写操作不会因为有其它事务更新了同一行,而停止更新(除非不满足更新的谓词条件了),因此Lost
Update有可能发生。

Oracle在serializable隔离级别下,事务开始便获取snapshot。读请求全部是snapshot读,而写请求在更新行之前,需要加行锁。写操作在加锁后,首先检查该行,如果发现:最近修改过这行的事务的SCN大于本事务的SCN,说明它已经被修改且无法被本事务看到,会做报错处理,避免了Lost Update。这种写冲突的实现,显然是first committer wins。
下表展示了Oracle的两种隔离级别,分别能够避免哪些异象:

2.3 MySQL(InnoDB)隔离级别实现
InnoDB同样以MVCC+Lock的方式实现隔离级别。其中普通select语句均是snapshot read。而delete/update/select for update等语句是加锁实现的current read,如下表所示(注:该表为Pecona 5.6版本的代码实现)。
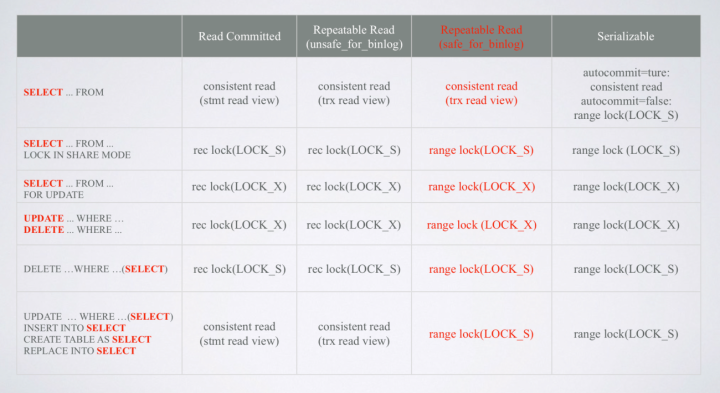
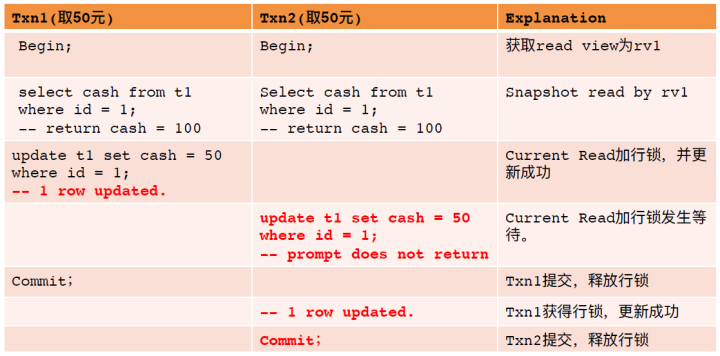
InnoDB的RC隔离级别的表现与Oracle相似。而相较于Oracle的SI,InnoDB RR隔离级别依旧不能避免Lost Update(例如下例)。究其原因,InnoDB在RR隔离级别下,不会在事务提交时判断是否有其它事务修改过该行。这避免了了SI更新冲突带来的回滚代价,带来了可能发生Lost Update的风险。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java