
Flink 1.11.0 新版本发布及新特性解读
7 月 7 日,Flink 1.11.0 正式发布。历时近 4 个月,Flink 在生态、易用性、生产可用性、稳定性等方面都进行了增强和改善。Apache Flink PMC、阿里巴巴高级技术专家王治江,同时也是这个版本的 release manager 之一,将和大家一一分享,并深度剖析 Flink 1.11.0 带来了哪些让大家期待已久的特性,对一些有代表性的 feature 从不同维度解读。
Flink 1.11.0 从 3 月初的功能规划到 7 月初的正式发布,历经了差不多 4 个月的时间,对 Flink 的生态、易用性、生产可用性、稳定性等方面都进行了增强和改善,下面将一一跟大家分享。
一 综述
Flink 1.11.0 从 feature 冻结后发布了 4 次 candidate 才最终通过。经统计,一共有 236 个贡献者参与了这次版本开发,解决了 1474 个 jira 问题,涉及 30 多个 FLIP,提交了 2325 个 commit。
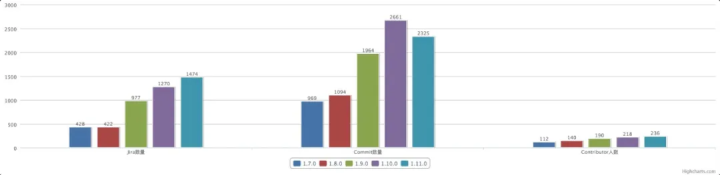
纵观近五次版本发布,可以看出从 1.9.0 开始 Flink 进入了一个快速发展阶段,各个维度指标相比之前都有了几乎翻倍的提高。也是从 1.9.0 开始阿里巴巴内部的 Blink 项目开始被开源 Flink 整合,到 1.10.0 经过两个大版本已经全部整合完毕,对 Flink 从生态建设、功能性、性能和生产稳定性上都有了大幅的增强。
Flink 1.11.0 版本的最初定位是重点解决易用性问题,提升用户业务的生产使用体验,整体上不做大的架构调整和功能开发,倾向于快速迭代的小版本开发。但是从上面统计的各个指标来看,所谓的“小版本”在各个维度的数据也丝毫不逊色于前两个大版本,解决问题的数量和参与的贡献者人数也在持续增加,其中来自中国的贡献者比例达到 62%。
下面我们会深度剖析 Flink 1.11.0 带来了哪些让大家期待已久的特性,从用户直接使用的 API 层一直到执行引擎层,我们都会选择一些有代表性的 feature 从不同维度解读,更完整的 feature 列表请大家关注发布的 release blog。
二 生态完善和易用性提升
这两个维度在某种程度上是相辅相成的,很难严格区分开,生态兼容上的缺失常常造成使用上的不便,提升易用性的过程往往也是不断完善相关生态的过程。在这方面用户感知最明显的应该就是 Table & SQL API 层面的使用。
1 Table & SQL 支持 Change Data Capture(CDC)
CDC 被广泛使用在复制数据、更新缓存、微服务间同步数据、审计日志等场景,很多公司都在使用开源的 CDC 工具,如 MySQL CDC。通过 Flink 支持在 Table & SQL 中接入和解析 CDC 是一个强需求,在过往的很多讨论中都被提及过,可以帮助用户以实时的方式处理 changelog 流,进一步扩展 Flink 的应用场景,例如把 MySQL 中的数据同步到 PG 或 ElasticSearch 中,低延时的 temporal join 一个 changelog 等。
除了考虑到上面的真实需求,Flink 中定义的“Dynamic Table”概念在流上有两种模型:append 模式和 update 模式。通过 append 模式把流转化为“Dynamic Table”在之前的版本中已经支持,因此在 1.11.0 中进一步支持 update 模式也从概念层面完整的实现了“Dynamic Table”。
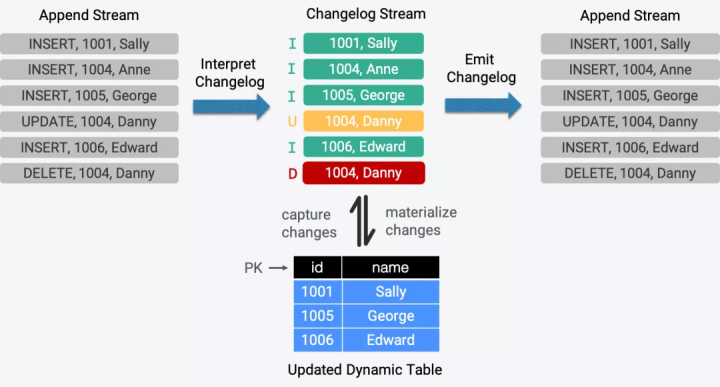
为了支持解析和输出 changelog,如何在外部系统和 Flink 系统之间编解码这些更新操作是首要解决的问题。考虑到 source 和 sink 是衔接外部系统的一个桥梁,因此 FLIP-95 在定义全新的 Table source 和 Table sink 接口时解决了这个问题。
在公开的 CDC 调研报告中,Debezium 和 Canal 是用户中最流行使用的 CDC 工具,这两种工具用来同步 changelog 到其它的系统中,如消息队列。据此,FLIP-105 首先支持了 Debezium 和 Canal 这两种格式,而且 Kafka source 也已经可以支持解析上述格式并输出更新事件,在后续的版本中会进一步支持 Avro(Debezium) 和 Protobuf(Canal)。
CREATE TABLE my_table (
...) WITH (
'connector'='...', -- e.g. 'kafka'
'format'='debezium-json',
'debezium-json.schema-include'='true' -- default: false (Debezium can be configured to include or exclude the message schema)
'debezium-json.ignore-parse-errors'='true' -- default: false
);2 Table & SQL 支持 JDBC Catalog
1.11.0 之前,用户如果依赖 Flink 的 source/sink 读写关系型数据库或读取 changelog 时,必须要手动创建对应的 schema。而且当数据库中的 schema 发生变化时,也需要手动更新对应的 Flink 作业以保持一致和类型匹配,任何不匹配都会造成运行时报错使作业失败。用户经常抱怨这个看似冗余且繁琐的流程,体验极差。
实际上对于任何和 Flink 连接的外部系统都可能有类似的上述问题,在 1.11.0 中重点解决了和关系型数据库对接的这个问题。FLIP-93 提供了 JDBC catalog 的基础接口以及 Postgres catalog 的实现,这样方便后续实现与其它类型的关系型数据库的对接。
1.11.0 版本后,用户使用 Flink SQL 时可以自动获取表的 schema 而不再需要输入 DDL。除此之外,任何 schema 不匹配的错误都会在编译阶段提前进行检查报错,避免了之前运行时报错造成的作业失败。这是提升易用性和用户体验的一个典型例子。
3 Hive 实时数仓
从 1.9.0 版本开始 Flink 从生态角度致力于集成 Hive,目标打造批流一体的 Hive 数仓。经过前两个版本的迭代,已经达到了 batch 兼容且生产可用,在 TPC-DS 10T benchmark 下性能达到 Hive 3.0 的 7 倍以上。
1.11.0 在 Hive 生态中重点实现了实时数仓方案,改善了端到端流式 ETL 的用户体验,达到了批流一体 Hive 数仓的目标。同时在兼容性、性能、易用性方面也进一步进行了加强。
在实时数仓的解决方案中,凭借 Flink 的流式处理优势做到实时读写 Hive:
- Hive 写入:FLIP-115 完善扩展了 FileSystem connector 的基础能力和实现,Table/SQL 层的 sink 可以支持各种格式(CSV、Json、Avro、Parquet、ORC),而且支持 Hive table 的所有格式。
- Partition 支持:数据导入 Hive 引入 partition 提交机制来控制可见性,通过sink.partition-commit.trigger 控制 partition 提交的时机,通过 sink.partition-commit.policy.kind 选择提交策略,支持 SUCCESS 文件和 metastore 提交。
- Hive 读取:实时化的流式读取 Hive,通过监控 partition 生成增量读取新 partition,或者监控文件夹内新文件生成来增量读取新文件。
在 Hive 可用性方面的提升:
- FLIP-123 通过 Hive Dialect 为用户提供语法兼容,这样用户无需在 Flink 和 Hive 的 CLI 之间切换,可以直接迁移 Hive 脚本到 Flink 中执行。
- 提供 Hive 相关依赖的内置支持,避免用户自己下载所需的相关依赖。现在只需要单独下载一个包,配置 HADOOP_CLASSPATH 就可以运行。
- 在 Hive 性能方面,1.10.0 中已经支持了 ORC(Hive 2+)的向量化读取,1.11.0 中我们补全了所有版本的 Parquet 和 ORC 向量化支持来提升性能。
3 全新 Source API
前面也提到过,source 和 sink 是 Flink 对接外部系统的一个桥梁,对于完善生态、可用性及端到端的用户体验是很重要的环节。社区早在一年前就已经规划了 source 端的彻底重构,从 FLIP-27 的 ID 就可以看出是很早的一个 feature。但是由于涉及到很多复杂的内部机制和考虑到各种 source connector 的实现,设计上需要考虑的很全面。从 1.10.0 就开始做 POC 的实现,最终赶上了 1.11.0 版本的发布。
先简要回顾下 source 之前的主要问题:
- 对用户而言,在 Flink 中改造已有的 source 或者重新实现一个生产级的 source connector 不是一件容易的事情,具体体现在没有公共的代码可以复用,而且需要理解很多 Flink 内部细节以及实现具体的 event time 分配、watermark 产出、idleness 监测、线程模型等。
- 批和流的场景需要实现不同的 source。
- partitions/splits/shards 概念在接口中没有显式表达,比如 split 的发现逻辑和数据消费都耦合在 source function 的实现中,这样在实现 Kafka 或 Kinesis 类型的 source 时增加了复杂性。
- 在 runtime 执行层,checkpoint 锁被 source function 抢占会带来一系列问题,框架很难进行优化。
FLIP-27 在设计时充分考虑了上述的痛点:
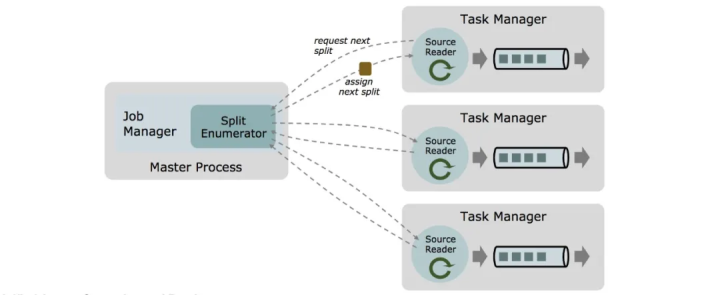
- 首先在 Job Manager 和 Task Manager 中分别引入两种不同的组件 Split Enumerator 和 Source reader,解耦 split 发现和对应的消费处理,同时方便随意组合不同的策略。比如现有的 Kafka connector 中有多种不同的 partition 发现策略和实现耦合在一起,在新的架构下,我们只需要实现一种 source reader,就可以适配多种 split enumerator 的实现来对应不同的 partition 发现策略。
- 在新架构下实现的 source connector 可以做到批流统一,唯一的小区别是对批场景的有限输入,split enumerator 会产出固定数量的 split 集合并且每个 split 都是有限数据集;对于流场景的无限输入,split enumerator 要么产出无限多的 split 或者 split 自身是无限数据集。
- 复杂的 timestamp assigner 以及 watermark generator 透明的内置在 source reader 模块内运行,对用户来说是无感知的。这样用户如果想实现新的 source connector,一般不再需要重复实现这部分功能。
目前 Flink 已有的 source connector 会在后续的版本中基于新架构来重新实现,legacy source 也会继续维护几个版本保持兼容性,用户也可以按照 release 文档中的说明来尝试体验新 source 的开发。
4 PyFlink 生态
众所周知,Python 语言在机器学习和数据分析领域有着广泛的使用。Flink 从 1.9.0 版本开始发力兼容 Python 生态,Python 和 Flink 合力为 PyFlink,把 Flink 的实时分布式处理能力输出给 Python 用户。前两个版本 PyFlink 已经支持了 Python Table API 和 UDF,在 1.11.0 中扩大对 Python 生态库 Pandas 的支持以及和 SQL DDL/Client 的集成,同时 Python UDF 性能有了极大的提升。
具体来说,之前普通的 Python UDF 每次调用只能处理一条数据,而且在 Java 端和 Python 端都需要序列化/反序列化,开销很大。1.11.0 中 Flink 支持在 Table & SQL 作业中自定义和使用向量化 Python UDF,用户只需要在 UDF 修饰中额外增加一个参数 udf_type=“pandas” 即可。这样带来的好处是:
- 每次调用可以处理 N 条数据。
- 数据格式基于 Apache Arrow,大大降低了 Java、Python 进程之间的序列化/反序列化开销。
- 方便 Python 用户基于 Numpy 和 Pandas 等数据分析领域常用的 Python 库,开发高性能的 Python UDF。
除此之外,1.11.0 中 PyFlink 还支持:
- PyFlink table 和 Pandas DataFrame 之间无缝切换(FLIP-120),增强 Pandas 生态的易用性和兼容性。
- Table & SQL 中可以定义和使用 Python UDTF(FLINK-14500),不再必需 Java/Scala UDTF。
- Cython 优化 Python UDF 的性能(FLIP-121),对比 1.10.0 可以提升 30 倍。
- Python UDF 中用户自定义 metric(FLIP-112),方便监控和调试 UDF 的执行。
上述解读的都是侧重 API 层面,用户开发作业可以直接感知到的易用性的提升。下面我们看看执行引擎层在 1.11.0 中都有哪些值得关注的变化。
三 生产可用性和稳定性提升
1 支持 application 模式和 Kubernetes 增强
1.11.0 版本前,Flink 主要支持如下两种模式运行:
- Session 模式:提前启动一个集群,所有作业都共享这个集群的资源运行。优势是避免每个作业单独启动集群带来的额外开销,缺点是隔离性稍差。如果一个作业把某个 Task Manager(TM)容器搞挂,会导致这个容器内的所有作业都跟着重启。虽然每个作业有自己独立的 Job Manager(JM)来管理,但是这些 JM 都运行在一个进程中,容易带来负载上的瓶颈。
- Per-job 模式:为了解决 session 模式隔离性差的问题,每个作业根据资源需求启动独立的集群,每个作业的 JM 也是运行在独立的进程中,负载相对小很多。
以上两种模式的共同问题是需要在客户端执行用户代码,编译生成对应的 Job Graph 提交到集群运行。在这个过程需要下载相关 jar 包并上传到集群,客户端和网络负载压力容易成为瓶颈,尤其当一个客户端被多个用户共享使用。
1.11.0 中引入了 application 模式(FLIP-85)来解决上述问题,按照 application 粒度来启动一个集群,属于这个 application 的所有 job 在这个集群中运行。核心是 Job Graph 的生成以及作业的提交不在客户端执行,而是转移到 JM 端执行,这样网络下载上传的负载也会分散到集群中,不再有上述 client 单点上的瓶颈。
用户可以通过 bin/flink run-application 来使用 application 模式,目前 Yarn 和 Kubernetes(K8s)都已经支持这种模式。Yarn application 会在客户端将运行作业需要的依赖都通过 Yarn Local Resource 传递到 JM。K8s application 允许用户构建包含用户 jar 与依赖的镜像,同时会根据作业自动创建 TM,并在结束后销毁整个集群,相比 session 模式具有更好的隔离性。K8s 不再有严格意义上的 per-job 模式,application 模式相当于 per-job 在集群进行提交作业的实现。
除了支持 application 模式,Flink 原生 K8s 在 1.11.0 中还完善了很多基础的功能特性(FLINK-14460),以达到生产可用性的标准。例如 Node Selector、Label、Annotation、Toleration 等。为了更方便的与 Hadoop 集成,也支持根据环境变量自动挂载 Hadoop 配置的功能。
2 Checkpoint & Savepoint 优化
checkpoint 和 savepoint 机制一直是 Flink 保持先进性的核心竞争力之一,社区在这个领域的改动很谨慎,最近的几个大版本中几乎没有大的功能和架构上的调整。在用户邮件列表中,我们经常能看到用户反馈和抱怨的相关问题:比如 checkpoint 长时间做不出来失败,savepoint 在作业重启后不可用等等。1.11.0 有选择的解决了一些这方面的常见问题,提高生产可用性和稳定性。
1.11.0 之前, savepoint 中 meta 数据和 state 数据分别保存在两个不同的目录中,这样如果想迁移 state 目录很难识别这种映射关系,也可能导致目录被误删除,对于目录清理也同样有麻烦。1.11.0 把两部分数据整合到一个目录下,这样方便整体转移和复用。另外,之前 meta 引用 state 采用的是绝对路径,这样 state 目录迁移后路径发生变化也不可用,1.11.0 把 state 引用改成了相对路径解决了这个问题(FLINK-5763),这样 savepoint 的管理维护、复用更加灵活方便。
实际生产环境中,用户经常遭遇 checkpoint 超时失败、长时间不能完成带来的困扰。一旦作业 failover 会造成回放大量的历史数据,作业长时间没有进度,端到端的延迟增加。1.11.0 从不同维度对 checkpoint 的优化和提速做了改进,目标实现分钟甚至秒级的轻量型 checkpoint。
首先,增加了 Checkpoint Coordinator 通知 task 取消 checkpoint 的机制(FLINK-8871),这样避免 task 端还在执行已经取消的 checkpoint 而对系统带来不必要的压力。同时 task 端放弃已经取消的 checkpoint,可以更快的参与执行 coordinator 新触发的 checkpoint,某种程度上也可以避免新 checkpoint 再次执行超时而失败。这个优化也对后面默认开启 local recovery 提供了便利,task 端可以及时清理失效 checkpoint 的资源。
其次,在反压场景下,整个数据链路堆积了大量 buffer,导致 checkpoint barrier 排在数据 buffer 后面,不能被 task 及时处理对齐,也就导致了 checkpoint 长时间不能执行。1.11.0 中从两个维度对这个问题进行解决:
1)尝试减少数据链路中的 buffer 总量(FLINK-16428),这样 checkpoint barrier 可以尽快被处理对齐。
- 上游输出端控制单个 sub partition 堆积 buffer 的最大阈值(backlog),避免负载不均场景下单个链路上堆积大量 buffer。
- 在不影响网络吞吐性能的情况下合理修改上下游默认的 buffer 配置。
- 上下游数据传输的基础协议进行了调整,允许单个数据链路可以配置 0 个独占 buffer 而不死锁,这样总的 buffer 数量和作业并发规模解耦。根据实际需求在吞吐性能和 checkpoint 速度两者之间权衡,自定义 buffer 配比。
这个优化有一部分工作已经在 1.11.0 中完成,剩余部分会在下个版本继续推进完成。
2)实现了全新的 unaligned checkpoint 机制(FLIP-76)从根本上解决了反压场景下 checkpoint barrier 对齐的问题。实际上这个想法早在 1.10.0 版本之前就开始酝酿设计,由于涉及到很多模块的大改动,实现机制和线程模型也很复杂。我们实现了两种不同方案的原型 POC 进行了测试、性能对比,确定了最终的方案,因此直到 1.11.0 才完成了 MVP 版本,这也是 1.11.0 中执行引擎层唯一的一个重量级 feature。其基本思想可以概括为:
- Checkpoint barrier 跨数据 buffer 传输,不在输入输出队列排队等待处理,这样就和算子的计算能力解耦,barrier 在节点之间的传输只有网络延时,可以忽略不计。
- 每个算子多个输入链路之间不需要等待 barrier 对齐来执行 checkpoint,第一个到的 barrier 就可以提前触发 checkpoint,这样可以进一步提速 checkpoint,不会因为个别链路的延迟而影响整体。
- 为了和之前 aligned checkpoint 的语义保持一致,所有未被处理的输入输出数据 buffer 都将作为 channel state 在 checkpoint 执行时进行快照持久化,在 failover 时连同 operator state 一同进行恢复。换句话说,aligned 机制保证的是 barrier 前面所有数据必须被处理完,状态实时体现到 operator state 中;而 unaligned 机制把 barrier 前面的未处理数据所反映的 operator state 延后到 failover restart 时通过 channel state 回放进行体现,从状态恢复的角度来说最终都是一致的。注意这里虽然引入了额外的 in-flight buffer 的持久化,但是这个过程实际是在 checkpoint 的异步阶段完成的,同步阶段只是进行了轻量级的 buffer 引用,所以不会过多占用算子的计算时间而影响吞吐性能。
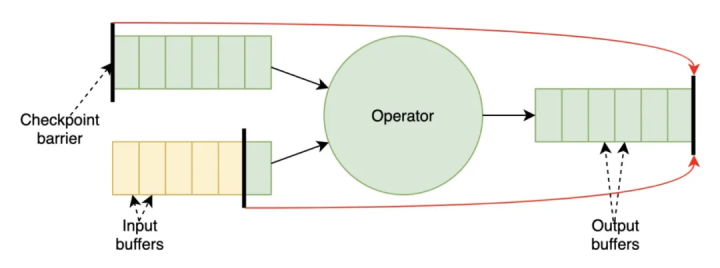
Unaligned checkpoint 在反压严重的场景下可以明显加速 checkpoint 的完成时间,因为它不再依赖于整体的计算吞吐能力,而和系统的存储性能更加相关,相当于计算和存储的解耦。但是它的使用也有一定的局限性,它会增加整体 state 的大小,对存储 IO 带来额外的开销,因此在 IO 已经是瓶颈的场景下就不太适合使用 unaligned checkpoint 机制。
1.11.0 中 unaligned checkpoint 还没有作为默认模式,需要用户手动配置来开启,并且只在 exactly-once 模式下生效。但目前还不支持 savepoint 模式,因为 savepoint 涉及到作业的 rescale 场景,channel state 目前还不支持 state 拆分,在后面的版本会进一步支持,所以 savepoint 目前还是会使用之前的 aligned 模式,在反压场景下有可能需要很长时间才能完成。
四 总结
Flink 1.11.0 版本的开发过程中,我们看到越来越多来自中国的贡献者参与到核心功能的开发中,见证了 Flink 在中国的生态发展越来越繁荣,比如来自腾讯公司的贡献者参与了 K8s、checkpoint 等功能开发,来自字节跳动公司的贡献者参与了 Table & SQL 层以及引擎网络层的一些开发。希望更多的公司能够参与到 Flink 开源社区中,分享在不同领域的经验,使 Flink 开源技术一直保持先进性,能够普惠到更多的受众。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java