
搜索引擎查询检索整体过程
1. 前言
Query理解(QU,Query Understanding),简单来说就是从词法、句法、语义三个层面对query进行结构化解析。这里query从广义上来说涉及的任务比较多,最常见的就是我们在搜索系统中输入的查询词,也可以是FAQ问答或阅读理解中的问句,又或者可以是人机对话中用户的聊天输入。本文主要介绍在搜索中的query理解,会相对系统性地介绍query理解中各个重要模块以及它们之间如何work起来共同为搜索召回及排序模块服务,同时简单总结个人目前了解到业界在各个模块中的一些实现方法。
2. 相关概念
2.1 NLP
自然语言处理(NLP,Natural Language Processing)是集语言学、统计学、计算机科学,人工智能等学科于一体的交叉领域,目标是让计算机能在处理理解人类自然语言的基础上进一步执行结构化输出或语言生成等其他任务,其涉及的基础技术主要有:词法分析、句法分析、语义分析、语用分析、生成模型等。诸如语音识别、机器翻译、QA问答、对话机器人、阅读理解、文本分类聚类等任务都属于NLP的范畴。
这些任务从变换方向上来看,主要可以分为自然语言理解(NLU,Natural Language Understanding)和自然语言生成(NLG,Natural Language Generation)两个方面,其中NLU是指对自然语言进行理解并输出结构化语义信息,而NLG则是多模态内容(图像、语音、视频、结构/半结构/非结构化文本)之间的相互生成转换。
一些任务同时涵盖NLU和NLG,比如对话机器人任务需要在理解用户的对话内容(NLU范畴)基础上进行对话内容生成(NLG范畴),同时为进行多轮对话理解及与用户交互提示这些还需要有对话管理模块(DM,Dialogue Management)等进行协调作出对话控制。本文要介绍的搜索query理解大部分模块属于NLU范畴,而像query改写模块等也会涉及到一些NLG方法。
2.2 搜索引擎
在介绍搜索query理解之前,先简单介绍下搜索引擎相关知识。除了传统的通用搜索Google、Baidu、Bing这些,大部分互联网垂直产品如电商、音乐、应用市场、短视频等也都需要搜索功能来满足用户的需求查询,相较于推荐系统的被动式需求满足,用户在使用搜索时会通过组织query来主动表达诉求,为此用户的搜索意图相对比较明确。但即便意图相对明确,要做好搜索引擎也是很有挑战的,需要考虑的点及涉及的技术无论在深度还是广度上都有一定难度。
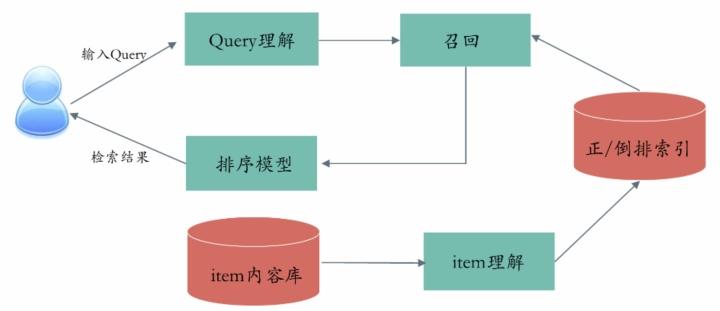
一个基本的搜索系统大体可以分为离线挖掘和在线检索两部分,其中包含的重要模块主要有:Item内容理解、Query理解、检索召回、排序模块等。整个检索系统的目标可以抽象为给定query,检索出最能满足用户需求的item,也即检索出概率: 最大的item
根据贝叶斯公式展开:

其中表示item的重要程度,对应item理解侧的权威度、质量度等挖掘,表示item 能满足用户搜索需求的程度,对query分词后可以表示为:

这部分概率对应到基于query理解和item理解的结果上进行query和item间相关性计算,同时涉及到点击调权等排序模块。
2.2.1 离线挖掘
在离线侧,我们需要做一些基础的离线挖掘工作,包括item内容的获取、清洗解析、item内容理解(语义tag、权威度计算、时间因子、质量度等)、用户画像构建、query离线策略挖掘、以及从搜索推荐日志中挖掘item之间的语义关联关系、构建排序模型样本及特征工程等。进行item内容理解之后,对相应的结构化内容执行建库操作,分别构建正排和倒排索引库。其中,正排索引简单理解起来就是根据itemid能找到item的各个基本属性及term相关(term及其在item中出现的频次、位置等信息)的详细结构化数据。
相反地,倒排索引就是能根据分词term来找到包含该term的item列表及term在对应item中词频、位置等信息。通常会对某个item的title、keyword、anchor、content等不同属性域分别构建倒排索引,同时一般会根据item资源的权威度、质量度等纵向构建分级索引库,首先从高质量库中进行检索优先保证优质资源能被检索出来,如果高质量检索结果不够再从低质量库中进行检索。为了兼顾索引更新时效性和检索效率,一般会对索引库进行横向分布式部署,且索引库的构建一般分为全量构建和增量更新。常见的能用于快速构建索引的工具框架有Lucene全文检索引擎以及基于Lucene的Solr、ES(Elastic Search)等。
除了基本的文本匹配召回,还需要通过构建query意图tag召回或进行语义匹配召回等多路召回来提升搜索语义相关性以及保证召回的多样性。
2.2.2 在线检索
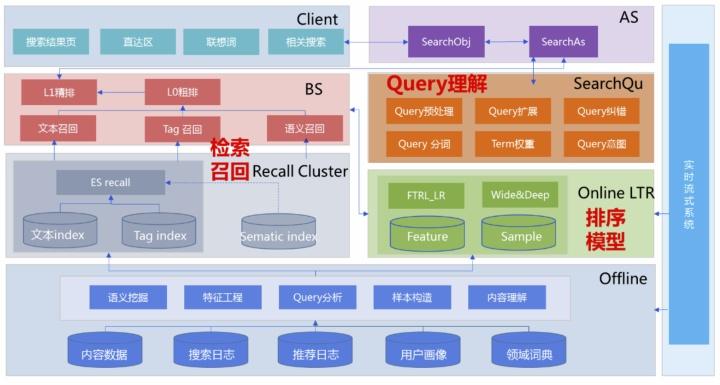
线上执行检索时大体可以分为基础检索(BS)和高级检索(AS)两个过程,其中BS更注重term级别的文本相关性匹配及粗排,AS则更注重从整体上把控语义相关性及进行精排等处理。以下面这个框图为例,介绍下一个相对简单的在线检索过程。对于从client发起的线上搜索请求,会由接入层传入SearchObj(主要负责一些业务逻辑的处理),再由SearchObj传给SearchAS(负责协调调用qu、召回和排序等模块),SearchAS首先会去请求SearchQU服务(负责搜索query理解)获取对query理解后的结构化数据,然后将这些结构化数据传给基础召回模块BS,BS根据切词粒度由粗到细对底层索引库进行一次或多次检索,执行多个索引队列的求交求并拉链等操作返回结果。
同时BS还需要对文本、意图tag、语义召回等不同路召回队列根据各路召回特点采用多个相关性度量(如:BM25文本相似度、tag相似度、语义相关度、pagerank权威度、点击调权等)进行L0粗排截断以保证相关性,然后再将截断后的多路召回进行更精细的L1相关性融合排序,更复杂一些的搜索可能会有L0到LN多层排序,每层排序的侧重点有所不同,越高层次item数变得越少,相应的排序方法也会更复杂。
BS将经过相关性排序的结果返回给SearchAS,SearchAS接着调用SearchRank服务进行ctr/cvr预估以对BS返回的结果列表进行L2重排序,并从正排索引及摘要库等获取相应item详情信息进一步返回给SearchObj服务,与此同时SearchObj服务可以异步去请求广告服务拉取这个query对应的广告召回队列及竞价相关信息,然后就可以对广告或非广告item内容进行以效果(pctr、pcvr、pcpm)为导向的排序从而确定各个item内容的最终展示位置。
最后在业务层一般还会支持干预逻辑以及一些规则策略来实现各种业务需求。在实际设计搜索实验系统时一般会对这些负责不同功能的模块进行分层管理,以上面介绍的简单检索流程为例主要包括索引召回层、L0排序截断层、L1相关性融合排序层、L2效果排序层、SearchAS层、业务层等,各层流量相互正交互不影响,可以方便在不同层进行独立的abtest实验。
当然,具体实现搜索系统远比上面介绍的流程更为复杂,涉及的模块及模块间的交互会更多,比如当用户搜索query没有符合需求的结果时需要做相关搜索query推荐以进行用户引导、检索无结果时可以根据用户的画像或搜索历史做无结果个性化推荐等,同时和推荐系统一样,搜索周边涉及的系统服务也比较庞杂,如涉及日志上报回流、实时计算能力、离/在线存储系统、abtest实验平台、报表分析平台、任务调度平台、机器学习平台、模型管理平台、业务管理后台等,只有这些平台能work起来,整个搜索系统才能正常运转起来。
2.2.3 多模语义搜索
随着资源越来越丰富,如何让用户从海量的信息及服务资源中能既准确又快速地找到诉求变得越来越重要,如2009年百度提出的框计算概念目标就是为了能更快更准地满足用户需求。同时,随着移动互联网的到来,用户的输入方式越来越多样,除了基本的文本输入检索,实现通过语音、图片、视频等内容载体进行检索的多模态搜索也变得越来越有必要。由于用户需求的多样或知识背景不同导致需求表达的千差万别,要做到极致的搜索体验需要漫长的优化过程,毕竟目前真正的语义搜索还远未到来。
3.Query理解
从前面的介绍可以知道,搜索三大模块的大致调用顺序是从query理解到检索召回再到排序,作为搜索系统的第一道环节,query理解的结果除了可以用于召回也可以给排序模块提供必要的基础特征,为此qu很大程度影响召回和排序的质量,对query是进行简单字面上的理解还是可以理解其潜在的真实需求很大程度决定着一个搜索系统的智能程度。目前业界的搜索QU处理流程还是以pipeline的方式为主,也即拆分成多个模块分别负责相应的功能实现,pipeline的处理流程可控性比较强,但存在缺点就是其中一个模块不work或准确率不够会对全局理解有较大影响。为此,直接进行query-item端到端地理解如深度语义匹配模型等也是一个值得尝试的方向。
3.1 Pipeline流程
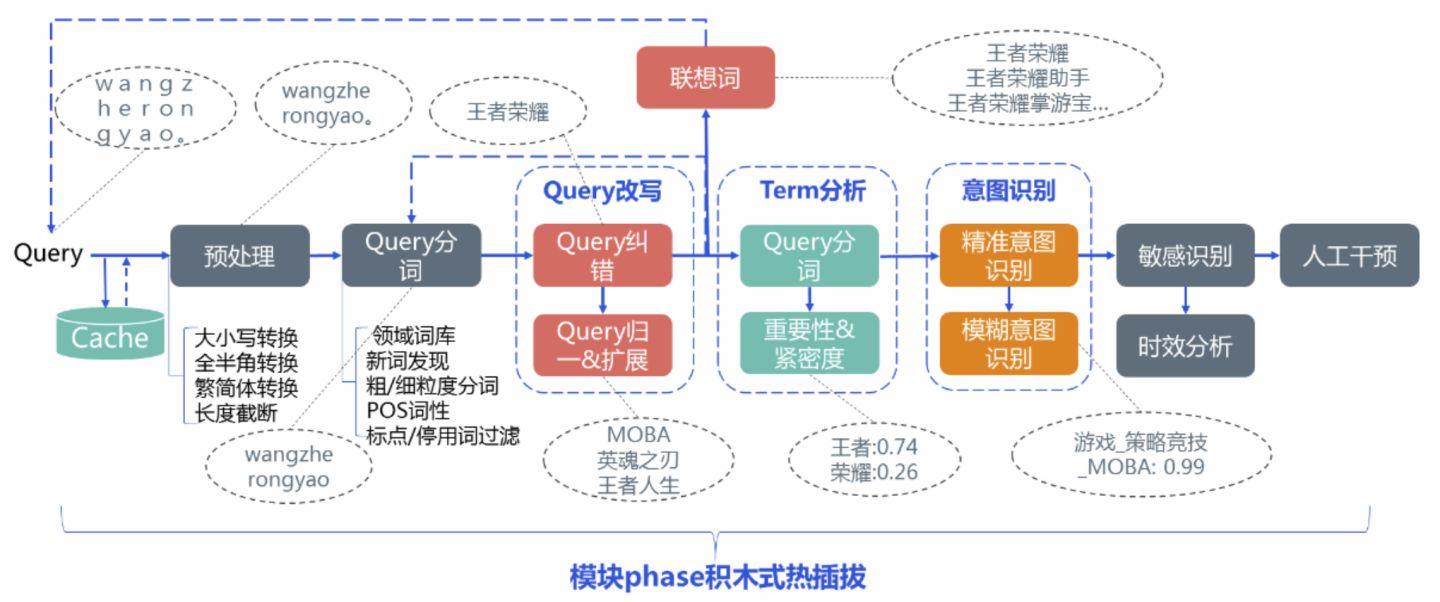
搜索Query理解包含的模块主要有:query预处理、query纠错、query扩展、query归一、联想词、query分词、意图识别、term重要性分析、敏感query识别、时效性识别等。以下图为例,这里简单介绍下query理解的pipeline处理流程:线上来一个请求query,为缓解后端压力首先会判断该query是否命中cache,若命中则直接返回对该query对应的结构化数据。若不命中cache,则首先会对query进行一些简单的预处理,接着由于query纠错可能会用到分词term信息进行错误检测等先进行query分词并移除一些噪音符号,然后进行query纠错处理,一些情况下局部纠错可能会影响到上下文搭配的全局合理性,为此还可能会需要进行二次纠错处理。
对query纠错完后可以做query归一、扩展及联想词用于进行扩召回及帮助用户做搜索引导。接着再对query做分词及对分词后的term做重要性分析及紧密度分析,对无关紧要的词可以做丢词等处理,有了分词term及对应的权重、紧密度信息后可以用于进行精准和模糊意图的识别。除了这些基本模块,有些搜索场景还需要有对query进行敏感识别及时效性分析等其他处理模块。最后还需要能在cms端进行配置的人工干预模块,对前面各个模块处理的结果能进行干预以快速响应badcase处理。
当然,这个pipeline不是通用的,不同的搜索业务可能需要结合自身情况做pipeline的调整定制,像百度这些搜索引擎会有更为复杂的query理解pipeline,各个模块间的依赖交互也更为复杂,所以整个qu服务最好能灵活支持各个模块的动态热插拔,像组装乐高积木一样进行所需模块的灵活配置,下面对各个模块做进一步详细的介绍。
3.2 Query预处理
Query预处理这个模块相对来说比较简单,主要对query进行以下预处理从而方便其他模块进行分析:
- 全半角转换:将在输入法全角模式下输入的query转换为半角模式的,主要对英文、数字、标点符号有影响,如将“wechat123”全角输入转成半角模式下的“wechat 123”。
- 大小写转换:统一将大写形式的字母转成小写形式的。
- 繁简体转换:将繁体输入转成简体的形式,当然考虑到用户群体的差异以及可能存在繁体形式的资源,有些情况还需要保留转换前的繁体输入用于召回。
- 无意义符号移除:移除诸如火星文符号、emoji表情符号等特殊符号内容。
- Query截断:对于超过一定长度的query进行截断处理。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java