
链路追踪技术的应用及实践
分布式架构的兴起推动了一些新技术的发展。其中链路追踪技术以其在APM领域的优异表现,成为了分布式架构中不可或缺的一部分。在本文中,我们将谈谈它的一些经典应用场景,以及笔者所在的团队如何利用链路追踪技术提升团队的研发效能。
链路追踪背景
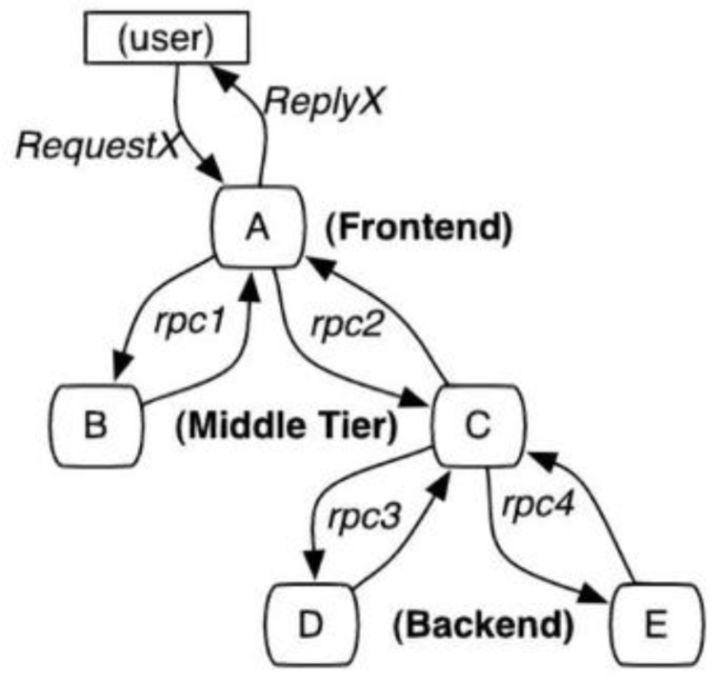
如图所示,在微服务体系中,一个请求往往需要多个服务协作处理。
凡事有利必有弊,这种模式在给我们带来更好的可扩展性的同时,也带来了一些新的问题。例如,排查问题的困难:任意节点的异常都可能导致上游链路的异常,难以追根溯源;系统拓扑复杂难以把控,健壮性存在隐患。
2010年,谷歌发表了一篇论文,介绍了谷歌的内部链路追踪系统Dapper的设计,链路追踪技术自此进入社区的视野。
下面,我们将简单介绍其在APM领域的应用,以及在服务依赖治理和研发效能提升方面的实践。
服务依赖治理
不合理的依赖,可能导致边缘系统的故障拖垮核心服务,威胁到分布式系统整体的稳定性。通过链路追踪数据的汇总分析,我们可以绘制出系统间的依赖拓扑,为依赖治理提供数据支撑。
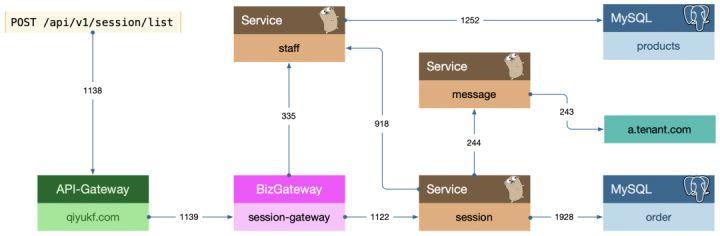
我们一般会从下面三个角度来评估服务依赖的合理性:
- 反向依赖。反向依赖指高等级服务依赖了低等级服务。例如,租户服务是我们的核心服务之一,而统计服务重要性相对较低,显然,我们不允许租户服务依赖统计服务。通过服务拓扑图和服务等级的结合,我们可以很容易的将反向依赖分析自动化,实时预警。
- 强弱依赖。强依赖指下游服务发生异常时,将影响当前节点的稳定性。在设计时,我们应该充分考虑强依赖在当前场景中的必要性。强依赖是否可以弱化,如果不能,业务场景是否允许加上熔断降级之类的的保护措施。强弱依赖的梳理,我们可以结合故障注入工具,产出系统化的报告。
- 环状依赖。环状依赖往往是边界不清晰的表现,绞成一团,层次不清。对环状依赖的梳理也是我们对业务边界和系统边界的梳理,对系统整体健康度的提升非常有意义。
研发效能提升
随着业务的发展,研发团队的规模在一定阶段也会相应地不断提升,但支撑我们研发活动的基础设施却没有办法线性增长,这其中最重要的就是联调或测试环境。
业务发展往往导致并行迭代的增多,而这些并行迭代难免会改动到相同的服务,尤其是一些核心基础服务。如下图,
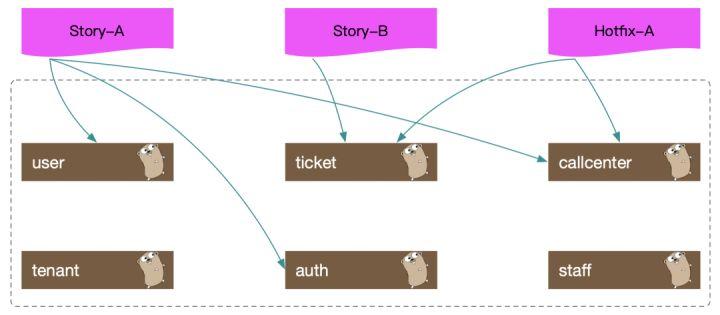
这就会导致两个问题——
1. 环境争夺。如图,Story-B需要部署ticket服务,与此同时Hotfix-A也等待验证,同样需要部署ticket服务,这意味着至少有一方会被阻塞等待,这种串行模式,极大地降低了我们的交付效率。并行迭代越多,效率降低越明显。
2. 环境的稳定性。服务之间是相互联系的,任何服务的不稳定都可能会导致该环境的不稳定。上图中的auth服务,几乎要被所有的业务流程使用。如果Story-A部署auth服务时,重启/部署的过程不够平滑,或者Story-A的代码中存在某些bug,那么会造成整个测试环境的不稳定。
项目规模不大时,我们往往能通过一些管理手段来协调。例如版本串行化,通过将迭代计划错开,避免在同一个时间段都要去部署某个服务。测试环境只部署特定分支,需要验证时则将各自的代码都合并到此分支;要求部署到测试环境的代码必须达到某种标准以提升测试环境的稳定性。
然而我们也可以看到,管理手段的有效性是和团队规模微服务规模反相关的,我们需要有技术手段来达到更好的效果。
细想一下,其实问题的根源是大家共用一套测试环境,所以我们的研发活动出现了资源竞争,我们对某个服务的操作可能影响到其他服务。
那么,能否让大家都能轻松创建各自的环境,且各个环境的使用互不影响呢?

如上图,Story-A需要部署user和auth服务,那么我们创建env-1并部署我们的user和auth; Story-B需要部署ticket服务,那么我们就创建env-2并部署ticket服务;env-3同理。
为了描述方便,我们把上图中的env-x环境,叫测试环境;图中的下半部分,叫回归环境。测试环境只包含本次迭代需要部署的应用,回归环境包含所有应用。
当我们使用这套机制时,我们期望env-1的使用者,请求user和auth服务时只会路由到env-1环境,请求其他服务时路由到回归环境。env-2环境的使用者,请求ticket服务时只会路由到env-2环境,请求其他服务时同样路由到回归环境。
也就是说,对于环境使用者的请求,如果相关的应用在该环境内,则请求只会被该环境内的应用处理,否则路由到回归环境处理。
回归环境是一个包含所有服务的相对稳定的环境,开发和提测不允许在回归环境部署,以此来保证足够的稳定性。
研发流程方面,我们不再像以前一样部署到大家都在使用的环境中去验证,而是各自创建各自独享的环境,在自己的环境中完成相关工作。
我们将上述机制称之为环境隔离,要实现环境隔离,技术侧至少需要实现两方面的能力:
- 识别并传递请求对应的环境信息
- ⼲预中间件的实例选择/消费规则
(一)识别并传递请求对应的环境信息
首先,我们需要能将请求和测试环境关联起来。
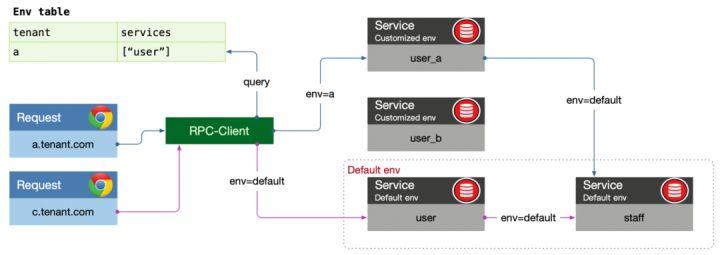
识别请求对应的环境信息,这意味着我们在创建测试环境时需要指明某种标识,且这种标识我们可以从请求中提取出,从而通过双方标识的匹配来完成关联,这种标识可以是用户账号、某组IP,或者企业租户,使用哪种方式不重要,重要的是结合业务特点达到方便易用的目的。
例如,在我们的SaaS系统七鱼里,我们使用租户id来作为我们的标识。在我们的平台创建测试环境时,除了指明要部署的应用外,我们还需要输入租户信息,通过这种方式完成请求和测试环境的映射。
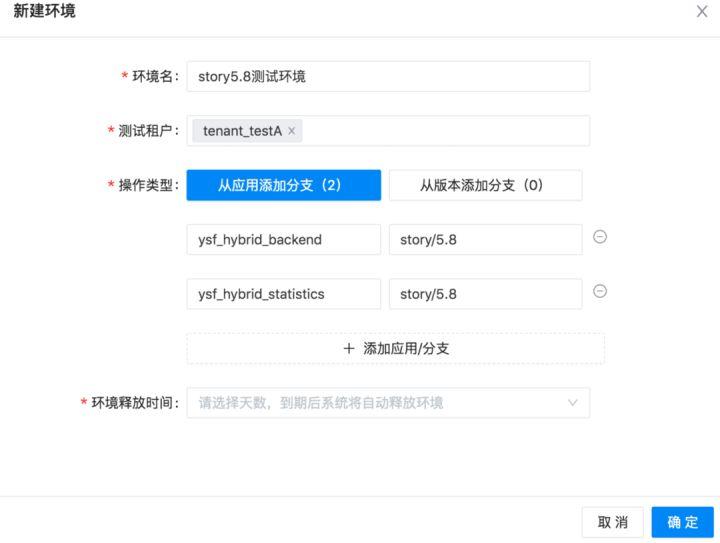
我们可以在请求的统一入口处(例如,网关),获取到请求所属的租户,之后我们可以进一步拿到它所属的环境信息(环境ID、应用列表)。类似于链路跟踪系统在请求链中传输TraceID,我们在请求链中附加上环境信息,为环境隔离打下基础。
(二)⼲预中间件的实例选择/消费规则
我们以微服务架构中最常用的几个组件为例,谈谈环境隔离的实现方式。
RPC框架——
RPC的核心流程:provider实例将自己注册到注册中心,consumer通过注册中心获取provider实例列表,根据一定的实例筛选策略和负载均衡算法,选择其中一个实例发起调用。
所以改造的手段很明确,provider启动时,我们在元数据中写入环境ID。在实例选择时,我们从请求的链路数据中拿出环境ID与之做匹配。
需要特别注意的是,匹配不到符合要求的实例时,我们不能简单的认为no provider而让程序报错,我们需要考虑该provider所属的应用是否在对应环境应用列表中,如果不在,我们需要将请求路由到回归环境中。
消息中间件——
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java