
解密消息中间件CMQ架构技术
背景介绍
可以使用消息队列的场景有很多,常见的有以下几种:
1.服务解耦:同步变异步,数据最终一致性;
2.削峰限流:类似“三峡大坝”,下游服务方被超过服务能力请求压垮;
3.广播订阅:发送方不关心谁订阅这个消息,只管发出来,拓展方便;
4.流式数据过滤:消费者通过类似SQL语句来筛选自己感兴趣的数据;
5.两阶段消息:通过两阶段消息与本地数据库事务相结合达到简单分布式事务。
中间件团队消息队列发展历程:

CMQ/CKafka/MQ for IoT本质上都属于分布式消息中间件,分布式消息系统的最大特点是可扩展性。核心理念是多个节点协同工作完成单个节点无法完成的任务,不允许出现单节点故障服务不可用(RTO)和数据丢失(RPO)情况。归根结底是解决CAP问题, CMQ作为金融级别服务要求数据高可靠强一致(CP), CKafka以大数据领域为主要服务对象,更偏重于AP,同时允许用户通过配置在CAP之间进行权衡,本文重点对CMQ进行介绍
核心原理介绍
整体架构介绍
 架构图
架构图
CMQ属于典型的三层架构,支持业界主流协议,业务可以选择HTTP/AMQP/MQTT等多种协议,适配层主要负责协议适配和路由控制,同时支撑系统水平弹性伸缩,后端Broker Set 提供消息持久化存储、转发以及基于消息的高阶功能,例如延时消息、事务消息、死信消息等;控制Server和管控平台负责对整个系统进行智能调度、故障处理、运营监控。
弹性伸缩:
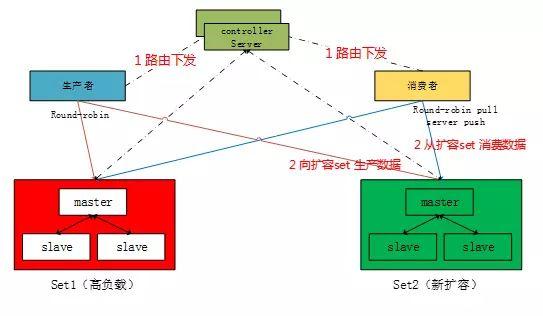
分布式消息队列性能和消息堆积存储量理论上无上限,CMQ的路由控制Server 会根据存储Set的实际负载调整消息收发路由信息并同时适配层,适配层根据收到的路由指令调整数据最终流向后端那个Set,整个过程对使用者是透明的。
数据高可靠强一致:
CMQ 利用数据多副本存储来保证可靠性,通过Raft算法来保证副本间的数据强一致,数据生产过程大致如下:
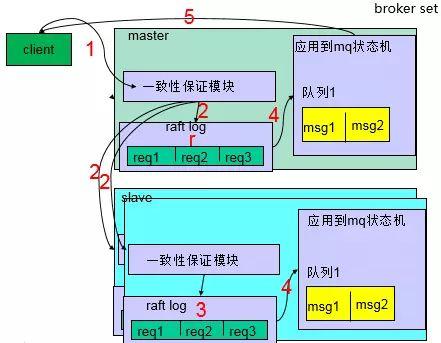
以一个存储Set中3个节点为例,其中只有一个Master节点可以对外接收生产数据,另外两个节点作为Slave存在,同时Slave 会将收到的请求重定向到Master,详细过程如下:
1.Master 负责消息的生产消费请求,收到请求后先通过Raft一致性模块写Raft log到本地并同步给所有Slave节点;
2.Slave 收到Master发来的Raft log持久化到本地同时返回Master 成功信息;
3.Master 收到Set中过半节点的成功信息后将请求信息提交到mq 状态机;
4.Mq 状态机处理请求信息后返回用户成功;
可以看到对于生产数据CMQ会通过Raft算法确保Set中超过半数的节点已经完成存储持久化后才返回给用户发送成功,同时Raft 算法的选举原理保证数据对用户可见的强一致性,具体Raft算法不在此展开。
通过上述过程我们可以发现两个问题:
1.上述整个流程是串行的,Raft组内顺序执行上述流程,不能充分发挥节点性能;
2.相对Master节点,Slave做的事情更少,节点平时存在严重浪费;
为了提升QPS和机器利用率CMQ通过Multi-Raft将Set中的3个节点充分利用起来,多组Raft之前相互独立,Master 尽量打散分布在不同节点上。
在研发CMQ过程中,我们将其中使用到的Raft 算法进行抽象,沉淀成可独立使用的Raft算法库,目前已经在部门内部多个产品中使用,逐步完善后会进一步对外开源。
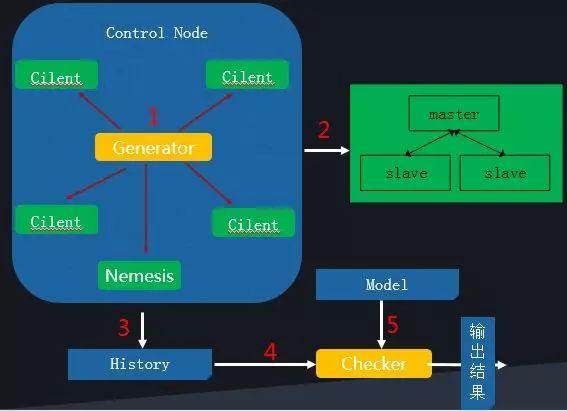
上面从设计与开发角度介绍了CMQ一致性原理,但是如何验证开发出来的CMQ是符合线性一致性的呢?为此我们参考业界知名的分布式系统完备性工具jepsen设计开发了自己的验证系统,原理如下:
1.部署要测试的集群;
2.ControlNode执行测试程序
- 启动集群
- 生产执行序列
- 5个client线程并发运行执行序列,同时通过Nemesis线程进行错误及异常注入测试,6个线程将执行过程log 记录到history。
3. Module是根据系统行为提前定义好的正确性验证模型,Checker结合Module分析history输出测试报告。
高性能优化:
Raft 算法中存在以下两个比较耗时的操作:
1.Master每收到一个请求都向所有Slave各发起一次网络IO, Slave处理成功后回复Master成功。
2.Master 和Slave 还需要对收到的请求同步刷盘
对上述两个步骤进行分解:

3.fsync_raft_log时间取决于磁盘性能,raft_log网络传输时间取决于网络RTT。由此可见这两个值是硬件相关的,因此我们在消息个数、时间两个维度来尽可能合并消息,做到批量发送raft_log 和批量刷盘来提高QPS。
可用性保证:
CMQ具备节点、Set、园区三级高可用保障机制,业务可根据实际需求来按需选择。
节点可用性:
如果Set中的单个Slave 发生故障,由于此时Set满足大多数节点可用,得益于Raft算法使得故障对业务是完全透明的;如果是Master 发生故障,此时Raft 算法会自动发起选举,符合条件的Slave 自动提升为Master, 整个过程是秒级别的,由于存在重试逻辑,所以绝大部分情况下对业务影响也是透明的。
Set 级别可用性:
很不幸,假设一个Set中的3个节点中的两个节点同时发生了故障,此时按照Raft算法要求的大多数节点都同意才能提交请求到MQ状态机的原则,当前Set 是不可用的。此时CMQ通过双Set来保障可用性,大致原理如下:
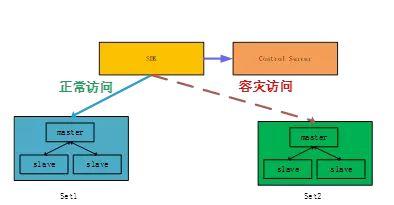
业务在申请使用消息队列时CMQ会在两个Set上分别建立队列元数据,正常情况下只有一个Set 对外服务,另外一个Set standby;当一个Set 不可用时间超过一定时间,消息流会自动切换到之前Standby的Set上。为了提高Set使用率,Standby 队列并没有独占Set,而是分布在不同的Set 之上。对于存留在故障Set上的还未来得及消费的数据需要故障恢复后才能正常消费。
数据中心级别可用性:
金融业务在应用层都有多中心多活的要求,防止数据中心故障后导致整个服务不可用。CMQ通过插件的方式对两个数据中心的消息服务进行异步同步。当一个数据中心故障时任然存在少量未来的及同步的数据丢失的情况,此时需要通过log 或者对账来恢复数据。
消息Log Trace
消息中间件日常运营中最常见的一个问题是如何证明系统没有丢消息?为此CMQ提供了一套消息trace 系统。Agent 将每条消息的ID、生产者、消费者信息都上报到log 存储系统,业务对于有疑问的消息可以在控制台上直接查询,就能看到消息的整个流转消费情况。

开源竞品对比
业界高可靠消息中间件主要以RabbitMQ为主,下面对CMQ和RabbitMQ进行分析对比。
RabbitMQ 集群镜像模式节点间采用自研的可靠多播(Guaranteed Multicast)算法来同步数据,GM可靠多播将集群中所有节点组成一个环。Log 复制依次从 Master 向后继节点传播,当 Master 再次收到该请求时,发出确认消息在环中传播,直至 Master再次收到该确认消息,表明Log 在环中所有节点同步完成。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java