
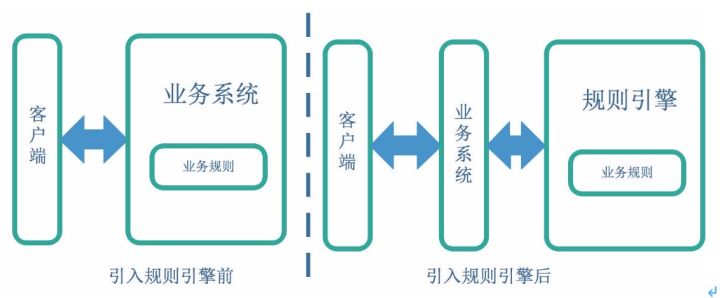
基于规则引擎的投放管控模型
一、规则引擎介绍
1. 为什么需要规则引擎
在很多企业的业务系统中,经常会有大量的业务规则配置,而且随着企业管理者的决策变 化,这些业务规则也会随之发生更改。例如,通信运营商的优惠活动:
1)用户的每月使用总额比上月提高 1 成,超出部分可以享受 6 折优惠;
2)长途话费超出 200 的,超出部分可以享受八折优惠。
如果用代码实现,if-else 可以很容易的实现上面的判断逻辑。当规则变化时我们需要修改 这个 if-else 判断逻辑。如果只是这样的逻辑改起来也简单。那么如果再添加新的规则呢?比如:
1)用户的每月使用总额比上月提高 1 成,超出部分可以享受 6 折优惠;
2)长途话费超出 200 的,超出部分享受八折优惠;
3)网费超出 200 的,市话可以享受 5 折优惠,但有一个最高上限,即最多优惠 50 元;
4)使用增值服务的用户,每月月租减少 10 元;
5)对于月消费不确定的用户可以签订保底合同,即每月必须要消费到一定的额度,如果不 足将以保底额度来进行计算,超出的费用可以给予半价优惠。
虽然规则就这五条,编程得话会有很多的 if 语句,并且有很多嵌套的 if-else 语句,而且很 难实现且难维护。当规则需要变更时,为避免牵一发动全身,需要投入很多精力对改动进行测试。
这时就需要规则引擎将规则计算逻辑和业务系统解耦。
2. 什么是规则引擎
规则引擎是一种推理引擎,它是根据已有的事实,从规则知识库中匹配规则,并处理存在 冲突的规则,执行最后筛选通过的规则。因此,规则引擎是人工智能(AI)研究领域的一部分, 具有一定的选择判断性、人工智能性和富含知识性。目前,比较流行的规则引擎有商业规则引 擎 iLog 和开源规则引擎 drools。
3. drools 规则引擎简介
Drools 具有一个易于访问企业策略、易于调整以及易于管理的开源业务 规则引擎,符合
业内标准,速度快、效率高。业务分析师或审核人员可以利用它轻松查看业务规则,从而检验 已编码的规则是否执行了所需的业务规则。其前身是
Codehaus 的一个开源项目叫 Drools,最 近被纳入 JBoss 门下,更名为 JBoss Rules,成为了 JBoss
应用服务器的规则引擎。
简而言之,drools 是一个被广泛应用的、高效的开源规则引擎。使用 drools 有一定的学习 成本,初次接触时各种名词:kie、fact、rete、Agenda、rules 等让人眼花缭乱。最常见的 drools 架构:
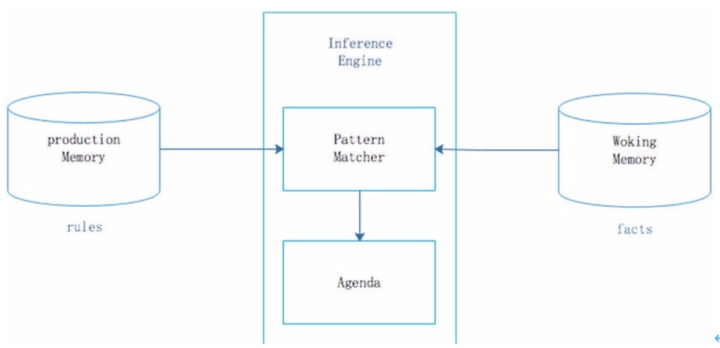
上图中,rules 即人工设置的规则文件,facts 为业务参数,inference engine 即推理引擎,即 做具体的规则匹配运算。
使用 drools 步骤:
1)准备规则文件,Drools 支持四种规则描述文件,分别是:drl 文件、xls 文件、brl 文 件和 dsl 文件,其中,常用的描述文件是 drl 文件和 xls 文件,而 xls 文件更易于维护,更直观,更为被业务人员所理解;
2)系统启动时,使用 drools 的 sdk 加载规则文件并编译成字节码。这需要我们封装 drools的 jar 包,读取规则文件并完成编译动作。编译完成后规则文件将作为字节码存储在内存中;
3)业务系统调用规则引擎进行规则匹配。调用规则引擎同样是使用 drools 的 jar 包提供的api。业务系统需要将当前场景下的业务参数传到规则引擎。
4. 优酷播放控制系统规则引擎简介
上面简述了规则引擎,以及使用广泛的 drools,此处没有做深入介绍,drools 是基于 rete算法实现的,这也是 drools 规则引擎的精髓所在,感兴趣的同学深入研究 drools 以及 rete 算法。
在优酷播放控制场景下,我们并没有使用
drools 这样的开源规则引擎,而是自研了更加轻 量级的规则引擎。这是从开发的效率,运营的灵活性,以及实际场景出发来考虑。比如一组
drools 规则是解决一个场景下的规则计算问题,比如优惠券发放,产品积分计算等,都可以根据需要
编写一组规则来实现。而对于播放控制场景,由于各个视频版权方的要求等原因,每个视频的
播放控制策略都可能不同,即对于不同的视频来说,对应的播放策略都是不一样的。这就没办 法使用确定的多组 drools 规则来 cover
所有视频的播放控制策略。
此外,播控自研规则引擎,在性能、可视化、开发运营效率方面都有很大优势。 下面会来介绍播放控制系统的规则引擎的实现思路。
二、优酷播控规则引擎技术实现
优酷播放控制系统是在点播和直播场景下对视频的投放做精细化的控制,包括在搜索、首页、频道、推荐、直播,等各个场景下,均需要依赖播放控制系统的投放许可。此外,播放控 制系统还会对版权保护做精细化控制,根据端的细分情况,对端上的 drm 版权保护(Digital Rights Management, 数字版权管理),清晰度进行控制。
1. 技术挑战
1)性能挑战
播控系统调用规则引擎的 qps 为百万级别。所以对规则引擎的性能要求很高。在计算过程 中每多产生一些负荷,就会被无限的放大。系统要求接口 rt 在毫秒级别。
2)投放的精细化控制 上文提到,优酷的各个场景都需要依赖播控的播放许可,由于版权方要求以及支持灵活的
运营策略,播放控制系统需要支持维度高达数十种,并且在不断的扩充中。这需要规则引擎支持可灵活扩展的维度支持。
2. 规则引擎技术实现
自研规则引擎只关注规则匹配运算,与业务无关。即规则引擎会返回当前的参数与策略是 否匹配,业务系统根据规则引擎返回的匹配结果来判断匹配规则后的处理逻辑。架构如下:
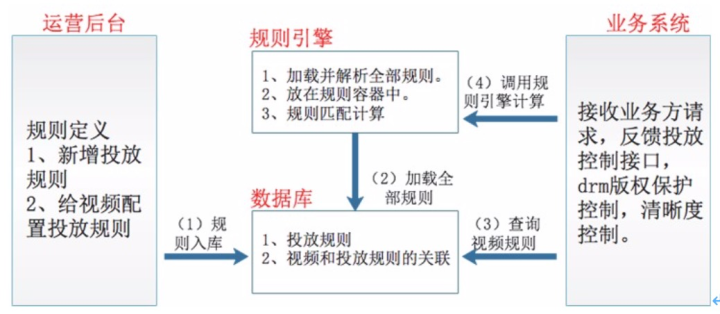
1)相对于 drools 的规则存储在规则文件中,播控自研规则引擎的规则存储在数据库中,定 义规则表用于存储于业务无关的规则。添加策略的页面示例如下图所示,将原因分类即一个规 则维度,内容分类为开一个规则维度。落库时以 key-value 的形式存储在数据库。比如下图中的 原因分类,在 db 中的 key=reasonType,value=H。

上文中提到过,每个视频的投放规则都可能不同,所以需要针对各个视频配置专属的投放 规则。即定义视频和投放规则的关联表。用于存储视频和规则的关联关系。
2)当系统启动时,规则引擎读取规则表中的全部规则,解析后存储在规则引擎持有的容器中。
3)当业务系统接收到接口请求查询投放规则时,首先会根据视频查询所属于当前视频的规则。
4)查询到所属视频的规则后,将规则 id 以及当前用户的环境参数传递给规则引擎进行规 则运算。规则引擎将计算规则是否匹配,返回结果后业务系统再封装具体的接口返回结果。
3. 规则引擎计算流程
播控规则引擎支持分层运算,即对一组规则,划分多个层次,每一层有一个优先级。这个 效果和 drools 的 salience 一样,drools 中的 salience 表示权重,权重越大优先级越高。划分好层 次之后,每一层会有多条规则,每一条规则中又包含多个维度。
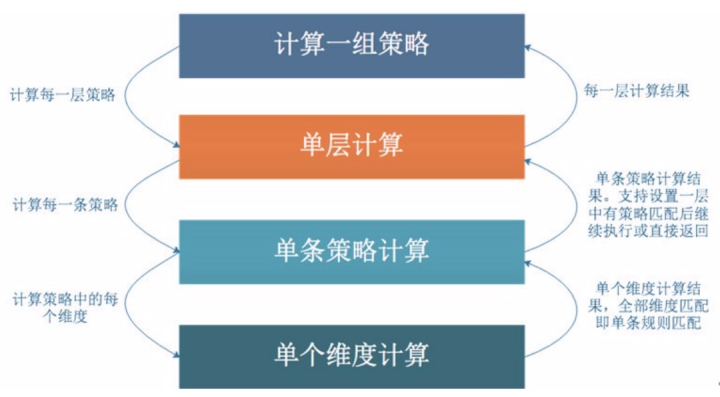
假设图 4 作为一个规则,那么在数据库中的存储为:{"reasonType":"H", "contentCategory":" 电视剧;电影;综艺;少儿"}。规则引擎解析规则后存储在规则容器中的数据结构非常简单,即 Map>。

图 5 中的单个维度计算也就变的非常的简单,假设当前业务参数 contentCategory=综艺,判 断当前维度是否匹配,只需一行代码:

4. 自研规则引擎优势
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java