
Redis 搭建主从复制架构与优化
主从复制
我们关注主从复制之前,首先要考虑单机有什么问题?
- 机器故障
- 容量瓶颈
- QPS瓶颈
这些都是单节点所遇到的问题,所以这个时候出现了主从复制(一主一从,一主多从)
使用主从复制可以:
- 数据副本
- 扩展读性能
注意:
- 一个master可以有多个slave
- 一个slave只有一个master
- 数据流向是单向的,master到slave
主从复制的配置
两种实现方式
- slaveof命令
两台机器:主节点:47.11.11.11 从节点 47.22.22.22
在从节点执行 slaveof 命令
47.22.22.22-6379 > slacefof 47.11.11.11 6379
OK取消复制:
47.22.22.22-6379 > slacefof no one
OK- 修改配置
slaveof ip port //从节点ip + 端口
slave-read-only yes //开启只做读的操作- 两种方式比较

- 查看主从
127.0.0.1:6379> info replication
# Replication
role:master //主节点
connected_slaves:0
master_replid:1d43401335a5343b27b1638fc9843e3a593fc1a7
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0知识点 :
- 主节点 runID:
每个redis节点启动后都会动态分配一个40位的十六进制字符串为运行ID。运行ID的主要作用是来唯一识别redis节点,比如从节点保存主节点的运行ID识别自已正在复制是哪个主节点。如果只使用ip+port的方式识别主节点,那么主节点重启变更了整体数据集(如替换RDB/AOF文件),从节点再基于偏移量复制数据将是不安全的,因此当运行ID变化后从节点将做全量复制。可以在info server命令查看当前节点的运行ID。
需要注意的是redis关闭再启动,运行的id会随之变化
全量复制和部分复制等
全量复制
用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点。当数据量过大的时候,会造成很大的网络开销。
redis2.8+ 全量复制流程
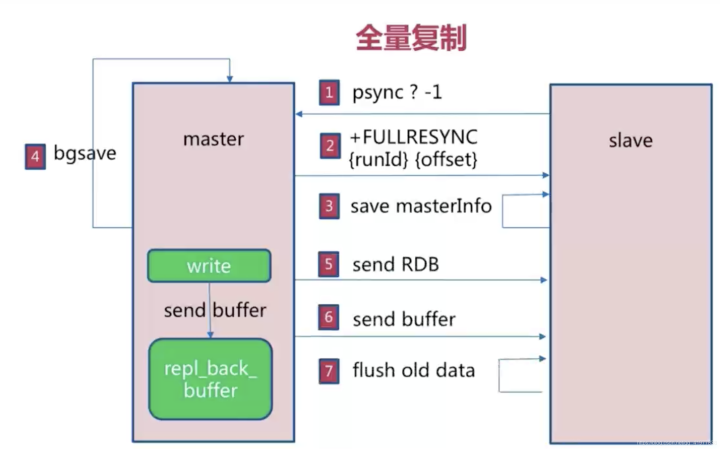
开销:
- bgsave时间
- RDB文件网络传输
- 从节点清空数据时间
- 从节点加载RDB时间
- 可能的AOF重写时间
部分复制
用于处理在主从复制中因网络闪退等原因造成数据丢失场景,当从节点再次连上主节点,如果条件允许,主节点会补发丢失数据给从节点,因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。但需要注意,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制 。
流程:
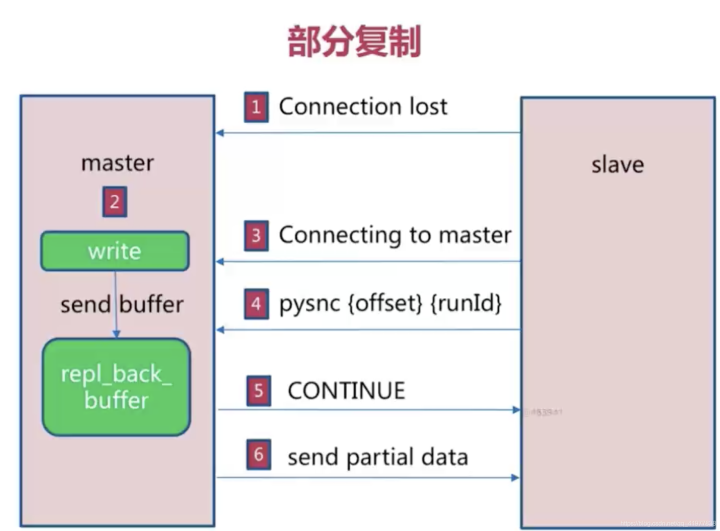
复制偏移量:
- 参与复制的主从节点都会维护自身复制偏移量,主节点在处理完写入命令操作后,会把命令的字节长度做累加记录,统计信息在info replication中的master_repl_offset指标中。
- 从节点每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量slave0:ip=192.168.1.3,port=6379,state=online,offset=116424,lag=0
- 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在info replication中的slave_repl_offset中。
复制积压缓冲区:
- 复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发给从节点,还会写入复制积压缓冲区。
在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中 的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长且先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。
生产中常见问题
读写分离
分流到从节点。主节点写数据,从节点读数据,可能遇到读问题
- 复制数据延迟
- 读到过期数据
- 从节点故障
主从配置不一致
- 例如maxmemory 不一致 会导致 丢失数据
- 例如数据结构优化参数(例如hash-max-ziplist-entries):内存不一致
规避全量复制
- 第一次全量复制的时候
- 第一次不可避免,尽量小节点 ,低峰处理 - 节点 运行ID不匹配
- 故障转移,例如哨兵或者集群 - 复制积压缓存区不足
- 增大复制缓存区配置rel_backlog_size ,网络增强
规避复制风暴
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java