
图数据和复杂网络表示的原理,算法和应用
一、 引言
图数据在我们的世界中广泛存在,如社交网络,知识图谱,交通网络等。以知识图谱为例,它已经成为很多智能系统的支柱,如搜索引擎,推荐系统等。知识图谱中的一个核心问题是图结构(包括结点和边)的表示,好的知识表示可以帮助知识图谱更加完善以及知识图谱上层的应用。图表示的挑战主要在于图数据规模的大幅度增长(如搜索引擎背后的知识图谱、大规模电商知识图谱可以达到 TB 甚至 PB 规模)以及图数据的复杂性(结点和边的相互作用,结点属性,图的高阶特征如子图等)。本文介绍清华大学 AMiner [1] 团队近几年在复杂网络表示方面的工作,以下分为网络表示的基本原理,算法和应用三方面来介绍。
二、 网络表示(Network Embedding)的基本原理
一般来讲,我们将图定义为:$G = {V, E, X}$,其中VV是结点的结合,E \subseteq V \times XE⊆V×X 是图上边的集合,X \in \mathbb{R}^{|V|\times d}X∈R∣V∣×d 是每个结点的初始语义特征。网络表示的目标是为图中的结点学习潜在的表示 Z \in \mathbb{R}^{|V|\times d_z}Z∈R∣V∣×dz,并且希望ZZ可以包含图结构的信息(如结点之间相似度)以及结点的语义特征。
DeepWalk [2] 和 LINE [3] 是网络表示学习的两个经典算法。DeepWalk 的主要思路是在图上进行随机路径采样,将采样得到的结点序列看做自然语言中的句子。之后,利用语言建模中的经典方法 SkipGram [4] 方法进行优化,SkipGram 的思路是用一个结点去预测同一个序列中周围的结点。不同的是,LINE 的目标是保持图中结点之间的“一阶”和“二阶”相似度。一阶相似度是结点和其直接邻居之间的相似度。二阶相似度可以理解为结点和它“两跳”邻居的相似度。
基于此,项目组提出基于矩阵分解的知识统一表示学习方法NetMF [5],从理论上证明已有的多种网络表示学习方法(DeepWalk、LINE 等)都可以归一化到矩阵分解理论框架下,提出了网络表示学习的新思路。NetMF为基于 SkipGram 和负采样的网络表示学习方法提供了理论基础。
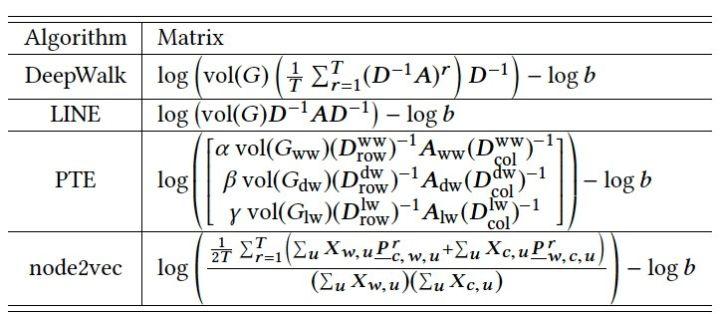
表1:DeepWalk, LINE, PTE, node2vec 隐式分解或逼近的矩阵
表1展示了几个网络表示代表性方法 DeepWalk, LINE, PTE, node2vec 所隐式分解或逼近的矩阵。这几个方法均是网络表示学习前期的代表性方法。具体来说,NetMF证明了(1)当DeepWalk随机游走的步长足够长时,它实质上概率收敛到网络的拉普拉斯矩阵的低秩表示;(2)LINE理论上可以被看做是DeepWalk的特殊情形,它假设随机游走的窗口大小为1;(3)PTE [16]是LINE的扩展,它联合分解了多个网络的拉普拉斯矩阵;(4)node2vec [17]是在分解一个关于网络上二阶随机游走的平稳分布和转移概率矩阵。
同时,NetMF 还提升了网络表示的精度,DeepWalk, LINE 等使用10%训练数据获得分类的 F1-Score 是12-29%,NetMF 在相同数据集上的 F1-Score 是 18-38%。截止目前(2020年5月),NetMF 是数据挖掘顶级会议WSDM 2018上被引用次数最多的论文。
为了进一步提升 NetMF 算法的可扩展性,项目组提出 NetSMF [6] 算法,将网络表示学习看做稀疏矩阵分解问题。NetSMF 的网络表示精度和 NetMF 相当,并且能够对大规模网络进行表示。在比较的算法中,只有 NetSMF 和 LINE 能够在一天之内得到亿级网络的结点表示。
此外,项目组从理论上挖掘了“负采样”技术在网络表示学习的作用,并提出一个统一的负采样技术 MCNS 来优化各种网络表示学习算法 [20]。负采样技术的目的是在网络上寻找与结点 vv 不相似的点u'u′。众多网络表示学习算法如 DeepWalk 和 LINE 均采用了负采样技术,很多负采样方法沿用了语言模型 Word2Vec 中的负采样方法,使得负采样分布和结点度数的3/4次成正比。然而,大部分研究关注于如何进行正采样(寻找与结点vv相似的点uu),如用随机游走,二阶相似度,社区结构来寻找相似的结点,很少有研究系统性得研究负采样技术对网络表示学习的影响。项目组发现,对于优化目标函数和减小方差,负采样在理论上和正采样同样重要。并且,负采样的分布应该和正采样的分布正相关且呈次线性关系。基于此理论,MCNS用自对比(self-constrastive)估计来逼近正采样分布,并且利用Metropolis-Hastings算法加速计算。
项目组将提出的MCNS算法与不同应用场景中的负采样方法进行比较,包括信息检索、推荐系统、知识图谱补全等8个负采样方法,并且在3个代表性的下游任务,3种代表性网络表示学习算法,5个不同类型数据集上总计19种实验设计下进行了实验,MCNS 可以稳定得到更好的表示用于下游任务。
三、网络表示的算法
下面,我们介绍项目组提出的其他网络表示学习算法,他们分别侧重于网络表示学习的不同方面。
(一)大规模网络上的快速结点表示 ProNE [7]。ProNE 借鉴了网络表示学习可以建模为矩阵分解的思路。传统的矩阵分解复杂度是 O(n^3)O(n3),这里n是网络中结点的数量,这对于大规模矩阵分解通常是不可行的。ProNE通过负采样方法构造一个稀疏矩阵进行分解,由此避免了直接分解邻接矩阵的平凡解。具体地,ProNE 巧妙得将稀疏矩阵构造为 l=-\sum_{(i,j)\in D} [p_{ij} \ln\sigma(r_i^Tc_j) + \lambda P_{D,j} \ln (-r_i^Tc_j)]l=−∑(i,j)∈D[pijlnσ(riTcj)+λPD,jln(−riTcj)],其中 P_{D,j}PD,j 是上下文结点v_jvj相关的负例,r_i^Tc_jriTcj用向量内积来刻画结点之间的相似度。此优化框架下的稀疏矩阵分解的复杂度可达到 O(|E|)O(∣E∣),即网络中边的数量级。
稀疏矩阵分解后得到的结点表示只捕捉了网络中的局部信息。除此之外,ProNE 利用高阶 Cheeger 不等式,对图的谱空间进行调制,让初始分解得到的结点表示在调制后的谱空间内进行传播。从高阶 Cheeger 不等式中可以推断,小的拉普拉斯矩阵的特征值控制着图被划分成几个大的子图的划分效果;大的特征值控制着图被划分为许多个小的子图的划分效果,可以理解为局域的聚类效果或平滑效果。因此,ProNE 希望通过控制谱空间的大特征值和小特征值来控制图的高阶全局以及局域的划分聚类效果。首先,将网络的拉普拉斯矩阵进行调制 \tilde{L} = U diag([g(\lambda_1),...,g(\lambda_n)]U^T)L~=Udiag([g(λ1),...,g(λn)]UT),这里可以根据图的特点采用带通或低通滤波等。之后在新图上传播结点表示,从而将全局的聚类信息或者局域的平滑嵌入到图表示,提高图表示的表达能力,具体的操作为 R_d = D^{-1}A(E_n - \tilde{L})R_dRd=D−1A(En−L~)Rd,其中,D^{-1}AD−1A是归一化的邻接矩阵,E_nEn是单位矩阵,R_dRd是结点表示矩阵。
ProNE 能够快速计算大规模网络中的结点表示,对于亿级网络结点表示,单线程的ProNE 比20线程的 LINE 更快(LINE是比较方法中最快的算法)。此外,ProNE 在调制谱空间中传播结点表示的方法也能够显著提升其他网络表示学习算法的精度,如DeepWalk, LINE, Node2vec [8] ,提升的相对幅度在10%以上。

图1:ProNE 谱传播方法可以显著提升多种网络表示学习算法
(二)富属性多重边的异构网络表示学习 GATNE [9] 。很多网络表示学习方法关注于单类型的结点和单类型的边,GATNE 考虑了更复杂场景下的网络表示学习。现实中的网络结点和边可能有多种类型,每个结点可能有丰富的属性。比如,在电商知识图谱中,结点有用户、物品等不同类型,边有“点击”、“购买”等不同类型,商品有价格,描述,品牌等属性。GATNE 设计了一个统一的网络表示框架,能够同时建模了结点的基本表示(Base Embedding), 结点的属性表示,边的表示。结点ii关于边类型rr表示的计算方式为 v_(i,r)=b_i+α_r M_r^T U_i a_(i,r)v(i,r)=bi+αrMrTUia(i,r),其中,b_ibi是结点的基本表示(与其边的类型rr无关),α_rαr是超参数,U_iUi是结点ii相关的边的表示,a_(i,r)a(i,r)代表了注意力(attention)系数,M_rMr是训练参数。

表2:(来自论文 [9])GATNE与不同类型网络表示学习算法的比较
GATNE 能够支持对知识图谱中的新结点进行表示学习(inductive settings)。此时,新结点的属性特征用于生成其表示 v_{i,r} = h_z(x_i)+\alpha_r M_r^T U_ia_{i,r} + \beta D_z^T x_ivi,r=hz(xi)+αrMrTUiai,r+βDzTxi,这里,zz表示结点的类型,h_zhz是一种特征转换函数,D_zDz是训练参数。GATNE 的训练方式是基于元路径的随机游走和异构 SkipGram,例如,采样的路径会根据预先设计的元路径(如:用户-商品-用户)。随机路径采样生成的正例,以及在异构网络中负采样得到的负例相结合,来最小化负对数似然。
GATNE在多个复杂网络数据(如亚马逊、Youtube,阿里巴巴数据)上进行验证,对生成的结点表示进行链接预测,比已有方法如metapath2vec [18],MNE [19] 等F1值提升6%~28%。此外,GATNE很容易并行化,能够生成亿级复杂网络的结点表示。GATNE已经被应用于阿里巴巴的推荐场景,并且被阿里巴巴图神经网络计算平台 AliGraph和百度的Paddle Graph Learning (PGL) 平台实现。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java