
Dubbo 构建金融微服务架构的实践
背景及概览
工行传统的业务系统一般都是基于 JEE 的单体架构,面对金融业务线上化及多样化的发展趋势,传统架构已经无法满足业务的需求。因此从 2014 年开始,工行选择了一个业务系统做服务化的尝试,并验证、评估、对比了当时的几个分布式服务框架,最终选择了相对完善、并且国内已经有较多公司落地使用的 Dubbo。与此同时,工行还对 Dubbo 做了企业定制,帮助这个业务系统完成了服务化的落地,上线之后也收到了非常好的效果。
2015 年,工行开始扩大服务架构的落地范围,一方面帮助传统业务系统进行架构转型,另一方面也逐渐沉淀了类似中台的超大规模服务群组,支撑业务系统快速服务的组合和复用。随着经验积累,工行也不断对 Dubbo 进行迭代优化和企业定制,同时围绕服务也逐步打造了完善的服务生态体系。
2019 年,工行的微服务体系也正式升级为工行开放平台核心银行系统的关键能力之一,助力工行 IT 架构实现真正的分布式转型。
工行的微服务体系组成如下图所示:
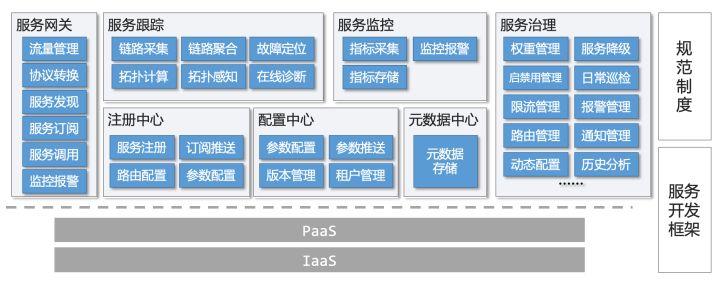
- 基础设施方面,不管是业务系统的服务节点,还是微服务平台自身的工作节点,都已部署在工行的云平台。
- 服务注册发现方面,除了常规的服务注册中心外,还配合部署了元数据中心,用于实现服务的按节点注册发现。
- 服务配置方面,通过外部的分布式配置中心,以实现各类动态参数的统一管理和下发。
- 服务监控方面,实现对服务各类运行指标的统一采集和存储,并与企业的监控平台对接。
- 服务跟踪方面,主要是用于实时跟踪服务的整体链路,帮助业务系统快速定位故障点,并准确评估故障的影响范围。
- 服务网关是为了满足传统业务系统访问服务需求,在 Dubbo 服务订阅及 RPC 能力之上,实现了新服务、新版本的自动发现、自动订阅和协议转换能力(HTTP 协议转 RPC 协议),实现 7×24 小时不间断运行。
- 服务治理平台,提供给运维人员和开发测试人员一个一站式的管理、监控、查询的平台,提升日常服务治理的效率。
最大的挑战
经过工行多年的落地实践,本文共总结了以下两方面的最大挑战:
- 性能容量方面,目前线上服务数(即 Dubbo 概念中的服务接口数),已超 2 万,每个注册中心上的提供者条目数(即每个服务的所有提供者累计),已超 70 万。根据评估,未来需要能支撑 10 万级别的服务数,以及每个注册中心 500 万级的提供者条目数。
- 高可用方面,工行的目标是:微服务平台任何节点故障都不能影响线上交易。银行的业务系统 7×24 小时运行,即使在版本投产时间窗内,各业务系统的投产时间也是相互错开的,平台自身节点要做升级,如何避免对线上交易带来影响,特别是注册中心的自身的版本更新。
本文将先从服务发现方面,来分享一下工行的应对策略及成效。
服务发现难点和优化
1. 入门
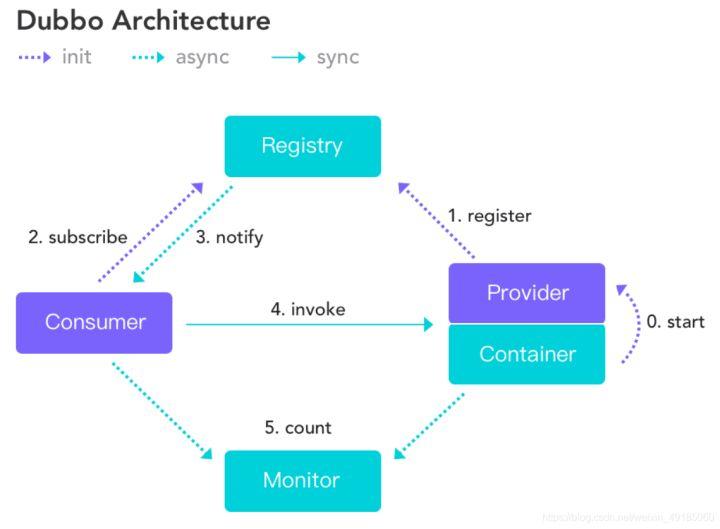
在 Dubbo 中,服务的注册订阅及调用是一个标准范式,服务的提供者初始化时注册服务,服务消费者初始化时订阅服务并获取全量提供者列表。而运行期间,服务提供者发生变化时,服务消费者可获取最新的提供者列表。消费者与提供者之间点对点 RPC 调用,调用过程不经注册中心。
在注册中心的选择上,工行在 2014 年就选择了 Zookeeper。Zookeeper 在业界的各类场景下有大规模的应用,并且支持集群化部署,节点间数据一致性通过 CP 模式保证。
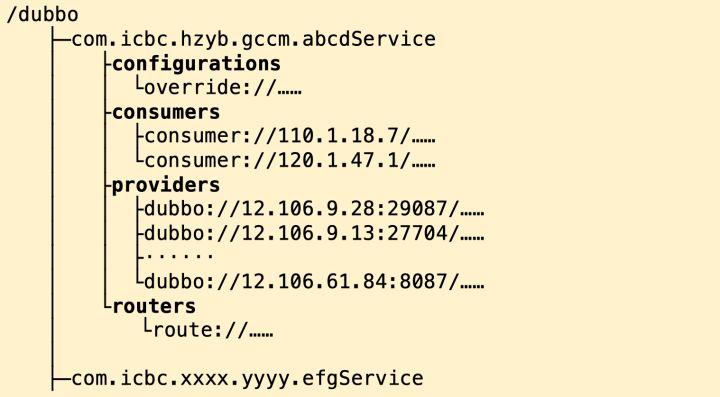
在 Zookeeper 内部,Dubbo 会按服务建立不同的节点,每个服务节点下又有 providers、consumers、configurations 及 routers 四个字节点:
- providers 临时节点:记录该服务提供者清单。提供方下线子节点就自动删除,通过 Zookeeper 的 watch 机制,消费者可以第一时间知道提供者清单发生了变化。
- consumers 临时节点:记录消费者的清单,主要用于服务治理时查询消费者。
- configurations 持久节点:主要保存服务治理时需要调整的服务参数。
- routers:子节点为持久节点,主要用于配置服务的动态路由策略。

在线上生产环境,Zookeeper 分数据中心部署了多个集群,每个集群配置了 5 个选举节点,若干个 Observer 节点。Observer 节点是 Zookeeper3.3.3 版本引入的一个新的节点类型,它不参与选举,只听取表决结果,其他能力则和 Follower 节点相同。Observer 节点有以下几方面的好处:
- 分流网络压力:随着服务节点的增多,如果客户端都连接选举节点,对选举节点来说需要消耗大量的 CPU 去处理网络连接和请求。但是选举节点又无法任意水平扩容,选举节点越多,事务投票过程就越长,对高并发写性能是不利的。
- 降低跨城跨 DC 的注册订阅流量:当有 100 个消费者需要跨城订阅同一个服务,Observer 可以统一处理这部分跨城网络流量,避免对城际间的网络带宽带来压力。
- 客户端隔离:可以将几个 Observer 节点专门分配给某个重点应用使用,保障其网络流量隔离。
2. 问题分析
工行根据这几年线上 Zookeeper 的使用心酸血泪史,总结了 Zookeeper 在作为服务注册中心时面临的问题:

- 随着服务数量以及服务提供者节点的增加,服务推送的数据量会呈爆炸式增长。举个例子,一个服务有 100 个提供者,当提供者启动的时候,因为 Zookeeper 的 CP 特性,每上线一个提供者,消费者都会收到事件通知,并从 Zookeeper 来读取这个服务的当前全部提供者的列表,然后刷新本地缓存。这个场景下,理论上每个消费者总共收到了 100 次事件通知,并从 Zookeeper 读取了 100 次服务提供者列表,1+2+3+...+100,总计 5050 条提供者数据。这在业务系统投产高峰期问题尤为突出,容易导致 Zookeeper 集群的网络被打满,造成服务订阅效率极其低下,并进一步影响了服务注册的性能。
- 随着写在 Zookeeper 上节点数量的增多,Zookeeper 的 snapshot 文件也不断变大,每次 snapshot 写入磁盘,会出现一次磁盘 IO 冲高。投产高峰期,因为事务量大,写 snapshot 文件的频率也非常高,这对基础设施带来了较大的风险。同时 snapshot 文件越大,也预示着 Zookeeper 节点故障后恢复的时间越长。
- 当 Zookeeper 选举节点发生重新选举后,Observer 节点都要从新的 Leader 节点同步全量事务,这个阶段如果耗时过长,就很容易导致连接在 Observer 节点上的客户端 session 超时,使对应 providers 节点下的临时节点全部被删除,即从注册中心角度看,这些服务都下线了,消费者端则出现无提供方的异常报错。紧接着,这些提供者会重新连接 Zookeeper 并重新注册服务,这种短时间内大批量服务的注册翻转现象,往往带来更为严重的服务注册推送的性能问题。
综上,可以得出的结论是:总体上 Zookeeper 作为注册中心还是比较称职的,但在更大规模服务量场景下,需要进一步优化。
3. 优化方案
工行最主要的优化措施包括下面这几方面:订阅延迟更新、注册中心采取 multiple 模式、升级到按节点注册等。
1)订阅延迟更新
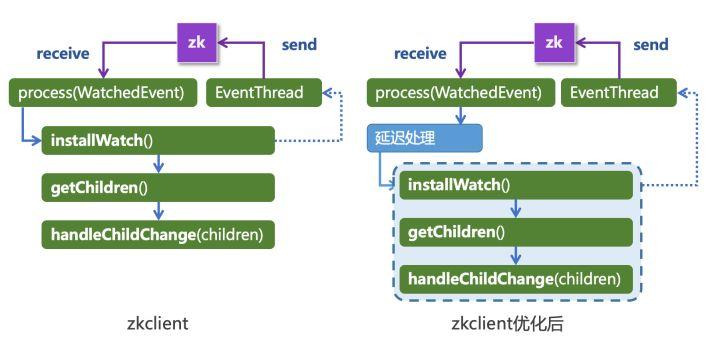
工行对 Zookeeper 客户端组件 zkclient 做了优化,把消费者收到事件通知后获取提供者列表做了一个小的延时。
当 zkclient 收到 childchange 一次性的事件后,installWatch() 通过 EventThread 去恢复对节点的监听,同时又使用 getChildren() 去读取节点下的全部子节点获取提供者列表,并刷新本地服务提供者缓存。这就是前面说的“5050 条数据”问题的根源。
工行在 zkclient 收到 childchange() 的事件后,做了个等待延迟,再让 installWatch() 去做它原来该做的事情。这个等待过程中如果服务提供者发生变化,则不产生 childchange 事件。
有人会问,这是不是违背了 zookeeper 的 CP 模型呢,其实并不是,zookeeper 服务端的数据是强一致的,消费者也收到了事件通知,只是延后去读取提供者清单,后面执行 getChildren() 时,读取到的已经是 zookeeper 上的最新数据,所以是没有问题的。
内部压测结果显示,服务提供者大规模上线时,优化前,每个消费者收到了总计 422 万个提供者节点的数据量,而延迟 1 秒处理后,这个数据量则变成了 26 万,childchange 事件次数和网络流量都变成了原来的 5% 左右,做完这个优化,就能从容应对投产高峰期大量服务的上下线。
2)Multiple 模式
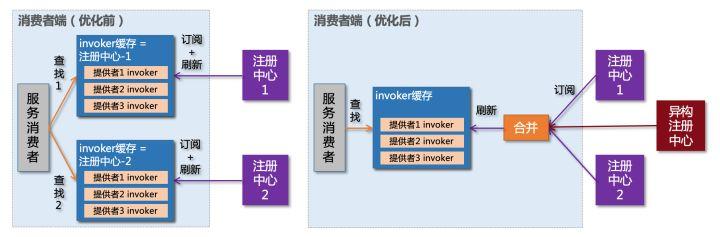
工行采纳并优化改造了 Dubbo 新版本中 registry-multiple 的 SPI 实现,用于优化多注册中心场景下的服务订阅。
Dubbo 中服务消费者原有处理逻辑是这样:当存在多个注册中心的时候,消费者按注册中心对应的 invoker 缓存去筛选提供方,第一个注册中心对应的缓存中如果没找到,则去找第二个注册中心对应的缓存。如果此时第一个注册中心出现可用性问题,推送给消费者的数据有缺失,甚至为空,就会影响消费者的这个筛选过程,如出现无提供方的异常、调用负载不均衡等。
而 multiple 注册中心是把多个注册中心推送的数据合并后再更新缓存,所以即使单个注册中心故障,推送了数据不完整或者为空,只要有其他任意一个注册中心的数据使完整的,就不会影响最后合并的数据。
并且,multiple 注册中心机制也用于异构的注册中心场景,出现问题可以随时把注册中心下线,这个过程对服务节点的服务调用则完全透明,比较适合灰度试点或者应急切换。
更进一步,还有额外的收益,消费者端 Reference 对象是比较占用 JVM 内存,通过 multiple 注册中心模式,可以帮消费者端节省一半的 invoker 对象开销,因此,非常推荐多个注册中心场景采用 multiple 模式。
3)按节点注册
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java