
一套完整大规模分布式系统机器学习系统需要哪些组成部分呢?
一 背景
在云计算环境下,虚拟机的负载均衡、自动伸缩、绿色节能以及宿主机升级等需求使得我们需要利用虚拟机(VM)迁移技术,尤其是虚拟机热迁移技术,对于down time(停机时间)要求比较高,停机时间越短,客户业务中断时间就越短,影响就越小。如果能够根据VM的历史工作负载预测其未来的工作负载趋势,就能够寻找到最合适的时间窗口完成虚拟机热迁移的操作。
于是我们开始探索如何用机器学习算法预测ECS虚拟机的负载以及热迁移的停机时间,但是机器学习算法要在生产环境发挥作用,还需要很多配套系统去支持。为了能快速将现有算法在实际生产环境落地,并能利用GPU加速实现大规模计算,我们自己搭建了一个GPU加速的大规模分布式机器学习系统,取名小诸葛,作为ECS数据中台的异构机器学习算法加速引擎。搭载以上算法的小诸葛已经在生产环境上线,支撑阿里云全网规模的虚拟机的大规模热迁移预测。
二 方案
那么一套完整大规模分布式系统机器学习系统需要哪些组成部分呢?
1 总体架构
阿里云全网如此大规模的虚拟机数量,要实现24小时之内完成预测,需要在端到端整个流程的每一个环节做优化。所以这必然是一个复杂的工程实现,为了高效的搭建这个平台,大量使用了现有阿里云上的产品服务来搭建。
整个平台包含:Web服务、MQ消息队列、Redis数据库、SLS/MaxComputer/HybridDB数据获取、OSS模型仓库的上传下载、GPU云服务器、DASK分布式框架、RAPIDS加速库。
1)架构
下图是小诸葛的总体架构图。
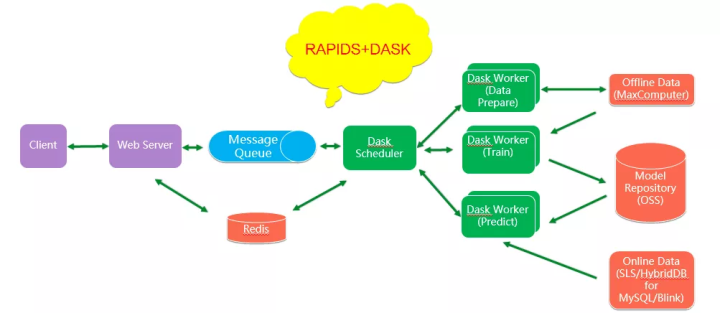
小诸葛是基于RAPIDS+DASK搭建的一个端到端的GPU加速的机器学习平台,整个平台都是基于阿里云上的产品和服务来搭建的。
我们在前端提供了一个基于Tengine+Flask的Web服务用于接受客户端发送来的数据计算请求,并利用消息队列与后端的大规模计算集群解耦。
Dask分布式框架则提供了数据准备和模型训练以及预测的计算节点的管理和调度,同时我们使用了阿里云的MaxComputer做训练阶段离线数据的处理,使用Blink等实时计算引擎做预测阶段的在线数据处理,使用HybridDB分析型数据库存放处理过的在线数据用于实时预测的数据拉取,并使用阿里云的对象存储服务OSS来获取训练数据和保存训练模型,使用GPU云服务器加速机器学习的运算。
2)设计思考
下面讲下平台的核心设计思考。
一个是分布式消息队列的使用:
- 首先可以实现前端业务平台与后端计算系统的解耦,实现业务处理异步化。
- 还可以实现高并发:使得系统支持百万以上规模的高并发读写。
- 另外,如果后端系统出现故障,消息可以在队列里堆积且不丢失,待后端系统恢复后可以继续处理请求,满足高可用。
- 消息队列的消费者可以是多套计算系统,而且多套系统可以做轮转升级,不影响前端业务,实现了高扩展。
另一个是GPU加速的分布式并行计算后端的设计:
- 计算资源选择的是阿里云的GPU云服务器。分布式并行计算框架我选择了轻量级的DASK,它更易用更灵活,可以写出自由度更高的并行计算代码,且可以与GPU机器学习加速库RAPIDS很好的结合。
- 同时通过与MaxComputer、HybridDB等多个数仓的数据链路打通,实现了一个从数据准备、离线训练到在线预测的端到端的计算平台。
- 我们在数据仓库的选择上做了很多评估和相应的优化设计工作,MaxComputer因其实时性较差用于离线训练数据仓库,SLS实时性不错但不适合大规模并发访问,对于实时预测其数据读取性能也无法满足需求,所以实时预测选择了性能和并发规模更好的Cstore(HybridDB for MySQL,现已升级为AnalyticDB)。
整个平台的搭建涉及内部多个业务团队的合作,就业务需求的分析从而确定了最终算法,以及在数据ETL和数据源性能和稳定性方面的方案确定,和就预测结果如何应用于热迁移任务执行的方案确定,最终实现了一个端到端的平台达成了业务目标。
2 消息队列
消息队列使用的是阿里云的RocketMQ。
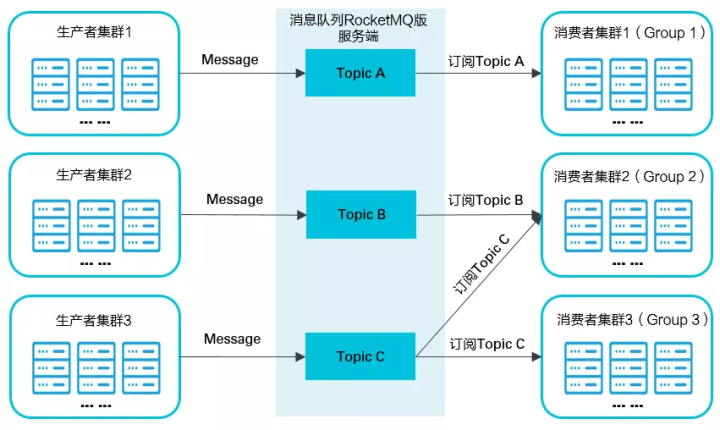
消息队列的使用需要考虑以下几个问题:
1)消息幂等
用于解决投递时消息重复的问题。
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列 RocketMQ 的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
我们使用Redis数据库记录每条消息的Message Key用于幂等性,在消费时如果发现有重复投递的消息会丢弃掉,避免消息被重复消费执行。
2)消息是无序还是顺序
对于全网预测的批量消息处理,是不需要考虑消息的顺序的,所以为了保证消息的处理性能我们选择无序消息。
3 数据处理及数据平台的选择
数据是一切的根本,首先需要解决海量数据的存储、分析和处理。
- 我们需要处理的数据可以是如下的不同种类:
- 实时数据和非实时数据
- 格式化数据和非格式化数据
- 需要索引的数据和只需要计算的数据
- 全量数据和抽样数据
- 可视化数据和告警数据
每一个分类都对应一种或者多种数据处理、分析和存储方式。
多维度和多数据源是另一个要考虑的问题。对于相对复杂的业务场景,往往需要不同维度的数据(比如我们做热迁移预测使用了实时的CPU利用率数据,还有虚拟机规格等其它多个维度的数据)综合起来考虑。同样,负载场景下也不会只产生一种类型的数据,不是所有数据都是使用统一的方式处理和存储,所以具体实践中往往会使用多个不同的数据源。
公有云上的海量数据都达到了TB、PB以上的级别,传统的数据存储方式已经满足不了需求,因此针对大数据的存储诞生了Hadoop生态。传统的系统数据存储方式在数据量达到一定规模后会带来一系列问题:性能问题、成本问题、单点故障问题、数据准确性问题等等。取而代之的是以HDFS为代表的分布式存储系统。
除了数据存储的问题,实时数据的采集也很重要。业务系统都有各自的实时日志,日志收集工具都和业务服务部署在一起,为了不和线上服务抢占资源,日志收集必须要严格控制占用的资源。同时也不能在收集端进行日志清洗和分析操作,而应该集中收集到一个地方后再处理。
就我们使用的数据仓库而言,初期选择的是ODPS(即MaxCompute,类似于开源的Hadoop系统)和SLS(阿里云的日志服务)。ODPS可作为离线数据仓库存储海量的历史数据,而SLS则存放了海量的实时监控数据(比如我们使用的ECS虚拟机的CPU利用率数据)。
但是数据太多了又会出现信息过载的情况,所以往往需要对数据做聚合后再使用(比如我们CPU利用率的预测是对原始的分钟级采样数据分别做了5分钟平均和1小时平均的聚合)。因为我们发现SLS自带的聚合计算因为计算量太大导致速度非常的慢而无法满足实际计算需求。所以数据中台使用实时计算平台Blink将聚合好的数据存放在了新的SLS仓库里供我们实际计算使用。Blink是集团内部基于Apache开源的实时计算流处理平台Flink进行定制开发和优化后的流计算平台。
在大规模的线上预测时我们又发现,SLS根本无法满足高并发、低延迟的预测数据的拉取,常常因为排队拉不到数据或者拉取速度太慢导致大幅增加预测延迟,在经过评估测试后,我们选择了ECS数据中台提供的Cstore数仓存放聚合后的数据,从Cstore拉取预测需要的数据,从而解决了高并发、低延迟预测数据的拉取问题。
4 GPU加速的分布式并行计算后端的搭建
整个分布式并行计算后端的核心是并行计算框架的选择以及GPU加速。
1)框架选择
在分布式并行计算框架的选择上,有如下一些考虑,SPARK是目前大数据计算的主流分布式并行计算框架,但受限于CPU的性能和成本及SPARK任务无法获得GPU加速(当时搭建小诸葛的时候,SPARK还没有提供GPU加速的完善支持,后来发布的SPARK 3.0预览版开始已经提供了GPU加速的支持,这块的工作我们一直在保持关注和投入,后续会更新相关进展),无法满足全网大规模预测的需求,我们选择了DASK这个轻量级的分布式计算框架结合GPU加速库RAPIDS在GPU云服务器加速我们的算法。
我们利用DASK并行框架惰性计算的特点及提供的代码打包分发所有Dask Worker能力,将Worker执行代码通过Dask Scheduler分发到各个Worker节点,并在后端消息队列消费者收到计算任务后再通过Dask Client将执行任务递交到Dask Scheduler,由Dask Scheduler负责将计算任务调度到指定的Worker节点上完成相应的计算任务。可以看到DASK框架的架构和执行流程跟Spark是很像的,只不过Dask更轻量级一些,且是Python语言生态的框架,适合集成RAPIDS。
根据业务需求,我们设计了以下几种计算任务:数据准备任务、训练任务、预测任务,并为不同的任务配置了相应的Dask Worker完成相应计算。与此相适应的消息队列也设计了相应的消息Topic,Web Server也设计了相应的统一的HTTP报文格式。
训练和计算任务的Worker部署在GPU服务器上,而数据准备阶段目前没有GPU加速则部署在CPU服务器上。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java