
递归算法Java实现实例讲解
递归算法(英语:recursion algorithm)在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。递归式方法可以被用于解决很多的计算机科学问题,因此它是计算机科学中十分重要的一个概念。绝大多数编程语言支持函数的自调用,在这些语言中函数可以通过调用自身来进行递归。计算理论可以证明递归的作用可以完全取代循环,因此在很多函数编程语言(如Scheme)中习惯用递归来实现循环。
一、什么是递归?
1.递归是一种非常高效、简洁的编码技巧,一种应用非常广泛的算法,比如DFS深度优先搜索、前中后序二叉树遍历等都是使用递归。
2.方法或函数调用自身的方式称为递归调用,调用称为递,返回称为归。
3.基本上,所有的递归问题都可以用递推公式来表示,比如
f(n) = f(n-1) + 1;
f(n) = f(n-1) + f(n-2);
f(n)=n*f(n-1);
比如下方:
int func(你今年几岁) {
// 最简子问题,结束条件
if (你1999年几岁) return 我0岁;
// 自我调用,缩小规模
return func(你去年几岁) + 1;
}//斐波那契数列
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n-1) + f(n-2);
}二、为什么使用递归?递归的优缺点?
1.优点:代码的表达力很强,写起来简洁。
2.缺点:空间复杂度高、有堆栈溢出风险、存在重复计算、过多的函数调用会耗时较多等问题。
三、什么样的问题可以用递归解决呢?
一个问题只要同时满足以下3个条件,就可以用递归来解决:
1.问题的解可以分解为几个子问题的解。何为子问题?就是数据规模更小的问题。
2.问题与子问题,除了数据规模不同,求解思路完全一样
3.存在递归终止条件
四、如何实现递归?
1.递归代码编写
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
2.递归代码理解
对于递归代码,若试图想清楚整个递和归的过程,实际上是进入了一个思维误区。
那该如何理解递归代码呢?如果一个问题A可以分解为若干个子问题B、C、D,你可以假设子问题B、C、D已经解决。而且,你只需要思考问题A与子问题B、
C、D两层之间的关系即可,不需要一层层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
因此,理解递归代码,就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
五、递归常见问题及解决方案
1.警惕堆栈溢出:可以声明一个全局变量来控制递归的深度,从而避免堆栈溢出。
2.警惕重复计算:通过某种数据结构来保存已经求解过的值,从而避免重复计算。
//优化斐波那契
public int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
// hasSolvedList可以理解成一个Map,key是n,value是f(n)
if (hasSolvedList.containsKey(n)) {
return hasSolvedList.get(n);
}
int ret = f(n-1) + f(n-2);
hasSolvedList.put(n, ret);
return ret;
}六、如何将递归改写为非递归代码?
笼统的讲,所有的递归代码都可以改写为迭代循环的非递归写法(递推)。如何做?抽象出递推公式、初始值和边界条件,然后用迭代循环实现。
//枚举是横向地把问题划分,然后依次求解子问题
//而递归是把问题逐级分解,是纵向的拆分。
/* 递推遍历,需要额外空间 O(1) */
public int size(Node head) {
int size = 0;
for (Node p = head; p != null; p = p.next) size++;
return size;
}
/* 递归,需要额外空间 O(N) */
public int size(Node head) {
if (head == null) return 0;
return size(head.next) + 1;
}//斐波那契的递推实现
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
int ret = 0;
int pre = 2;
int prepre = 1;
for (int i = 3; i <= n; ++i) {
ret = pre + prepre;
prepre = pre;
pre = ret;
}
return ret;
}七、递归遍历二叉树
代码内容来自于labuladong.gitbook,强烈推荐。
树就是一种层次的,递归结构。我们可以利用递归的思想处理大部分树的问题。
//如何判断两棵二叉树是否完全相同?
boolean isSameTree(TreeNode root1, TreeNode root2) {
// 都为空的话,显然相同
if (root1 == null && root2 == null) return true;
// 一个为空,一个非空,显然不同
if (root1 == null || root2 == null) return false;
// 两个都非空,但 val 不一样也不行
if (root1.val != root2.val) return false;
// root1 和 root2 该比的都比完了
return isSameTree(root1.left, root2.left)
&& isSameTree(root1.right, root2.right);
}//判断 BST 的合法性
boolean isValidBST(TreeNode root) {
if (root == null) return true;
if (root.left != null && root.val <= root.left.val) return false;
if (root.right != null && root.val >= root.right.val) return false;
return isValidBST(root.left)
&& isValidBST(root.right);
}//在 BST 中插入一个数
TreeNode insertIntoBST(TreeNode root, int val) {
// 找到空位置插入新节点
if (root == null) return new TreeNode(val);
// if (root.val == val)
// BST 中一般不会插入已存在元素
if (root.val < val)
root.right = insertIntoBST(root.right, val);
if (root.val > val)
root.left = insertIntoBST(root.left, val);
return root;
}//在 BST 中删除一个数
TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val == key) {
// 这两个 if 把情况 1 和 2 都正确处理了
if (root.left == null) return root.right;
if (root.right == null) return root.left;
// 处理情况 3
TreeNode minNode = getMin(root.right);
root.val = minNode.val;
root.right = deleteNode(root.right, minNode.val);
} else if (root.val > key) {
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}
TreeNode getMin(TreeNode node) {
// BST 最左边的就是最小的
while (node.left != null) node = node.left;
return node;
}八、分治算法:归并排序
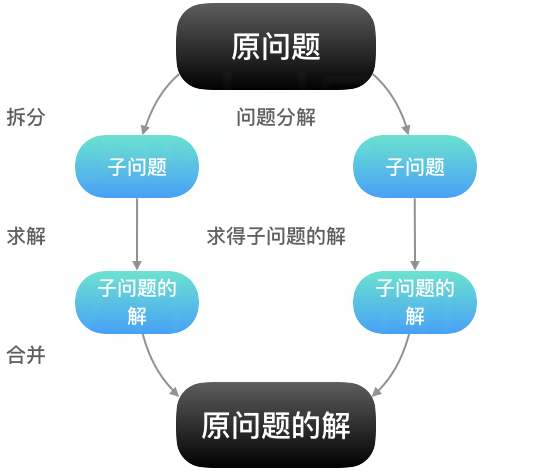
归并排序是典型的分治算法;分治,典型的递归结构。
分治算法可以分三步走:分解 -> 解决 -> 合并
分解原问题为结构相同的子问题。
分解到某个容易求解的边界之后,进行第归求解。
将子问题的解合并成原问题的解。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java