
机器学习相关技术最重要的函数:误差函数和偏差
说起机器学习就不能不提到误差函数,基于梯度下降算法的机器学习问题本质上都可以抽象成误差函数的优化过程。误差函数的设计上决定了机器学习任务的成败,本文我们就来聊聊误差函数。
偏差
偏差是指对某个人、某个群体或某个事物所持有的一种有失公允的偏袒或反对。随着机器学习日渐成为我们日常生活中不可或缺的一部分,问题也随之而来,即机器学习是否也存在偏差?在本文中,我将深入探究这个问题及其产生的影响,并探讨消除机器学习模型偏差的多种方法。
在助力自动驾驶汽车、准确识别 X 光照片中的癌症以及根据过往行为预测我们的兴趣等众多方面,机器学习展现出的潜力都令人叹为观止。但是,机器学习在带来诸多优势的同时,也带来了许多挑战。其中一大挑战就是,机器学习的分类和预测存在偏差。这些偏差并非是善意的。根据机器学习模型产生的决策,这些偏差会导致各种各样的后果。因此,务必要了解机器学习模型中是如何引入偏差的,该如何测试是否存在偏差,以及如何消除偏差。
偏差问题
用于评估已定罪罪犯的量刑和假释的工具 (COMPAS),即是机器学习中存在偏差的一个例子。由于许多监狱人满为患,人们希望通过评估来识别再次犯罪可能性较低的囚犯。随后,仔细审查这些囚犯,看看能否先行释放,以便为后续新入狱罪犯留出空间。通过关于囚犯的大量问题来定义一个风险评分,其中包括某个囚犯的父母是否曾入狱或者其友人或熟人是否曾入狱这样的问题(但不包括种族问题)。
人们已经发现此工具能够成功预测已定罪罪犯成为累犯的可能性,但当在判断公式中引入了种族时,预测就出现了错误。值得指出的是,COMPAS 开发公司后续提供了数据来支持其算法得出的结果,因此陪审团对此仍未有定论,但这也指出了偏差是否存在这个问题。这些方法将受到质疑,并且需要后续提供数据来证明其公平性。
在各种用例中,机器学习被视为人力资源领域的关键工具,从提供培训建议到招聘和其他战术活动,皆有所涉及。2014 年,Amazon 开始开发一套系统来筛选求职者,以此来自动执行根据求职者简历上的文本识别要寻找的关键求职者这一流程。但 Amazon 后来发现,在为工程角色挑选人才时,此算法似乎更偏向于男性而不是女性。在发现此算法缺乏公平性并多次尝试在其中注入公平性之后,Amazon 最终放弃了这套系统。
Google Photos 应用程序可通过识别图片中的对象对图片进行分类。但人们在使用该程序时,发现这里存在某种种族偏见。Amazon 的 Rekognition 是一套商用人脸分析系统,这套系统同样被发现存在性别和种族偏见。
最后一个例子是微软的 Tay Twitter 机器人。Tay 是一个对话式 AI(聊天机器人),通过在 Twitter上与人们互动来学习。此算法挖掘公共数据来构建对话模型,同时也在 Twitter 上不断从互动中学习。遗憾的是,Tay 经历的互动并非都是正面的,Tay 领悟了现代社会的偏见,这甚至体现在机器模型中,正所谓"种瓜得瓜,种豆得豆"。
偏差的影响
无论存在何种偏差,机器学习算法的建议都对个人和群体产生了切实的影响。包含偏差的机器学习模型可以通过自我实现的方式,帮助偏差延续下去。因此,当务之急是要检测出这些模型中的偏差,并尽可能地摒弃这些偏差。
偏差的来源
关于偏差的出现,可以简单地将其归结为是数据产生的结果,但其源头却难以捉摸,通常与数据来源、数据内容(它是否包含模型应忽视的元素?)以及模型本身的训练(例如,在模型的分类环境中如何定义好坏)有关。
如果机器学习算法仅仅是根据日间驾驶视频来训练的,那么允许模型在夜间驾驶就会导致悲剧性的结果。这不同于人为偏见,但也证明了确实存在对于手头问题缺乏代表性数据集这一现象。
偏差的出现也可能会是我们所始料不及的。以 Amazon 的招聘工具为例,该模型对于某些求职者的用词进行了罚分,而对另一些求职者的用词则给予了奖分。在这个例子中,遭罚分的用词是女性通常使用的带性别色彩的词汇,而女性在这个数据集中同样缺乏足够的代表性数据。Amazon 的工具主要是利用 10 年间男性的简历进行训练的,这就导致了根据男性间使用的语言而倾向于男性简历这样一种偏差。
即使是人类也可能无意间放大机器学习模型中的偏差。人类的偏见可能是无意识的(也称为隐性偏见),这表示人类甚至可能会在自己毫不知情的情况下引入偏见。
让我们来研究一下如何检测机器学习模型中的偏差,以及如何消除这些偏差。
偏差的类型
在机器学习开发领域的诸多领导者所提供的工具中,机器学习数据集和模型的偏差问题同样也屡见不鲜。
检测偏差先从数据集开始。数据集可能无法体现问题空间(如仅使用日间行车数据来训练自动驾驶车辆)。数据集还可能含有可能不应予以考量的数据(例如,个人的种族或性别)。这些分别被称为样本偏差和偏见偏差。
由于数据在用于训练或测试机器学习模型之前通常会经过清理,因此还存在排除偏差。当我们移除个人认为不相关的特征时,就会出现这种情况。当收集的训练数据不同于生产期间收集的数据时,就会产生测量偏差。当通过某种特定类型的相机收集数据集,而生产数据却来自于具有不同特征的相机时,就会发生此情况。
最后还有算法偏差,它并非源自用于训练模型的数据,而是来自机器学习模型本身。这包括导致产生不公平结果的模型开发方式或模型训练方式。
误差函数概念/原理
误差函数一种量化模型拟合程度的工具,机器学习(基于梯度下降算法)的基本思想是设计一个由参数 θ 决定的模型,使得输入 x 经过模型计算后能够得到预测值,模型的训练过程是用训练数据 xi 输入模型计算得到预测值并计算预测值和真实值 yi 的差距 L,通过调整模型的参数 θ 来减小差距 L 直到这个差距不再减小为止,这时模型达到最优状态。 误差函数就是被设计出来的一个关于 θ 的用来衡量预测值和真实值之间的差距的函数,这样通过求的最小值,就可以获得一个确定的 θ, 从而够得到最佳预测结果的模型。所以机器学习实际上是一个通过优化误差函数(求最小值)来确定 θ 的过程。在小批量梯度下降(Mini-batch gradient descent)算法中,通常求平均值作为批量的误差来作为反向传递 (back propagation) 的输入,即 batch_size=m 时,
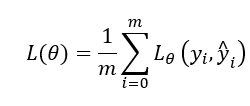
特性
基于梯度下降的优化问题
数学意义上的优化问题一般有两类解法,一个是解析方法(analytical optimization),适用于存在解析解(closed-form solution),另一种是迭代优化(iterative optimization)方法用于不存在解析解的情况,梯度下降(Gradient Descent)属于迭代优化的一种典型方法。现实中的机器学习模型中由于使用非线性激活函数(nolinear activation)所以无法直接计算导数为零时误差函数的解,因此只能使用基于梯度下降的优化方法,如图 1 所示对于一个可导的凸函数,从任意一点出发,沿着倒数下降的方向前进直到倒数为零的点,就是函数的最小值。
图 1. 梯度下降优化算法

可导性
虽然从数学原理上梯度下降要求误差函数连续可导,但在实践中误差函数允许存在不可导的点,这是因为随机梯度下降算法(Stochastic Gradient Descent,SGD)使用小批量数据的误差均值进行求导,这样使得落在不可导的点上的概率很低。因此可以对 Hinge loss 这样的不连续的函数使用梯度下降来进行优化。事实上即使在某组数据真的发生小概率事件导致求导失效,由于小批量梯度下降算法使用了大量的分组,绝大多数可求导的分组仍然可以保证在整个数据集上有效运行。
非凸性
对于所有的凸函数,使用梯度下降都可以找到最小值,但是在实际的机器学习任务中,由于模型参数的数量很大(如 VGG16 有 1个参数),这时的误差函数是凸函数的概率非常低,函数表面会呈现出非常复杂的形态。图 2 展示了某个二元模型的误差函数的形态,可见其中有很多区域导数为零,但显然他们并不都是最小值,甚至不是局部最小值。数学上将导数为零的点成为关键点,误差函数表面主要有以下几类关键点:
图 2. 误差函数表面上的关键点
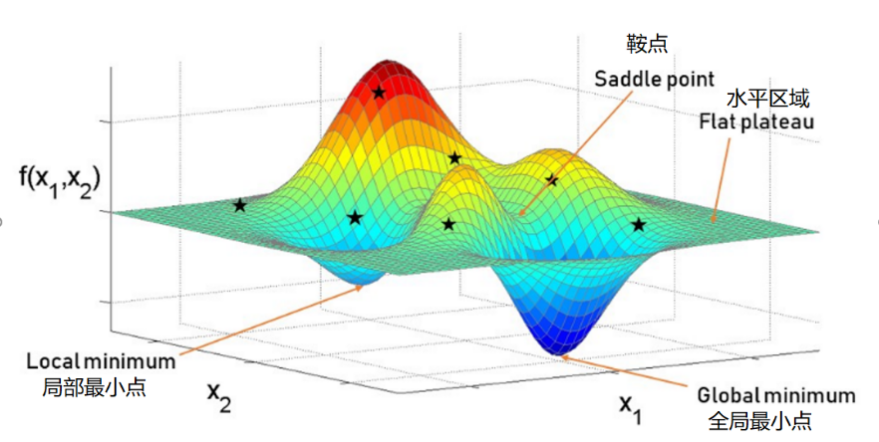
- 水平区域(flat plateau),是指在一个其中所有的点的导数都为 0 的区域,在三维空间中的水平区域就是水平面, 如何避免陷入水平区域一直是一个讨论较多的话题,目前常见的方法有:
- 适当的参数初始化
- 使用替代误差函数(surrogate function)
- 调整优化器(如增加动量 momentum)
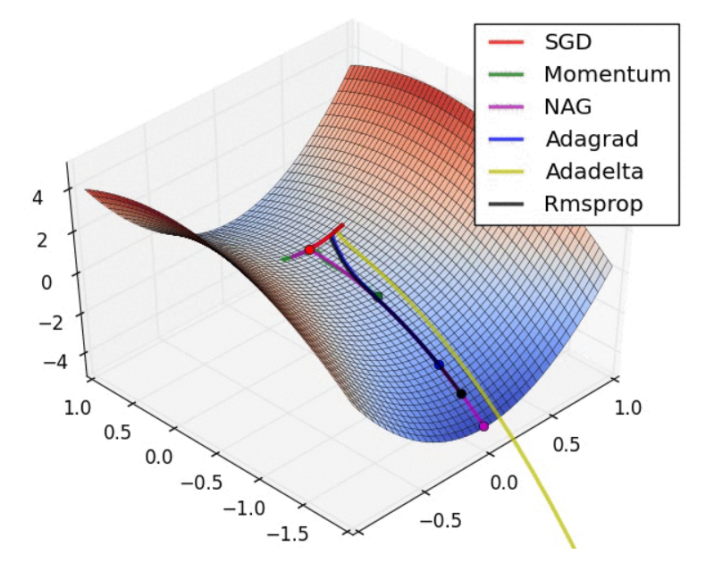
- 鞍点(saddle point),是指一阶导数为零二阶导数符号相反的点,如图 2 中所示。由于在高维度误差函数的所有导数为 0 的点中,只有在所有维度具有相同的凹凸性(即二阶导数都大于 0 或小于 0)的时候误差函数才会处于极值(局部最小值或者全局最小值),任何一个维度的凹凸性不同于其他的维度都会使误差函数处于鞍点,考虑到实际的误差函数通常会有万或十万(甚至百万)级的维度数量,因此鞍点是非常普遍的。大量的试验表明,使用随机梯度下降 SGD 选择具有动量或可变学习率(adaptive learning rate)的优化器(如 Adagrad, Rmsprop)就可以有效的脱离鞍点,如图 3 所示。
- 局部最小值(local minimum), 通过大量实践发现在高维度的优化问题中,局部最小值和全局最小值通常没有太大的区别,甚至在有些情况下比全局最小值有更好的归纳能力(泛化能力)。
总结来说,使用随机梯度下降算法 SGD,结合合适的优化器(例如 momentum) 以及合适的参数初始化可以有效找到非凸函数的最优解(接近最优解)。
图 3. (引用参考资源 1)
泛化(Generalization)
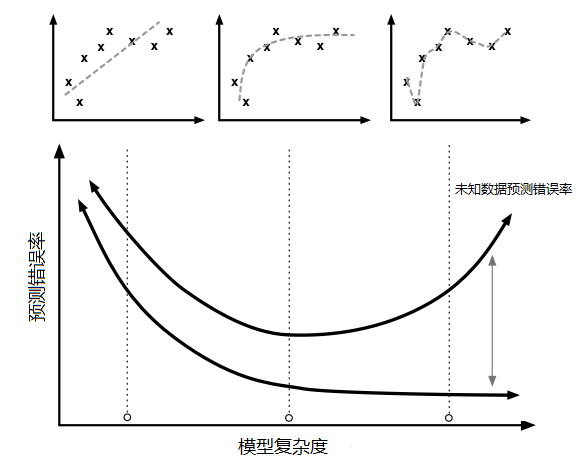
机器学习的最终目的是提高对未知的输入进行预测的准确率,也叫泛化能力。误差函数虽然可以引导梯度下降算法进行模型的优化,但是一个常见的问题是模型虽然达到了很高的训练准确率,但是泛化能力并没有提高甚至反而降低,这就是过拟合(overfitting)。图 4 中,左中右三个小图分别表示了欠拟合,正常和过拟合的情况。右侧的过拟合模型具有三个模型中最复杂的函数形态,可以看到随着训练准确率的提升,这个复杂函数对陌生数据的预测准确率反而下降了。这种问题源自于模型为了提高训练准确率学习了训练数据中的噪声从而导致模型和真实规律产生偏差。
正则化(regularization)是解决过拟合问题的常见方法之一,它把原误差函数和参数的模(norm)相加形成新的目标函数,再使用梯度下降对这个目标函数求最小值。这样做的目的在于通过降低参数维度来增加模型的泛化能力,由于参数的模变成了目标函数的一部分,因此梯度下降也会尽力降低参数的模,而参数的模和参数的维度正相关,因此梯度下降会降低参数的维度,从而避免生成过度复杂的函数,最终增强泛化能力。
图 4. (引用参考资源 2)
误差函数的分类
根据不同类型机器学习任务可以将误差函数主要可以以下三类:
- 适用于回归问题(Regression)的误差函数,这种误差函数的目标是量化推测值和真实值的逻辑距离,理论上我们可以使用任何距离计算公式作为误差函数。实践中为常用的是以下两种距离:
MSE(Mean Squared Error,L2)
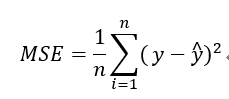
MAE(Mean Absolute Error, L1)
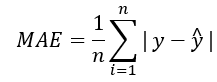
- 适用于分类问题(classification)的误差函数,分类问题的目标是推测出正确的类型,一般使用概率描述推测属于某种类型的可能性,因此误差函数就需要能够计算两个概率分布之间的"距离",最常用的此类方法是
Cross entropy loss。

- 多任务问题 此类问题是指使用一个模型同时学习多个指标,比如使用深度学习解决计算机视觉中的目标定位(object
localization)问题,模型需要同时学习对象类型和对象位置两个指标,因此误差函数需要具备同时衡量类型误差和位置误差的能力,常见的做法是先分别设计类型误差函数
Lclass 和位置误差函数
Lposition,在按一定比例(由超参数 α 和 β
确定)合并这两个误差从而形成一个新的复合误差函数 L 来综合的反应总误差。

如何设计误差函数
误差函数不仅仅是误差的衡量工具,更重要的是梯度下降算法会为了不断缩小误差而沿着误差函数的导数方向调整模型参数,因此可以说误差函数它决定了模型学习的方向。使用不同的误差函数我们可以在完全相同的模型架构(model architecture)的基础上学习出不同的模型参数,来达到不同的目的。比如,在多层卷积神经网络架构上使用 cross entropy loss 可以判断图像对象的类型(是猫还是狗),而同样的网络架构配合复合误差函数则可以用来进行目标定位。从某种程度上说模型设计决定了能力,误差函数设计决定了方向。 那么如何设计(选择)误差函数呢?可以从以下几个方面考虑。
任务目标
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java