
搜索推荐系统:内容图谱结构化与索引更新平台。
一 背景
搜索推荐系统作为在线服务,为满足在线查询性能要求,需要将预查询的数据构建为索引数据,推送到异构储存介质中提供在线查询。这个阶段主要通过 Offline/Nearline 把实时实体、离线预处理、算法加工数据进行处理更新。这里包含了算法对这些数据离线和在线的处理,不同业务域之间最终数据合并(召回、排序、相关性等)。在平台能力方面采用传统的数仓模式即围绕有共性资源、有共性能力方面建设,形成分层策略,将面向业务上层的数据独立出来,而这种模式在实现业务敏捷迭代、知识化、服务化特征方面已不能很好满足需求。

知识图谱作为对数据进行结构化组织与体系化管理的核心技术,实际面向业务侧应用过程中能很好的满足知识化、业务化、服务化方面的诉求,基于内容图谱体系的特征平台建设,以内容(视频、节目、用户、人物、元素等)为中心,构建一个实时知识融合数据更新平台。
二 设计概要
基于搜索推荐系统数据处理链路一般包括以下几个步骤:从内容生产端(媒资、互动、内容智能、包罗、粮仓、琳琅等)接收 dump 出来的全量数据和业务侧增量数据,然后业务侧拿到这些数据按业务域进行一层一层加工,最终通过 build 构建索引进入到引擎端。
不同于其它业务场景,在优酷场景中我们接收的内容生产端并不是源头生产端,中间掺杂了很多半加工的异源异构数据,数据的一致性(逻辑一致性、功能一致性)是摆在用户侧实际性面临问题,特别实时和全量产出的数据需要保持结构一致,同时搜索引擎的字段结构保持一致。我们从数据结构化组织与业务体系化管理方面进行索引平台更新设计。
1 数据结构化组织
设计文娱大脑面向应用侧的中间层,将知识图谱引入中间层,实现了面向业务领域的数据组织方式。将知识图谱融入在中间层数据模型这一层,用包含实体、关系、事件、标签、指标的知识图谱统一视图来定义面向领域的数据模型。将视频领域知识图谱作为中间层数据组织的基础,实现面向业务领域数据组织方式的转变。
2 业务体系化管理
将算法的逻辑以组件化的模式进行封装,实现了业务方只需要维护一套逻辑,实时和全量一套代码,采用统一 UDF 来实现。利用 Blink 的流批一体化的架构,实现全增量架构模式,如在数据清洗订正逻辑时进行全量(实时引擎中做到了消息不丢的机制保证,不需要每天实现全量),让全量数据走一遍逻辑。

三 关键模块
1 特征库
特征库包含两层:第一层是全增量一级特征计算,对接不同的数据源(包括实时和离线),在特征域计算中不存在离线全量,对于冷数据或修正数据采用存量的全集重新走一次流处理。数据组织储存在顶点和边关系表中。实时更新过程中为了减少对上游反查导致的性能压力,不同实体属性变更直接走内部图查询,统一封装 DataAPI 对这些数据进行操作,不同类型顶点采用独立 blinkjob 进行计算。
离线数据组织方面,由于搜索引擎在线服务的机器并不持久化数据。当新的在线机器加入集群时需要从某个地方拉取全量索引文件进行数据装载,我们组装一个和索引模型一样全量文件。全量文件只是某一个时间戳的快照,全量文件时间戳越早需要追的实时消息就越多,故障的恢复速度就越慢,需要有一个机制尽量及时产出最新全量文件,减少实时增量消息带来的性能压力。
二级特征计算,面向算法的接入,包含了搜索的相关性、排序、召回这层直接面向业务域,它直接消费一级特征库中的数据,业务主要逻辑集中到这层进行计算,此时实时离线逻辑主要通过组件库来完成。
2 组件库
不同业务线算法按各自业务从同一份数据中获取自身需要的数据进行处理加工,无形中就导致代码的重复。组件库建立主要开放适配接口,让相同功能代码得以复用,减少重复开发。
组件库将业务逻辑抽象成简单的基于 UDF 的算术表达式来组织,简单、简洁,并且更易维护,特征使用方,只需关注特征粒度,不需要关注整体。
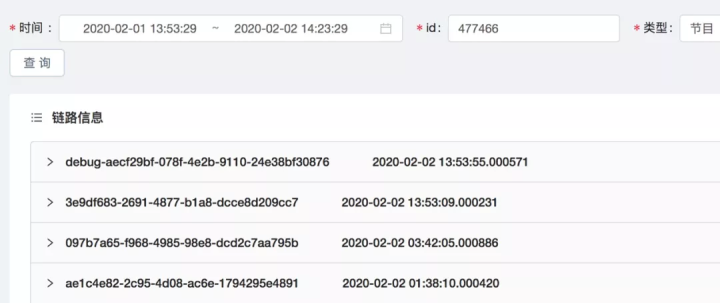
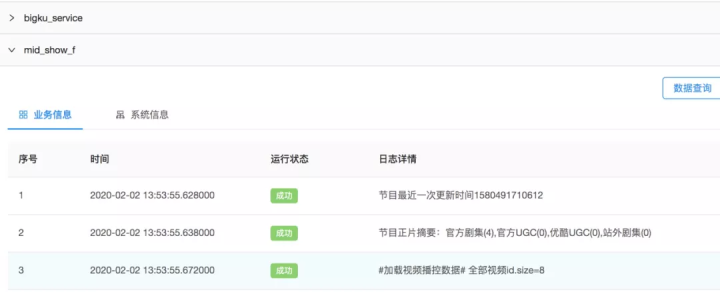
3 Trace&Debug 模块
每一个消息有唯一签名(uuid),源头数据会在各个计算流程中流转,处理过程中为了便于业务更好追踪处理流程问题,将不同系统数据按 uuid 和实体 id 进行聚合,通过 Trace&Debug 服务能较好理解业务处理过程信息和系统处理信息。
四 技术细节
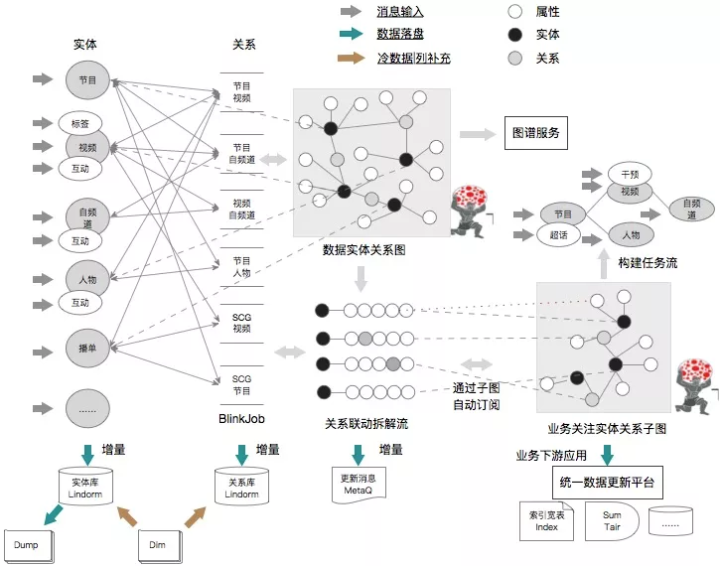
整体计算框架采用新一代的实时计算引擎 Blink,主要优势在于流批一体化,业务模块通过 job 切分,不同的计算模块可以随意组合;消费位点自动保存,消息不丢失,进程 failover 自动恢复机制;分布式的计算可消除单点消费源和写入性能瓶颈问题。储存引擎采用 Lindorm 进行实体数据储存,主要利用 Lindorm 二级索引来储存 KV 和 KKV 数据结构,用于构建知识图谱的底层数据。
1 知识图谱储存和组织
采用标签属性图(Labeled Property Graph,LPG)建模,Lindorm 作为主储存,实体表(视频、节目、人物等)作为顶点表,实体间关系利用 lindorm 的二级索引能力作为边表。
数据访问方面,实现数据驱动层,提供给外部使用接口 API,开发人员通过本地 API 来操纵 Lindorm。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理,屏蔽了 java 代码属性和 Lindorm 列值的转换以及结果查询的取值映射,使用注解用于配置和原始映射,解决 java 对象直接序列化到 Lindorm 的行列储存问题。
2 计算和更新策略
采用 Blink 计算平台实现特征计算和索引更新,由于采用了全增量架构,在全量更新过程减少上游服务反查的压力,采用列更新策略。在不同实体属性或边表属性(边表属性为了减少图查询过程中顶点查询的压力开销)更新采用级联更新策略,即属性更新后生成新的消息推送到总线链路端,不同实体或关系订阅消息后按需进行自身属性更新。
更新一个业务核心诉求就是一致性,其本质就是不丢消息和保序,我们采用 MetaQ 作为主消息管道,本身具备不丢消息,更多是在外部服务、储存、处理链路层面上失败情况。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java