
什么是数据分析和机器学习?
数据分析和机器学习

如果你认为大数据仅仅是关于SQL语句查询和海量的数据的话,那么别人也会理解你的,但是大数据真正的目的是通过对数据的推断,从数据中获取价值、从数据中发现有用的东西。例如,“如果我降低5%的价格,我将增加10%的销售量。”
数据分析是重要的技术,包括如下方面:
· 描述性分析:确定所发生的事情。这通常涉及到描述发生了什么现象的报告。例如,用这个月的销售额与去年同期进行比较的结果。
· 特征性分析:解释现象发生的原因,这通常涉及使用带有OLAP技术的控制台用以分析和研究数据,根据数据挖掘技术来找到数据之间的相关性。
· 预测性分析:评估可能发生的事情的概率。这可能是预测性分析被用来根据你的工作性质、个人兴趣爱好,认为你是一个潜在的读者,以便能够链接到其他的人。
机器学习适合于预测性分析。
什么是机器学习
机器学习是人工智能的一个子集,即用机器去学习以前的经验。与传统的编程不同,开发人员需要预测每一个潜在的条件进行编程,一个机器学习的解决方案可以有效地基于数据来适应输出的结果。
一个机器学习的算法并没有真正地编写代码,但它建立了一个关于真实世界的计算机模型,然后通过数据训练模型。
机器学习如何工作?
垃圾邮件过滤是一个很好的例子,它利用机器学习技术来学习如何从数百万封邮件中识别垃圾邮件,其中就用到了统计学技术。
例如,如果每100个电子邮件中的85个,其中包括“便宜”和“伟哥”这两个词的邮件被认为是垃圾邮件,我们可以说有85%的概率,确定它是垃圾邮件。并通过其它几个指标(例如,从来没给你发送过邮件的人)结合起来,利用数十亿个电子邮件进行算法测试,随着训练次数不断增加来提升准确率。
事实上,谷歌表示它现在已经可以拦截99.99%左右的垃圾邮件。
机器学习实例
一般包括以下几个方面:
· 目标影响:主要针对Google和Facebook的目标广告,基于个人兴趣爱好,并通过Netflix推荐电影,还通过亚马逊推荐购物;
· 信用评分:银行使用收入数据,从你的居住地、你的年龄和婚姻状况来预测你是否会拖欠贷款;
· 信用卡欺诈检测:用于根据你之前一些可能的消费习惯,在线禁止具有欺诈行为的信用卡或借记卡的使用;
· 购物篮分析:根据数以百万个类似顾客的消费习惯,用来预测你更可能使用哪些特殊优惠政策;
在一个有争议的案例:美国零售商对使用了25种不同的健康和化妆品产品的顾客的购物篮进行分析,来成功地预测妇女怀孕,包括非常准确的预产期。然而却事与愿违,当一个年轻女孩的父亲抱怨说,在女儿被怀孕相关的特殊优惠轰炸后,目的就变成了鼓励未成年少女怀孕。
你需要什么
事实上,你是在寻找数据中的关联性,但你需要一些领域的专业知识来验证结果。计算机可以找到一个模式,但是只有专家才能验证它是否具有关联性。
总之,以下是你所需要的:
· 目标.你正在试图解决的问题。例如,信用卡被盗了吗?股票价格会上涨还是下跌?用户近期最喜欢哪部电影?
· 大量数据. 例如,为了准确预测房屋的价格,你需要详细列出的历史价格。
· 专家.你需要一个知道正确答案的领域专家来验证所产生的结果,并确认什么时候模型足够精确。
· 模式.你在寻找数据中的模式。如果没有模式,你可能会有错误的或者不完整的数据。
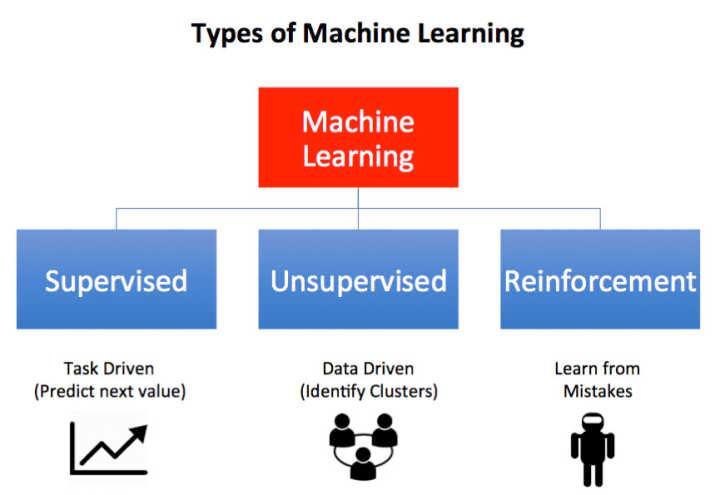
机器学习的类型
预测性分析试图基于历史数据来预测未来的结果,最常用的方法被称为监督学习。
机器学习的类型有:
· 监督学习:当我们需要从过去的数据中知道正确答案的时候,但是还需要预测未来的结果。例如,利用过去的房价来预测当前和未来的价格。有效地使用基于试错的统计改进过程,机器依靠对监督者提供的一组值的测试结果来逐步提高准确性。
· 无监督学习:这里没有明确的正确答案,但我们想从数据中有新的发现。最常用于对数据进行分类或分组,例如,在Spotify上对音乐分类,来帮助推荐你可能想听的歌曲或是专辑。然后,他们将听众分类,看他们是否更可能愿意听Radiohead或Justin Bieber。
· 强化学习:不需要一个领域专家,但需要不断地向预定目标前进。这是一种经常部署神经网络的技术,例如, AphaGo在DeepMind中跟自己打了一百万场比赛,最终成为了世界冠军。
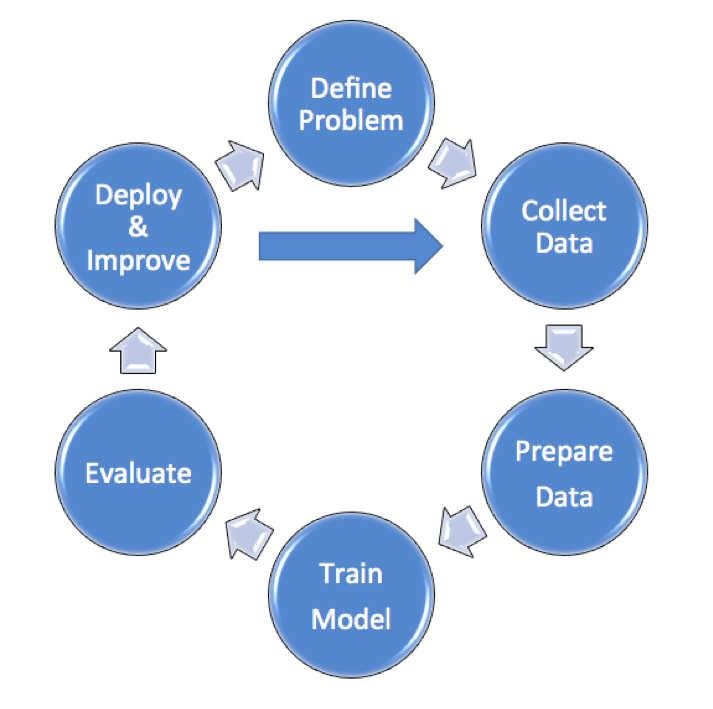
机器学习过程
不同于未来通过机器学习下象棋的场景,目前大多数机器学习是相当麻烦的,在下面的图表中进行了说明:
在未来很可能机器学习将会被应用到帮助加快过程,特别是在数据收集和清洗领域,但主要步骤仍然存在以下方面:
· 定义问题:正如我在另一篇文章中所指出的那样,机器学习总是从一个明确的问题和目标开始;
· 收集数据:适合的数据的数量和种类越多,机器学习模型就会变得越精确。这些数据可以来自电子表格、文本文件和数据库,除了商业上可用的数据源之外;
· 准备数据:这包括数据的清理和解析。删除或纠正异常值(失控的错误值);这经常占用总的时间和工作量的60%以上,然后将数据分成两个不同的部分,即训练数据和测试数据;
· 训练模型:针对一组训练数据—用于识别数据中的模式或相关性,或者用于做预测,同时使用重复的测试和误差改进方法来逐步地提高模型的精度;
· 评估模型:通过比较结果与测试数据集的准确度来评估模型。重要的是不要对用于训练系统的数据进行模型评估,以确保无偏差的和独立的测试;
· 部署和改进:这可以涉及到尝试完全不同的算法或者收集更多种类或更大数量的数据。例如,你可以通过使用房屋所有者提供的数据来预估今后的房屋升值空间,从而提高房价预测的准确度;
综上所述,大多数机器学习过程实际上是循环的和连续的,因为更多的数据被添加或者情况会有所变化,因为世界从来不会静止不动,并且总是有改进和提高的空间。
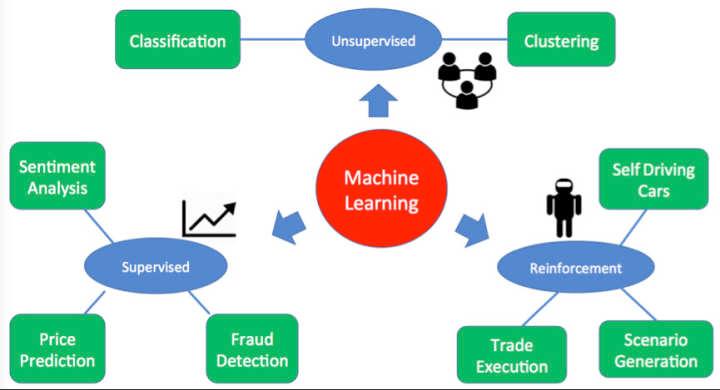
总结
下图说明了机器学习系统所使用的关键策略:
总之,任何机器学习系统的关键部分就是数据。考虑到额外的算法、巧妙的编程和大量的更精确的数据的选择,大数据每次都是胜利者。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java