
Kubernetes 实现完美原地升级。
一、概念介绍
原地升级一词中,“升级”不难理解,是将应用实例的版本由旧版替换为新版。那么如何结合 Kubernetes 环境来理解“原地”呢?
我们先来看看 K8s 原生 workload 的发布方式。这里假设我们需要部署一个应用,包括 foo、bar 两个容器在 Pod 中。其中,foo 容器第一次部署时用的镜像版本是 v1,我们需要将其升级为 v2 版本镜像,该怎么做呢?
- 如果这个应用使用 Deployment 部署,那么升级过程中 Deployment 会触发新版本 ReplicaSet 创建 Pod,并删除旧版本 Pod。如下图所示:
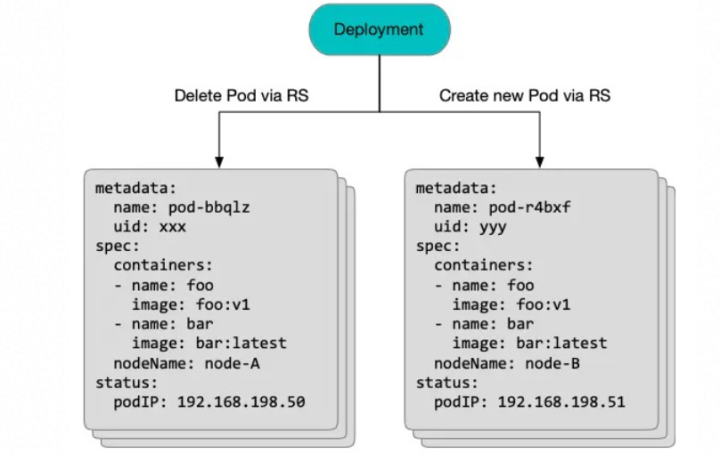
在本次升级过程中,原 Pod 对象被删除,一个新 Pod 对象被创建。新 Pod 被调度到另一个 Node 上,分配到一个新的 IP,并把 foo、bar 两个容器在这个 Node 上重新拉取镜像、启动容器。
- 如果这个应该使用 StatefulSet 部署,那么升级过程中 StatefulSet 会先删除旧 Pod 对象,等删除完成后用同样的名字在创建一个新的 Pod 对象。如下图所示:
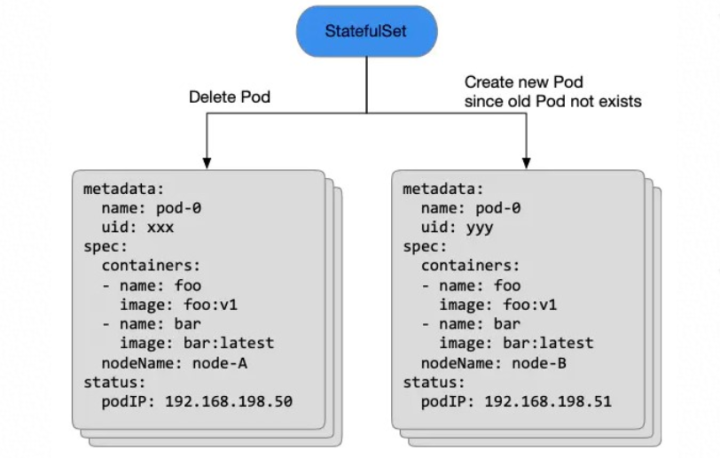
值得注意的是,尽管新旧两个 Pod 名字都叫 pod-0,但其实是两个完全不同的 Pod
对象(uid也变了)。StatefulSet 等到原先的 pod-0 对象完全从 Kubernetes 集群中被删除后,才会提交创建一个新的
pod-0 对象。而这个新的 Pod 也会被重新调度、分配IP、拉镜像、启动容器。
而所谓原地升级模式,就是在应用升级过程中避免将整个 Pod 对象删除、新建,而是基于原有的 Pod 对象升级其中某一个或多个容器的镜像版本:
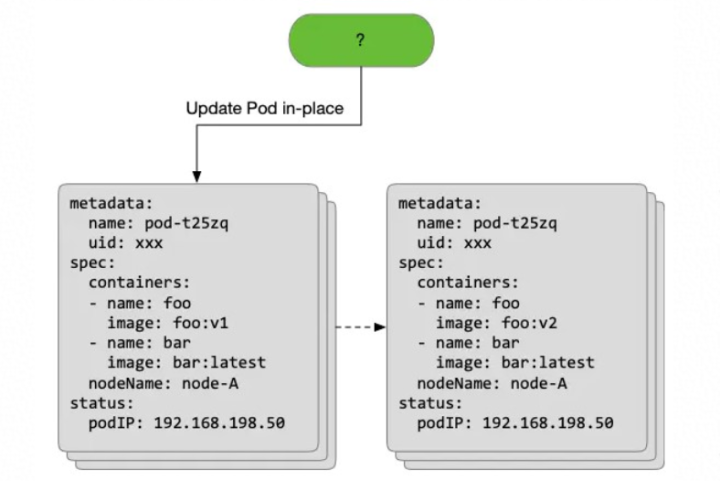
在原地升级的过程中,我们仅仅更新了原 Pod 对象中 foo 容器的 image 字段来触发 foo 容器升级到新版本。而不管是 Pod 对象,还是 Node、IP 都没有发生变化,甚至 foo 容器升级的过程中 bar 容器还一直处于运行状态。
总结:这种只更新 Pod 中某一个或多个容器版本、而不影响整个 Pod 对象、其余容器的升级方式,被我们称为 Kubernetes 中的原地升级。
二、收益分析
那么,我们为什么要在 Kubernetes 中引入这种原地升级的理念和设计呢?
首先,这种原地升级的模式极大地提升了应用发布的效率,根据非完全统计数据,在阿里环境下原地升级至少比完全重建升级提升了 80% 以上的发布速度。这其实很容易理解,原地升级为发布效率带来了以下优化点:
1.节省了调度的耗时,Pod 的位置、资源都不发生变化;
2.节省了分配网络的耗时,Pod 还使用原有的 IP;
3.节省了分配、挂载远程盘的耗时,Pod 还使用原有的 PV(且都是已经在 Node 上挂载好的);
4.节省了大部分拉取镜像的耗时,因为 Node 上已经存在了应用的旧镜像,当拉取新版本镜像时只需要下载很少的几层 layer。
其次,当我们升级
Pod 中一些 sidecar 容器(如采集日志、监控等)时,其实并不希望干扰到业务容器的运行。但面对这种场景,Deployment 或
StatefulSet 的升级都会将整个 Pod
重建,势必会对业务造成一定的影响。而容器级别的原地升级变动的范围非常可控,只会将需要升级的容器做重建,其余容器包括网络、挂载盘都不会受到影响。
最后,原地升级也为我们带来了集群的稳定性和确定性。当一个
Kubernetes 集群中大量应用触发重建 Pod 升级时,可能造成大规模的 Pod 飘移,以及对 Node 上一些低优先级的任务 Pod
造成反复的抢占迁移。这些大规模的 Pod 重建,本身会对
apiserver、scheduler、网络/磁盘分配等中心组件造成较大的压力,而这些组件的延迟也会给 Pod
重建带来恶性循环。而采用原地升级后,整个升级过程只会涉及到 controller 对 Pod 对象的更新操作和 kubelet 重建对应的容器。
三、技术背景
在阿里巴巴内部,绝大部分电商应用在云原生环境都统一用原地升级的方式做发布,而这套支持原地升级的控制器就位于 OpenKruise 开源项目中。
也就是说,阿里内部的云原生应用都是统一使用 OpenKruise 中的扩展 workload 做部署管理的,而并没有采用原生Deployment/StatefulSet 等。
那么 OpenKruise 是如何实现原地升级能力的呢?在介绍原地升级实现原理之前,我们先来看一些原地升级功能所依赖的原生 Kubernetes 功能:
背景 1:Kubelet 针对 Pod 容器的版本管理
每个 Node 上的 Kubelet,会针对本机上所有 Pod.spec.containers 中的每个 container 计算一个 hash 值,并记录到实际创建的容器中。
如果我们修改了
Pod 中某个 container 的 image 字段,kubelet 会发现 container 的 hash
发生了变化、与机器上过去创建的容器 hash 不一致,而后 kubelet 就会把旧容器停掉,然后根据最新 Pod spec 中的
container 来创建新的容器。
这个功能,其实就是针对单个 Pod 的原地升级的核心原理。
背景 2:Pod 更新限制
在原生 kube-apiserver 中,对 Pod 对象的更新请求有严格的 validation 校验逻辑:
// validate updateable fields:
// 1. spec.containers[*].image
// 2. spec.initContainers[*].image
// 3. spec.activeDeadlineSeconds简单来说,对于一个已经创建出来的
Pod,在 Pod Spec 中只允许修改 containers/initContainers 中的 image 字段,以及
activeDeadlineSeconds 字段。对 Pod Spec 中所有其他字段的更新,都会被 kube-apiserver 拒绝。
背景 3:containerStatuses 上报
kubelet 会在 pod.status 中上报 containerStatuses,对应 Pod 中所有容器的实际运行状态:
apiVersion: v1
kind: Pod
spec:
containers:
- name: nginx
image: nginx:latest
status:
containerStatuses:
- name: nginx
image: nginx:mainline
imageID: docker-pullable://nginx@sha256:2f68b99bc0d6d25d0c56876b924ec20418544ff28e1fb89a4c27679a40da811b绝大多数情况下,spec.containers[x].image 与 status.containerStatuses[x].image 两个镜像是一致的。
但是也有上述这种情况,kubelet 上报的与 spec 中的 image 不一致(spec 中是 nginx:latest,但 status 中上报的是 nginx:mainline)。
这是因为,kubelet 所上报的 image 其实是从 CRI 接口中拿到的容器对应的镜像名。而如果 Node 机器上存在多个镜像对应了一个 imageID,那么上报的可能是其中任意一个:
$ docker images | grep nginx
nginx latest 2622e6cca7eb 2 days ago 132MB
nginx mainline 2622e6cca7eb 2 days ago因此,一个 Pod 中 spec 和 status 的 image 字段不一致,并不意味着宿主机上这个容器运行的镜像版本和期望的不一致。
背景 4:ReadinessGate 控制 Pod 是否 Ready
在 Kubernetes 1.12 版本之前,一个 Pod 是否处于 Ready 状态只是由 kubelet 根据容器状态来判定:如果 Pod 中容器全部 ready,那么 Pod 就处于 Ready 状态。
但事实上,很多时候上层 operator 或用户都需要能控制 Pod 是否 Ready 的能力。因此,Kubernetes 1.12 版本之后提供了一个 readinessGates 功能来满足这个场景。如下:
apiVersion: v1
kind: Pod
spec:
readinessGates:
- conditionType: MyDemo
status:
conditions:
- type: MyDemo
status: "True"
- type: ContainersReady
status: "True"
- type: Ready
status: "True"目前 kubelet 判定一个 Pod 是否 Ready 的两个前提条件:
1.Pod 中容器全部 Ready(其实对应了 ContainersReady condition 为 True);
2.如果 pod.spec.readinessGates 中定义了一个或多个 conditionType,那么需要这些 conditionType 在 pod.status.conditions 中都有对应的 status: "true" 的状态。
只有满足上述两个前提,kubelet 才会上报 Ready condition 为 True。
四、实现原理
了解了上面的四个背景之后,接下来分析一下 OpenKruise 是如何在 Kubernetes 中实现原地升级的原理。
1. 单个 Pod 如何原地升级?
由“背景
1”可知,其实我们对一个存量 Pod 的 spec.containers[x] 中字段做修改,kubelet 会感知到这个 container
的 hash 发生了变化,随即就会停掉对应的旧容器,并用新的 container 来拉镜像、创建和启动新容器。
由“背景 2”可知,当前我们对一个存量 Pod 的 spec.containers[x] 中的修改,仅限于 image 字段。
因此,得出第一个实现原理:**对于一个现有的 Pod 对象,我们能且只能修改其中的 spec.containers[x].image 字段,来触发 Pod 中对应容器升级到一个新的 image。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java