
文字识别技术(OCR)架构引擎
文字识别技术- OCR
OCR技术,通俗来讲就是从图像中检测并识别字符的一种方法,在证通用文字识别、书籍电子化、自动信息采集、证照类识别等应用场景中得到了广泛应用。通用场景的OCR因此通用场景下的OCR技术一直都是人工智能领域挑战性极强的研究领域,不需要针对特殊场景进行定制,可以识别任意场景图片中的文字。
通用OCR技术包含两大关键技术:文本检测和文字识别。检测模型的作用简单来说就是确定图片中哪里有字,并把有字的区域框出来。文字识别是将文本检测box作为输入,识别出其中的字符。
近年来深度学习逐渐被应用到音频、视频以及自然语言理解等时序数据建模的领域。通过深度学习的端到端学习提升Sequence Learning的效果已经成为当前研究的热点。基本思路是CNN与RNN结合:CNN被用于提取有表征能力的图像特征,将RNN的序列化特性引入到文本检测,增加了文本检测候选区域的上下文信息,可以有效地提升文本检测任务的性能。CNN+RNN的混合网络将文本串识别领域的效果推到了一个新的高度。
 图1:CRNN网络结构
图1:CRNN网络结构
*上图引用自《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》。
我们以目前应用十分广泛的CRNN模型为例,它是DCNN和RNN的组合,可以直接从序列标签学习,不需要详细的标注;比标准DCNN模型包含的参数要少很多。同时CRNN在图像特征和识别内容序列之间严格保序,擅长识别字分割比较困难的文字序列。
架构包括三部分:
1) 卷积层,从输入图像中提取特征序列,将图像进行空间上的保序压缩,相当于沿水平方向形成若干切片,每个切片对应一个特征向量;
2) 循环层,预测每一帧的标签分布;采用双层双向的LSTM,进一步学习上下文特征,据此得到切片对应的字符类别。
3) Transcription层,利用CTC和前向后向算法求解最优的label序列。
OCR加速架构
依赖于FPGA的可编程性、高性能以及高通信带宽,我们设计了一个多FPGA芯片协同的异构加速架构。单一芯片针对一种类型的模型进行深度定制优化,不同芯片之间通过负载均衡以及流水化来完成整个混合模型的加速过程。
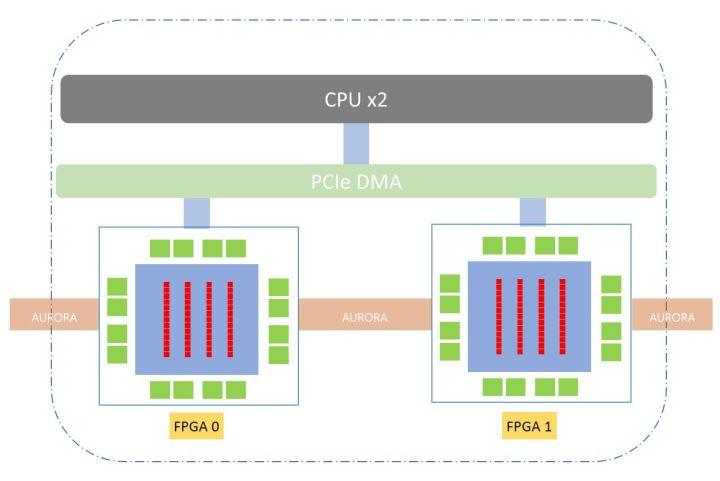 图2:OCR加速硬件架构
图2:OCR加速硬件架构
- FPGA 0配置为通用的CNN加速架构
- FPGA 1配置为通用的LSTM加速架构
- 对于计算量较小的FC使用CPU进行计算,保持模型灵活性
- FPGA与服务器CPU通过PCIe Gen3进行数据通信,负载均衡由CPU进行控制
- FPGA间通过AURORA轻量级协议进行数据交换,数据交换延时ns级,类似不同板卡间内存共享
- 平台后续升级可支持服务器间的多任务并行/流水调度
为特定的深度学习模型进行底层深度架构优化,通过架构层面上的优化来充分发挥异构加速器件的性能,达到最大的计算收益。
通用加速器引擎
针对CNN以及LSTM这两类最常用的深度学习算法,我们设计了两种加速架构;每种架构能够通过“指令集+基本算子”的形式,能够较为灵活的支持各类模型变种。
3.1 CNN计算引擎
CNN模型的核心计算是Kernel在input feature map滑窗进行3D卷积计算,Kernel数据复用率高,整体计算密度大。
CNN加速器当前版本基于Xilinx Ku115芯片设计,PE计算单元由4096个工作在500MHz的MAC dsp核心构成。KU115芯片由两个DIE对堆叠而成,加速器平行放置了两组处理单元PE。每个PE由4组32x16=512的MAC计算DSP核心组成的XBAR构成。
计算架构设计的关键在于提高数据复用率来提升DSP计算效率,实现模型权重复用和各layer feature map的复用。
其基本组织框架如下图所示:
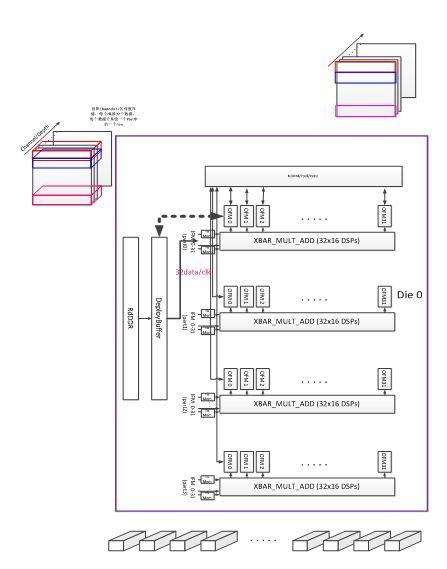 图3:CNN计算引擎架构
图3:CNN计算引擎架构
3.2 LSTM计算引擎
LSTM模型的核心是向量*矩阵及对应各gate的激活函数。权重矩阵数据量大,同时时间序列上数据存在前后依赖关系,模型中可挖掘的的计算并行度小。
LSTM加速器当前版本基于Xilinx Ku115芯片设计,PE计算单元由4096个工作在300MHz的MAC dsp核心构成。对于核心PE单元,我们将其细分为64个bank,每一个bank由64个级联的DSP组成,利用DSP特性完成向量乘法过程中的乘累加过程。
计算架构设计的关键在于降低访存消耗。在控制部分,需要控制好ROW A和Col B的数据pipeline输入,保证计算数据之间的匹配;在PE输出端需要把控好激活函数的并行性,保证模型计算流水线的高效性。
其基本组织框架如下图所示:
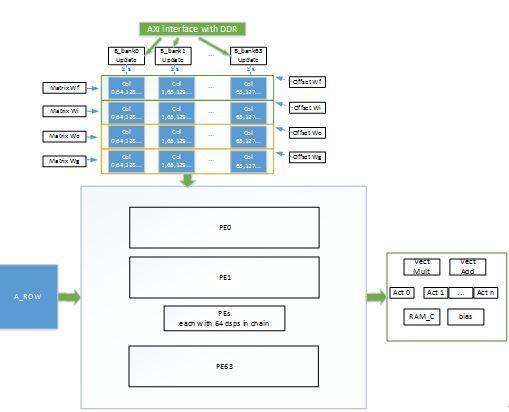 图4:LSTM计算引擎架构
图4:LSTM计算引擎架构
性能对比
对于使用者而言,FPGA平台性能、开发周期以及易用性究竟如何呢?
1.性能
CNN加速平台,峰值计算性能为4Tops,模型inference latency为GPU P4的1/10。
LSTM模型中,峰值计算性能为2.4Tops,FPGA 2us内可以完成一次核心矩阵为1024*512的计算过程(8次1*1024与1024*512向量乘矩阵及相关的激活函数)。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java