
比 Redis 还要高性能的键值存储服务Faster结构说明
介绍了一款支持高并发的kv store,在单台机器上可实现1.6亿OPS的高吞吐,远胜于其它纯内存数据结构的性能。
亮点在于1.6亿的高吞吐,实现方式比较独特,但细读下来发现faster在工程上有比较多的限制,很难产品化。不过许多技术细节和想法或许可以借鉴。
Faster实现主要分为三部分:
Epoch Protection框架,实现并发系统下全局修改,延迟同步到所有线程,简化并发设计。faster线程在大多时候不需要同步,完全独立执行。
支持高并发的无锁hash 索引,是实现高吞吐的关键。
Hybrid Log,使用逻辑地址将内存和二级存储统一起来,数据超出内存大小后可flush到硬盘,使其能够支持超出内存大小的数据量。
Faster的限制包括:只支持点查,不支持range query;基本只适合update-intensive的场景;不写wal(影响update性能),恢复后部分数据丢失。
Instrduction
faster支持三种接口,read和两类update: blind update和read-modify-writes(RMWs)。RMWs指在原来的value上原子更新,支持记录的部分更新(比如只更新value的一个字段)。faster是一个point-operation系统,在内存中可实现亿级别的吞吐,尤其在支持超过内存限制的数据量下依然能保持如此高的性能。可见在设计和实现上的确做了比较大的努力和创新的。
首先为支持可扩展的线程模型,faster扩展了标准的epoch-based同步机制,通过trigger action促进全局changes延迟同步到所有线程,这个epoch框架帮助faster简化了并发设计。
然后介绍了无锁、高并发和cache友好的hash索引的设计,与纯内存allocator结合使用时,就是一个内存的kv系统,性能和扩展性高于其它热门的纯内存结构。
最后介绍了HybridLog。log-structuring技术可以支持超出内存限制的大数据量的存储,通过写wal支持failure recovery,基于read-copy-update的策略,记录的更新都是追加写的方式写入log中。但是这样的方式限制了吞吐和扩展能力,in-place更新是性能的关键。因此,faster提出了HybridLog:内存与append-only log的方式结合,热数据支持in-place更新,冷数据read-copy-update,先copy到热数据区域再in-place更新。
faster遵循大多数case可以fast的原则,在以下三个方面做了精细的设计:
1.实现无锁高并发的哈希索引对于记录提供快速的point访问。
2.选择合适的时机做耗时的操作,像hash索引扩容、checkpoint和淘汰等。
3.大多数时候可以做in-place更新。
faster在内存负载下的性能是远超出于其它纯内存系统的,而且是在支持数据量超出内存限制和支持热点数据集变化的情况下。
Epoch Protection Framework
Epoch不是新概念,已被Silo、Masstree和Bw-Tree用于资源回收。faster将其扩展,成为更通用的框架,主要用于memory-safe garbage collection、hash索引表扩容、log-structured allocator的circular buffer的维护和page flushing、page边界维护和checkpoint。
Epoch Basics
系统维护一个sharded原子计数变量E,叫做当前的epoch,每个线程都可以增加它的值。每个线程T都有一个本地的E,用Et表示。线程周期地刷新本地的epoch值,每个线程的epoch值都保存在sharded epoch table中。如果所有线程的本地epoch都比epoch c大,则认为c是安全的。faster额外维护了一个全局的Es,用于记录最大的安全的epoch。对于任意线程T,都满足Es<Et<E。
Trigger Actions
使用trigger action使这个框架具备当一个epoch变为安全时执行任意全局action的能力。当前的epoch从c增加为c+1时,线程额外关联一个action,该action在epoch c变为safe时触发。
Using
对于线程T支持4种操作:
Acquire: 为T保留一个entry,将Et设置为E
Refresh: 更新Et到E
BumpEpoch(action): 更新c到c+1,<c, action>
Release: 将T的entry从epoch table中移除
使用trigger action的epoch在并行系统中可以简化延迟同步。一个典型的例子:当共享变量status变为active时,需要调用函数active-now。线程更新自己的status到active,并将active-now作为trigger action,并不是所有线程可以立马看到status改变,但是可以保证当线程refresh它的epoch时可以看到。因此只有当所有线程都看到status变为active才会调用active-now。
THE FASTER HASH INDEX
faster高性能hash index的特点有concurrent、latch-free、scalable和resizable。与普通的hash table实现不一样,不保存key值,保存记录set的物理或者逻辑地址,纯内存下是物理地址,混合存储下是逻辑地址。
索引组织
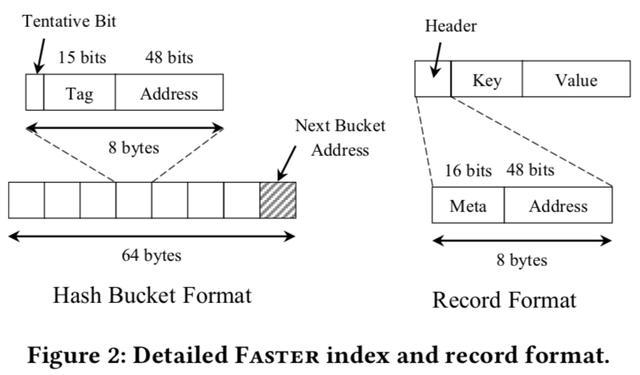
该设计假设64位系统cache line大小为64bytes。索引有2^k个hash bucket,每个bucket的size为cache line的大小:64bytes。一个bucket包含8个entry和一个指向下一个bucket的指针。8字节entry的设计可以使用64位原子的操作。
64位的机器上,物理地址通常小于64位,intel机器使用48位的指针。因此它这里只用48位来存储地址,剩余15位叫做tag,用于hash,一位叫做tentative bit,用于insert过程中的两阶段算法。
索引操作
hash index建立在一个保证的基础之上:每个(offset, tag)对应唯一一个entry。address指向记录的set,这点跟普通hash table很不一样,hash index中不保存key,而是指向记录的set,将冲突放到value中解决。
支持以下操作:
finding and deleting an entry: 根据key值直接定位到bucket中的entry,先根据offet定位到对应bucket,再遍历找到匹配tag的entry。删除entry使用CAS原子操作用0替代掉匹配的entry。0表示是空的entry,可以使用。
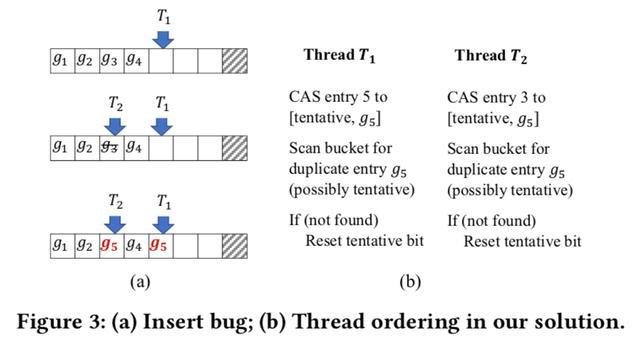
inserting: tag不存在时,insert到一个新的entry。图3(a)展示了通常的操作方式,遍历bucket中的entries找到空的entry,使用CAS将新的tag insert,但是存在两个线程并发将相同的tag写入的问题。如图3(a)所示,T1从左到右遍历entry找到第5个entry并写入g5,与此同时,T2将g3删除,然后从左到右遍历entry找到第三个entry并写入g5。
这个问题的本质原因是线程独立地选择entry并且直接修改它。可以使用lock bucket的方式来解决,但是太重了。faster使用无锁的两阶段的方式来解决,借助于tentative位,线程找到空的enty写入新的记录并设置tentative位,一个被设置了tentative位的entry对于读写是不可见的,然后再重新扫描bucket检查是否存在相同的tag,如果存在则返回重试,否则重置tentative位完成insert操作。图3(b)展示了这个操作。
In-memory, Log-Structured and HybridLog
论文先讲了纯memory实现和纯log-structered的实现,最后将两者结合起来形成最终的HybridLog。
记录的格式为图2所示由8个字节的header、key和value组成,key和value可以是定长也可以是变长的,header分为16位的meta和48位的地址,用少量的位保存一些log-structured allocator所需要的信息,地址用于维护记录链表。
In-memory
纯memory的实现中,记录只保存在memory中,使用底层分配器像jemalloc分配内存,hash index中保存物理地址,支持read、update and insert和delete操作:
reads:根据key定位到hash index的entry,遍历记录list找到key值对应的记录。
updates and inserts:支持blind update和RMW update,使用in-place更新的方式。在epoch protection下,线程可以安全的in-place更新记录。如果entry不存在,按照上述hash index的两阶段方式写入,如果list中找不到此记录,使用CAS操作原子地将新记录写入到list的尾部。
deletes:使用CAS操作将记录从list中移除,当entry删除时,将entry设为0,标识entry是空闲可用的。删除记录后,内存不能立马释放,因为可能有并发的update存在,faster使用epoch protection解决,每个线程维护一个thread-local的空闲<epoch,address>,当epoch变为safe后可以将其释放。
Log-Structured
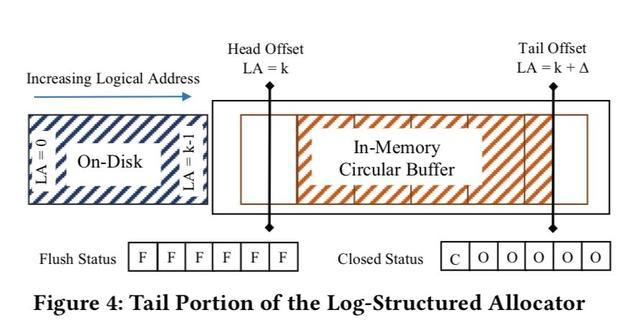
纯log-structered的实现中,使用逻辑地址将内存和磁盘统一起来,用追加log的方式将记录写入。可以支持大数据量存储,论文第7章测试了性能不超过2000w的ops,也不可随着线程数scale。实现上使用两个offset分别维护内存的最小逻辑地址和下一个空闲地址的offset,称为head offset和 tail offset。内存分配总是从tail offset处分配,head offset与tail offset之间的空间是内存的容量,这里叫做Circular Buffer,是定长pages组成的array,与物理page对应。
为实现无锁的方式将记录flush到磁盘上,引入了两个状态数组,flush-status记录当前flush磁盘的page,closed-status决定是否page可以被淘汰。要淘汰的page必须要保证已经完全flush到磁盘了。当tail offset增大时,使用epoch机制的trigger action触发异步io请求将page flush到磁盘,epoch安全后调用,确保所有线程在这个page上的写都完成了,设置flush-status。
随着tail offset的增长,头部page需要从内存中淘汰,需要先确保page没有线程在访问,传统数据库一般使用latch pin住这个page,faster为了实现高性能,还是借助于epoch管理淘汰。
Blind update就是简单的将新的记录append到log的尾部。delete记录通过header中标志位识别,资源回收时会识别。Read和RMW操作与内存中相似,只是update是追加写一条新记录,逻辑地址跟纯内存中的物理地址处理也不同,如果地址大于head offset,则数据在内存中,否则提交异步的读请求到磁盘。
HybridLog
log-structured可以处理超出内存大小的数据量,但是append-only的特征会带来一些代价:每次update都需要原子更新tail offset,拷贝数据,原子更新hash index中的逻辑地址。而且update-intensive的负载下,很快会到io瓶颈。在这种负载下,in-place更新有以下优点:
1.频繁访问的记录可放在更高层级的cache中
2.不同hash桶的key值访问路径不会有冲突
3.large value的部分更新可以避免复制整个记录
4.大多数更新不需要修改hash index

HybridLog将Log分为了三个部分:stable 磁盘部分、read-only和mutable部分。统一为一套逻辑地址,read-only和mutable都在内存中,其中只有mutable部分可以原地更新,保存hot data,read-only部分的数据更新操作需要先将其copy一份到mutable中,再在mutable中原地更新。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java