
Redis 数百TB数据量的应用方案。
一、背景
携程自2013年开始使用Redis,旧时期为Memcached和Redis混用状态。由于Redis在处理性能,可储存key的多样化上有着显著的优势,2017年开始,Memcached全部下线,全公司开始大规模使用Redis。Redis实例数量也由刚开始的几十个增长到几万个,数据量达到百TB规模。作为Redis的运维方,为保证Redis的高可用性,DBA的压力也随Redis使用规模的增大而增大,集群的扩容,上下线,实例扩容都面临着不小的挑战。
携程Redis并非采用原生的cluster或者第三方开源的proxy,而是使用自主研发的CRedis Client组件,部署在所有的应用端。该方案的好处是,Redis的使用者只需要知道自己的Redis名称,就可以访问自己的Redis,而不需要关心Redis的实际部署情况。
这也意味着全部的运维操作都需要在CRedis中注册并推送到所有的客户端,为保障Redis的持续可用性,DBA的所有运维操作都是以数据的安全性为第一准则,尽可能做到扩容迁移等操作透明化,保证用户至上。
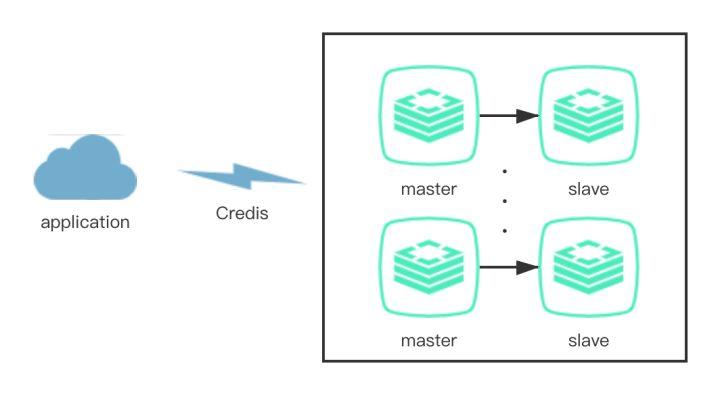 图1 CRedis架构
图1 CRedis架构
二、单机多实例时期
Redis使用早期(2016年以前),Redis服务器上线后,由DBA在物理服务器上部署多个实例,然后这些实例在CRedis中注册,提供给应用访问。资源优化和性能的平衡由DBA管理,主要是基于服务器的内存、CPU、网络带宽等指标来手动调节,和MySQL的单机多实例类似。DBA在集群上下线和部署时需要自行在pool中寻找合适的机器,当然我们也总结出了一套比较合理的优化算法和方式来管理Redis的部署。
在Redis的使用爆发增长时期(2016-2018),我们上线了一套Redis自动化治理系统RAT(Redis Administration tools)。Redis的上下线和扩容从手工时代来到了自动化部署和自动扩容时期,Redis运维管理难度,随着实例大规模增加而增加。
由于前期对Redis的申请和扩容没有做太多限制,物理服务器的使用率一直不太理想,维持在40%+左右。加上频繁扩容导致的超大实例(20GB+),稍不注意在全量同步时就容易引起实例OOM,影响业务。为了提高内存效率和降低手动操作风险,DBA迫切需要一种更先进的部署治理系统来管理Redis。
三、容器化时期
2018年开始,随着容器化的流行以及Kubernetes成为容器编排的事实标准,我们也开始逐步探索有状态应用容器化。
Redis的部署由Kubernetes根据设定的规则自动化调度部署,DBA再也不需要操心资源的问题,操作效率提高了几十倍。Redis的上线和无状态的应用一样接入到了PaaS系统中,Redis的分配也划分了多个可用域(Region),每个Region划分多个可用Pool满足相关性强的Redis集中部署。
Redis作为一种典型的有状态应用,很多的落地经验可以参考前面的文章《携程Redis容器化实践》。但在当时容器化的规模只有几千个,而目前已经增加了十倍多,还在不断增长,对于如此大规模的实例数,治理策略的调整势在必行。
3.1 二次调度
很多情况下,业务方在申请Redis时,并不特别清楚该Redis会用到多大,随着业务量的增长或调整,Redis的使用量可能会远超或远小于原始的分配额度。对于远超额度的,为避免Key剔除,以及由此带来的主从切换,影响业务的持续可用性等问题,我们会在Redis的使用率(UsedMemory/MaxMemory)达到90%的时候进行自动扩容处理(修改Redis的MaxMemory),也就是内存超分,但支持内存超分带来的负面效果也很明显:
1)Kubernetes的Request会失去它原先占位作用,因为真实的用量无法感知。
2)因为Request无法感知,所以为了防止实际的宿主机内存被打爆,我们必须限制宿主机实例的个数。
3)限制实例个数是根据每个实例分配的平均期望内存来估算,实际分配中会导致资源的利用率并不平衡。
而对于远小于原始分配额度的,缺点也很明显:
1)实例占用了大量的Request配额,而实际用的很小。
2)大量的配额无法释放,导致新的实例无法部署到某些很空的宿主机上。
3)某些很空的宿主机无法部署新实例,利用率低下。
由于Kubernetes对于这种有状态应用支持的不够完善,而我们的Redis集群又有几千台的规模,在处理这些问题时必须分而治之,各个击破。
因为迁移实例需要迁移一组,一组一般是2个或更多实例,对于运维来说是个非常重的操作,但迁移实例可以修正Request配额,让其适配UsedMemory。而漂移只需要迁移一个实例,是个相对轻量级的操作。对于Request和UsedMemory严重不匹配的(一般是2倍以上或1/3以下的关系),我们通过迁移来修正。而对于Request和UsedMemory相差不是很大的,我们必须在外围进行二次调度。
二次调度可以认为是宿主机资源Rebalance的过程,而在二次调度之前,我们必须要厘清二次调度的目标:
1)对于一个标准的宿主机,为了支持自动扩容,我们认为Request 100%,内存使用率为60%-65%为最优状态。
2)每个宿主机上内存使用率尽可能地平均,也就说方差尽可能地小。
3)Node可用内存小于35%,禁止调度,大于45%,开放调度。
对于第三点,在外围有专门的Job来检测Node的可用内存,来cordon/uncordon符合条件的Node。
对于上面第一第二点的两个目标,我们设计了支持2种模式的局部最优平衡算法:
1)预留制
由于Redis实例在使用过程中内存使用量不断增长,且增长趋势无序无规律,使得某些宿主机上的内存可用率很低(如图2所示宿主机可用率约为24%-26%)。因此,可以通过将内存不足的宿主机上的实例漂移到闲置或内存充足的宿主机上来缓解源宿主机的内存压力。
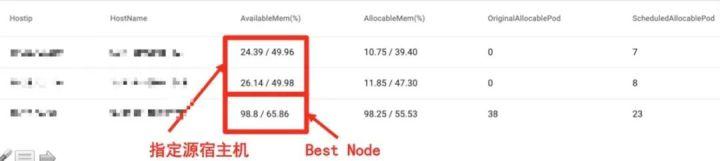 图 2 预留制算法下宿主机的二次调度情况
图 2 预留制算法下宿主机的二次调度情况
首先,通过选择需要被二次调度的源宿主机以及指定目标内存可用率(如图2为50%),预留制算法可将源宿主机上需要被调度的实例漂移到闲置宿主机上,或是调用已经实现的bestnode接口,自动为源宿主机上需要被调度的实例选择符合调度条件的目标宿主机,且二次调度后目标宿主机以及闲置宿主机的内存可用率不低于指定的目标内存可用率。
bestnode是已经实现的一种二次调度的策略,可为实例选择相同label、相同zone且可用内存、可分配内存及宿主机可容纳实例个数充足的最优目标宿主机,从而保证实例可以成功地漂移到目标宿主机上。
2)完全平衡制
由于集群中宿主机内存使用率的差距非常大(如图3所示),为了使每个宿主机上内存使用率尽可能平均,即方差尽可能小,可以通过将内存紧张的宿主机上的实例漂移到内存充足的宿主机上,从而缩小宿主机内存使用率的差距。
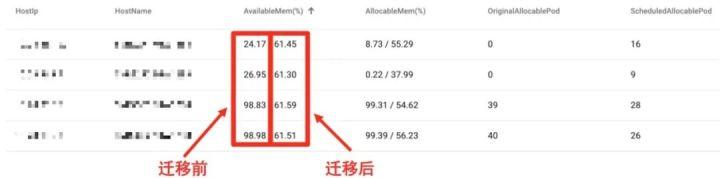 图 3 完全平衡制下宿主机的二次调度情况
图 3 完全平衡制下宿主机的二次调度情况
如图3所示,通过手动选择需要平衡的宿主机实例,完全平衡制算法将计算宿主机群内存使用率的最小方差(图3中宿主机群内存使用率达到最小方差约为61%),并在宿主机群间做实例的调度。
在实例漂移前Redis集群中还存在如图4所示的情况。由于某些宿主机上实例的UsedMemory很小,导致宿主机的内存可用率很高却由于实例个数已满无法再将实例漂移到宿主机上,使得宿主机的内存利用率不高。相反,也存在实例的UsedMemory很大导致的宿主机内存可用率低但还可将实例漂移到宿主机上的情况。
对于这种情况,我们首先将内存可用率高的宿主机上UsedMemory最小的几个实例漂移到内存使用率低的宿主机上,从而为宿主机腾出实例个数配额,接着将内存可用率低的宿主机上UsedMemory较大的几个实例漂移过来,从而平均宿主机的内存使用率。
 图 4 内存可用率高却无可分配pod的宿主机与内存可用率低有可分配pod的宿主机
图 4 内存可用率高却无可分配pod的宿主机与内存可用率低有可分配pod的宿主机
用户可配置二次调度的参数,如指定可漂移实例的Max/Min UsedMemory,Rebalance次数,最后生成一个config文件。
预留制算法与完全平衡制算法在选择源宿主机上需要被调度的实例时都使用的是First Fit Decreasing(FFD)算法,即首先计算达到目标内存可用率需从源宿主机上释放内存(ReleaseMemory)的大小,接着遍历由大到小排序后源宿主机上实例的RequestMemory以及UsedMemory,将符合条件(RequestMemory<ReleaseMemory且UsedMemory<ReleaseMemory)的实例列入候选调度名单。通过对历史迁移记录使用机器学习等方法,根据以往的迁移开销可以生成实例调度的集群画像(黑/白名单)。
在先对宿主机进行预处理后(如上图4),根据二次调度config文件,综合考虑黑白名单、实例优先级,并且排除不能被调度的实例类型(如XPipe以及多slave实例)后,即可确定最终需要被二次调度的实例名单。最后即可生成如图5所示的二次调度方案。
Redis主要瓶颈在内存,因此我们暂时也只考虑内存。但这种二次调度的模式同样可以应用于其他有状态应用的场景,如Mysql/Mongodb/Es等,只是考虑的维度更全面(Cpu/内存/磁盘)。
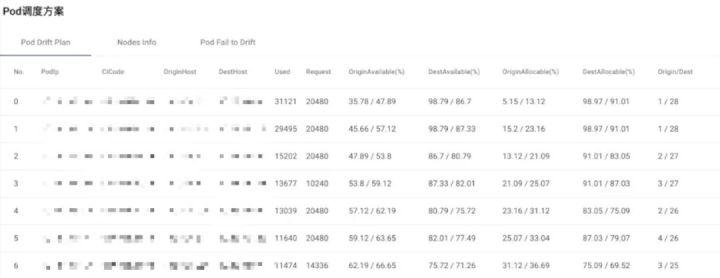 图5 实例二次调度方案
图5 实例二次调度方案
3.2 自动化漂移
有了上面的二次调度,我们可以手工或者自动生成二次调度的计划或任务,在指定时间触发,此外我们上线了容器自动化漂移系统,漂移操作支持下面几种类型:
1)指定实例漂移到指定宿主机。
2)宿主机完全down掉,无法恢复,一键漂移。
3)宿主机有故障需要维修,一键漂移。
4)二次调度计划自动或手动漂移。
根据之前的描述,我们所有的运维操作需要在CRedis中注册,我们也针对Redis实例在CRedis中的不同角色,在逻辑和物理层面进行了无缝衔接,在漂移过程中自动修改CRedis的访问策略,数据同步,Xpipe DR系统自动化注册(Xpipe是携程Redis跨IDC容灾的方案),自动添加删除哨兵等。
 图6 容器漂移拉出流程
图6 容器漂移拉出流程
3.3 Cilium
由于我们漂移过程中,整个IP是不变的,IP不变的逻辑由OVS来保证,这样好处是对客户端和中间件透明。但随着携程单个IDC内容器部署密度的越来越大,大二层网络的交换机表项无法承受这么多IP在整个IDC内可漂移。
Cilium是下一代云原生的网络解决方案,之前有其他同事的文章有所描述,这里不再展开。我们将Redis容器跑在了Cilium上,漂移过程中Redis换宿主机后IP会变,这样会涉及多个系统的数据变更,如哨兵记录了老IP,当前实例却变成新IP,这时候正好分配一个老的IP给了新的实例,导致复制关系错乱,稍有不慎便会导致生产事故。也对漂移流程的可靠性提出了更高的要求,我们细化每一步漂移流程,设计合适的状态机,保证每一步的可重试和幂等性。
3.4 傲腾落地
大规模的Redis用量以及增长速度迫切需要我们调研性价比更高的解决方案,这时候Intel傲腾技术进入了我们的视线。目前为止,傲腾宿主机大约为整个Redis宿主机的10%左右。
傲腾SSD
率先被我们引入的是傲腾SSD,通过2块SSD组合,可以提供操作系统约700多G的内存。
 图7 傲腾SSD和纯内存宿主机对比
图7 傲腾SSD和纯内存宿主机对比
从实际效果上看(图7)傲腾SSD的平均延迟相比内存还是相对明显,从0.3ms上升到了0.9ms,与测试的结果吻合,但某些业务能接受这种延迟的上升,并且能节约60%成本,因此我们首先在携程内部小范围的部署了傲腾SSD。
傲腾AEP
尽管傲腾SSD可以符合我们的部分要求,但缺点还是比较多。
1)驱动支持不完善,基本所有的厂商需要对应的RAID卡驱动,并且每家还不太一样,现实状况是需要编译多个内核版本来适配不同厂商的驱动。
2)装机繁琐,需要注册码,还要开关机多次,并且还有失败的概率,是否能最终进入系统有点凭运气。
3)700G+作为Redis宿主机来说相对太大了,因为我们需要考虑Redis宿主机万一挂了恢复的时间。
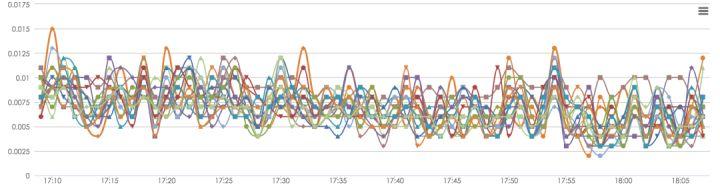 图8 傲腾AEP和纯内存宿主机对比
图8 傲腾AEP和纯内存宿主机对比
从线上结果来看,傲腾AEP和纯内存的耗时比较接近,业务的监控状态如上图。傲腾与普通物理内存实际运行区别已经非常小,可以满足绝大部分业务场景。并且相对于傲腾SSD,傲腾AEP还有以下的优点:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java