
从Java BIO到NIO再到多路复用
从一次优化说起
近期优化了一个老的网关系统,在dubbo调用接口rt1000ms时吞吐量提升了25倍,而线程数却由64改到8。其他的优化手段不做展开,比较有意思的是为什么线程数减少,吞吐量却可以大幅提升?这就得从IO模型说起,貌似工作中很少使用IO,更别提NIO,但实际上我们工作中每天都在和IO打交道。我们所用到的中间件redis,rocketMq,nacos,mse,dubbo等等存在文件操作,存在网络通信的地方就存在IO。所以深入了解IO模型重要性可想而知,IO操作作为计算机系统中一个基本操作,几乎所有应用程序都需要,了解不同IO模型可助我们理解应用程序中IO操作底层原理,从而更好地优化应用程序的性能和可靠性。
接下来我会结合一些例子和代码,以最简单易懂的方式把IO的演进历程和大家探讨。
IO模型分类
分类
首先来谈下IO模型的分类:
1.BIO(Blocking I/O):同步阻塞I/O,传统的I/O模型。在进行I/O操作时,必须等待数据读取或写入完成后才能进行下一步操作。
2.NIO(Non-blocking I/O):同步非阻塞I/O,是一种事件驱动的I/O模型。在进行I/O操作时,不需要等待操作完成,可以进行其他操作。
3.AIO(Asynchronous I/O):异步非阻塞I/O,是一种更高级别的I/O模型。在进行I/O操作时,不需要等待操作完成,就可继续进行其他操作,当操作完成后会自动回调通知
由上可见,IO模型涉及四个非常重要的概念,只有弄懂了这些概念才能深入了解IO。那什么叫阻塞,非阻塞,什么叫同步异步呢?
举例
举个例子,中午吃饭
- 自选餐线,我们点餐的时候都得在队伍里排队等待,必须等待前面的同学打好菜才到我们,这就是同步阻塞模型BIO。
- 麻辣烫餐线,会给我们发个叫号器,我们拿到叫号器后不需排队原地等待,我们可以找个地方去做其他事情,等麻辣烫准备好,我们收到呼叫之后,自行取餐,这就是同步非阻塞。
- 包厢模式,我们只要点好菜,坐在包厢可以自己玩,等到饭做好,服务员亲自送,无需自己取,这就是异步非阻塞I/O模型AIO。
概念详解
针对以上举例,和我们实际工作中的概念进行对比
- 食堂->操作系统
- 饭菜->数据
- 饭菜好了->数据就绪
- 端菜/送菜->数据读取
阻塞和非阻塞
- 菜没好,是否原地等待->数据就绪前是否等待;
- 阻塞:数据未就绪,读阻塞直到有数据,缓冲区满时,写操作也会阻塞等待。本质上是线程挂起,不能做其他事;
- 非阻塞:请求直接返回,本质上线程活跃,可以处理其他事情;
同步与异步
- 菜好了,谁端?->数据就绪,是操作系统送过去,还是应用程序自己读取;
- 同步:数据就绪后应用程序自己读取;
- 异步:数据就绪后操作系统直接回调应用程序;
Java支持版本
| 举例 | IO模型 | 支持的jdk版本 |
| 排队打饭 | BIO(同步阻塞I/O) | jdk1.4之前 |
| 等待叫号 | NIO(同步非阻塞I/O) | jdk1.4之后(2002,java.nio包) |
| 包厢模式 | AIO(异步I/O) | jdk1.7之后(2011,java.nio包下java.nio.channels.AsynchronousSocketChannel等) |
AIO其实很早就支持了,但是业界主流IO框架却很少使用呢,比如netty, 从 2.x 开始引入AIO,随后,3.x也继续保持,但到了4.x却删除对AIO的支持,能让一款世界级最优秀的IO框架之一做出舍弃AIO,那肯定是有迫不得已的原因,那原因到底是啥呢?
- 对AIO支持最好的是Windows系统,但是很少用Windows做服务器;
- linux常用来做服务器,但AIO的实现不够成熟;
- linux下AIO相比NIO性能提升并不明显;
- 维护成本过高;
因为上面的原因,后面内容主要说的就是BIO,NIO。
实战
c10k问题
说到IO模型的的演进,那就不得不提到c10k问题,c10k(cuncurrent 10 000 connections),简单来讲就是服务器如何处理10k个连接,大家如果感兴趣可以到这里http://www.kegel.com/c10k.html详细了解。
对程序员来说,概念的描述,加生活类比,是可以帮助快速了解某一个领域基本概念,但是最简单,最直接,最有体感的方式,还得是代码。接下来我会用代码模拟c10k问题,然后通过使用不同IO模型来演进IO模型的发展历程。
上代码
套用一下咱们IT届十大金句之一。

模拟10 000个客户端
public class C10kTestClient {
static String ip = "192.168.160.74";
public static void main(String[] args) throws IOException {
LinkedList<SocketChannel> clients = new LinkedList<>();
InetSocketAddress serverAddr = new InetSocketAddress(ip, 9998);
IntStream.range(20000, 50000).forEach(i -> {
try {
SocketChannel client = SocketChannel.open();
client.bind(new InetSocketAddress(ip, i));
client.connect(serverAddr);
System.out.println("client:" + i + " connected");
clients.add(client);
} catch (IOException e) {
System.out.println("IOException" + i);
e.printStackTrace();
}
});
System.out.println("clients.size: " + clients.size());
//阻塞主线程
System.in.read();
}
}代码比较简单,直接使用BIO串行创建30000个连接。
BIO服务端
首先出场的是BIO选手
public class BIOServer {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(9998, 20);
System.out.println("server begin");
while (true) {
//阻塞1
Socket client = server.accept();
System.out.println("accept client" + client.getPort());
new Thread(() -> {
InputStream in;
try {
in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
//阻塞2
String data = reader.readLine();
if (null != data) {
System.out.println(data);
} else {
client.close();
break;
}
}
System.out.println("client break");
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
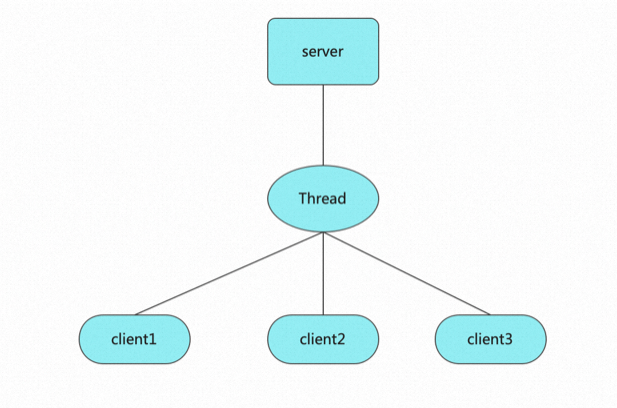
}请目光聚焦第7行,这里会产生阻塞,接收到一个客户端连接后才能继续运行。再聚焦第16行,reader.readLine会产生阻塞,如果是单线程,则线程挂起,那么只能处理极少数连接。所以为了让程序能支持多个客户端,不得不使用多线程,最终得到模型如下:
该代码如果直接在mac本地跑,一般情况下会报如下错误:
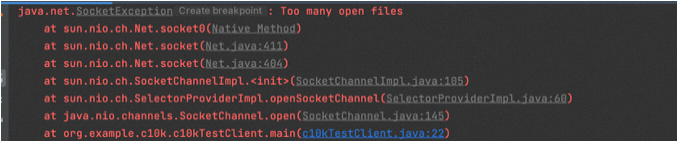
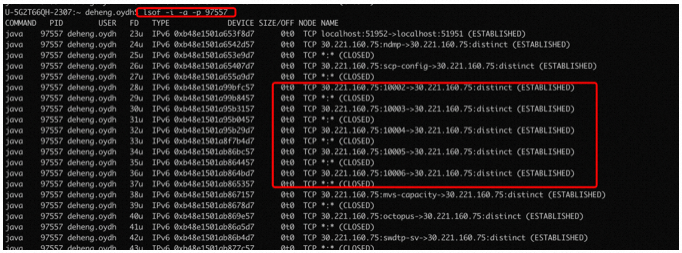
too many open files,这里说明打开的文件描述符过多,什么是文件描述符?文件描述符(file descriptor简称fd,请记住这个概念,后续会多次出现)在linux中,一切皆文件。实际上,它是一个索引值,指向一个文件记录表,该表记录内核为每一个进程维护的文件记录信息。由于本例中创建了三万个socket,而一个socket(即一个tcp连接)就对应一个文件描述符(fd),30000已经超过了系统默认的文件描述符限制。那怎么去查看fd信息呢?可通过lsof -i -a -p [pid]查看当前进程打开的tcp相关的文件描述符,如下图,红框标注的就是socket对应的fd:
解决这个问题也很简单,可通过如下方式设置文件描述符数量
https://juejin.cn/s/java.net.socketexception%20too%20many%20open%20files%20macos
处理完文件描述符过多的问题之后,继续重新跑客户端,又报错了。
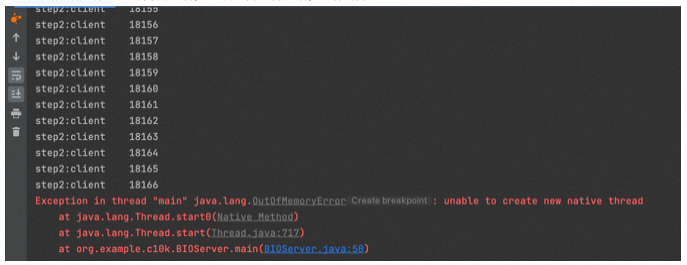
unable to create new native thread 不能再创建新的本地线程。当然,系统线程数限制是可以调节的。但是存在的问题也很明显,具体有哪些问题呢?从上面的分析,结合BIO处理c10k的过程,不难得出以下问题:
- 一个连接需要一个线程,一台机器开辟线程数有限;
- 线程是轻量级进程,操作系统会为每一个线程分配1M独立的栈空间,如果要处理c10k(10000个连接),就得有10G的栈空间;
- 即便是内存空间足够,一台机器的cpu核数是有限的。比如我们线上机器是4核,10000个线程情况下,cpu大量时间是耗费在线程调度而不是业务逻辑处理上,会产生极大浪费;
所以BIO存在的核心问题是阻塞导致多线程,如何解决?那就是非阻塞+少量线程。
接下来有请NIO选手闪亮登场:
NIO服务端
public class NIOServer {
public static void main(String[] args) throws IOException, InterruptedException {
LinkedList<SocketChannel> clients = new LinkedList<>();
//服务端开启监听
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(9998));
//设置操作系统 级别非阻塞 NONBLOCKING!!!
serverSocketChannel.configureBlocking(false);
while (true) {
//接受客户端的连接
Thread.sleep(500);
/**
* accept 调用了内核,
* 在设置configureBlocking(false) 及非阻塞的情况下
* 若有客户端连进来,直接返回客户端,
* 若无客户端连接,则返回null
* 设置成NONBLOCKING后,代码不阻塞,线程不挂起,继续往下执行
*/
SocketChannel client = serverSocketChannel.accept();
if (client == null) {
// System.out.println("null.....");
} else {
/**
* 重点,设置client读写数据时非阻塞
*/
client.configureBlocking(
false);
int port = client.socket().getPort();
System.out.println("client..port: " + port);
clients.add(client);
}
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
//遍历所有客户端,不需要多线程
for (SocketChannel c : clients) {
//不阻塞
int num = c.read(buffer);
if (num > 0) {
buffer.flip();
byte[] aaa = new byte[buffer.limit()];
buffer.get(aaa);
String b = new String(aaa);
System.out.println(c.socket().getPort() + " : " + b);
buffer.clear();
}
}
}
}
}
NIO相比BIO有个非常牛逼的特性,即设置非阻塞。可通过 java.nio.AbstractSelectableChannel 下的configureBlocking方法,调用内核,设置当前socket接收客户端连接,或者读取数据为非阻塞(BIO中这两个操作都为阻塞),啥是socket?socket就是TPC连接的抽象,客户端client.connect(serverAddr); 实际上底层就会调用系统内核就处理三次握手,建立tcp连接。
从代码中不难看出,相比BIO,NIO的优势:
- 建立连接和读写数据非阻塞
- 无需开辟过多线程
那它是不是就是完美解决方案了呢?如果你细心看以上37行到48行代码,就会发现,只要有一个连接进来,就不管三七二十一遍历所有客户端,调用系统调用read方法。实际情况可能并没有客户端有数据到达,这就产生了一个新的问题。
- 无论是否有读写事件,都需要空遍历所有客户端连接,产生大量系统调用,大量浪费CPU资源。
如果你来设计,你会想着怎么优化呢?
其实也比较容易,就是有没有办法,我不要用去遍历所有客户端,因为10k个客户端我就得调用10k次系统调用,就得产生10k次用户态和内核态的来回切换(回顾下计算机组成原理,感受下这个资源消耗),而只调用一次内核就能知道哪些连接有数据。嗯,Linus Torvalds(linux之父)也是这样想的,所以就出现了多路复用。
多路复用
先上一段多路复用的代码
public class SelectorNIOSimple {
private Selector selector = null;
int port = 9998;
public static void main(String[] args) {
SelectorNIO service = new SelectorNIO();
service.start();
}
public void initServer() {
try {
ServerSocketChannel server = ServerSocketChannel.open();
server.configureBlocking(false);
server.bind(new InetSocketAddress(port));
selector = Selector.open();
server.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
initServer();
while (true) {
try {
Set<SelectionKey> keys = selector.keys(); System.out.println("可处理事件数量 " + keys.size());
while (selector.select() > 0) {
//返回的待处理的文件描述符集合
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
//使用后需移除,否则会被一直处理
iterator.remove();
if (key.isAcceptable()) {
acceptHandler(key);
} else if (key.isReadable()) {
readHandler(key);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void acceptHandler(SelectionKey key) {
try {
ServerSocketChannel ssc = (ServerSocketChannel)key.channel();
SocketChannel client = ssc.accept();
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(1024);
client.register(selector, SelectionKey.OP_READ, buffer);
System.out.println("client connected:" + client.getRemoteAddress());
} catch (IOException e) {
e.printStackTrace();
}
}
public void readHandler(SelectionKey key) {
SocketChannel client = (SocketChannel)key.channel();
ByteBuffer buffer = (ByteBuffer)key.attachment();
buffer.clear();
int read;
try {
while (true) {
read = client.read(buffer);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
client.write(buffer);
}
buffer.clear();
} else if (read == 0) {
break;
} else {
client.close();
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}如果对NIO了解不多,咋看起来是不是比BIO/NIO的代码更复杂了?没事,待我慢慢道来。
概念
咱们先说下啥是多路复用?
在Linux中,多路复用指的是一种实现同时监控多个文件描述符(包括socket,文件和标准输入输出等)的技术。它可以通过一个进程同时接受多个连接请求或处理多个文件的IO操作,提高程序的效率和响应速度。
怎么去理解这段话?结合我们上面的例子,说的直白一点就是一次系统调用,我就能得到多个客户端是否有读写事件。
多路(多个客户端)复用(复用一次系统调用)
多路复用是依赖内核的能力,不同的操作系统都有自己不同的多路复用器实现,这里以linux为例,多路复用又分为两个阶段。
阶段一:select&poll
select是在Linux内核2.0.0版本中出现的,于1996年6月发布,而poll则是在Linux内核2.1.44版本中被引入,于1997年3月发布。
可在命令行 输入 man 2 select/poll 去查看linux对它们的解释
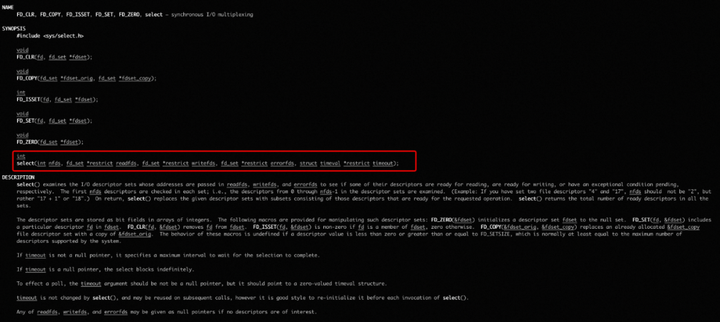

简单说下select
int select(int nfds, //要监视的文件描述符数量
fd_set *restrict readfds, //可读文件描述符集合
fd_set *restrict writefds, //可写文件描述符集合
fd_set *restrict errorfds, //异常文件描述符集合
struct timeval *restrict timeout//超时时间
);看下入参,需要用户主动传入要监视的文件描述符数量,可读文件描述符集合,可写文件描述符集合,异常文件描述符集合等入参,实际上就干了一件事,以前由用户态去循环遍历所有客户端产生系统调用(如果10k个socket,需要产生10k个系统调用),改成了由内核遍历,如果select模式,只需10系统调用(因为select最大支持传入1024个文件描述符),如果是poll模式(不限制文件描述符数量),则只需1次系统调用。
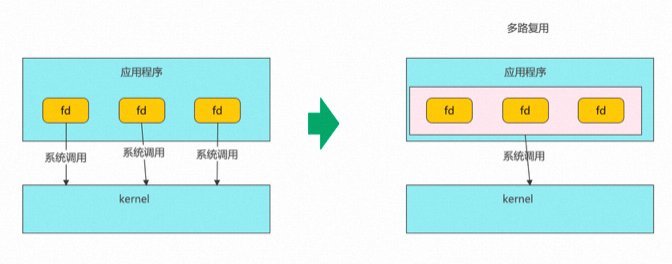
pool和select同属第一阶段,因为它们处理问题的思路基本相同,但也有如下区别:
1.实现机制不同:select使用轮询的方式来查询文件描述符上是否有事件发生,而poll则使用链表来存储文件描述符,查询时只需要对链表进行遍历。
2.文件描述符的数量限制不同:select最大支持1024个文件描述符,poll没有数量限制,可以支持更多的文件描述符。
3.阻塞方式不同:select会阻塞整个进程,而poll可以只阻塞等待的文件描述符。
4.可移植性不同:select是POSIX标准中的函数,可在各种操作系统上使用,而poll是Linux特有的函数,不是标准的POSIX函数,在其他操作系统上可能不被支持。
那是不是select和pool就很完美了呢,当然不是,这里还存在一个问题:
- 大量的fd(即连接)需要在用户态和内核态互相拷贝
啥叫高性能,高性能首先要做到的就是避免资源浪费,fd集合在用户态和内核态互相拷贝就是一种浪费,越是在底层,一个细微的优化,对系统性能的提升都是巨大的。如何解决?linus大神又出手了,杜绝拷贝(不需要在用户态和内核态互相拷贝),空间换时间,在内核为应用程序开辟一块空间,这就是epoll要干的事情。
阶段二epoll
终于到epoll了,Linux epoll在2.6内核版本中发布,于2002年发布,这里大家可以回过头去看下,java.nio也刚好在2002年推出。
epoll执行过程
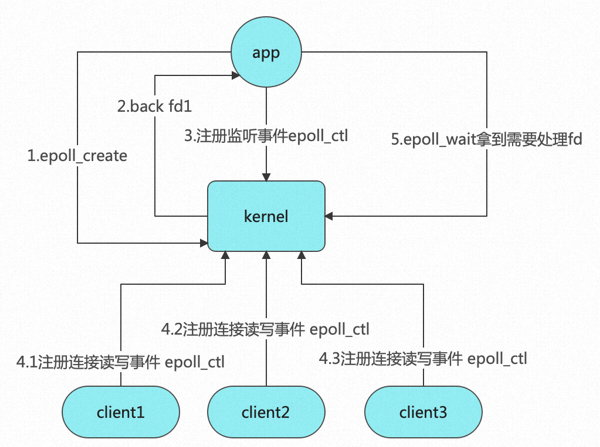
- 应用程序调用内核系统调用,开辟内存空间
- 对应的系统调用:int epoll_create(int size);
- 应用程序新连接,注册到对应的内核空间
- 对应的系统调用 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- 应用程序询问需要处理的连接
- 哪些需要处理?有读,写,错误的事件
- 对应的系统调用 :int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
Java selector
刚才带大家看了下linux操作系统多路复用的发展历程,那java.nio是怎么使用的呢?其实在一开始就贴出了java selector的代码实现,发现比前面的版本代码会复杂不少,但第一遍咱们只是知道怎么写,至于为什么这么写,并没有讲的很清楚,有了上面的铺垫,再去看这段代码,是不是会有不一样的感觉呢
代码内加入了关键注释,串联linux多路复用器相关知识,强烈建议阅读下代码:
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java