
CPU 利用率提升至 55%,基于 K8s 的业务混部署实践
数据分析显示,数据中心成本中,服务器采购成本占比超过 50% ,而全球服务器平均资源利用率不到 20%,并且服务器一般 3~5 年就会淘汰,需要购置新服务器,造成了巨大的成本浪费。
如果数据中心或者机房规模较小,服务器数量有限,很少有人会去关注资源利用率这个问题。因为在小规模场景下,耗费人力、物力想办法提高服务器资源利用率并不会获得太高的收益。如果数据中心规模比较大,提升数据中心资源利用率则能够显著降低成本、带来巨大收益,所以国内外的大型互联网公司,很早就开始投入大量的人力物力进行较多的探索实践。
近几年,随着网易云音乐、严选、传媒、有道等互联网业务的快速发展,网易内部的服务器数量不断攀升,而实际资源利用率又比较低,IT 基础设施成本问题日益严峻。面对日益增长的业务,我们希望用最小的基础设施资源成本来支撑更大的业务需求。提升服务器资源利用率成为一个比较重要的解决手段。
网易轻舟团队提出了一套基于 kubernetes 的业务混部方案,目前已经在网易内部得到广泛应用,在不影响业务 SLO(service-level objective)的前提下,资源利用率得到显著提升。
资源利用率现状和原因分析
麦肯锡数据统计显示,整个业界的服务器平均利用率大约为 6%,而 Gartner 的估计要乐观一些,大概在 12%。国内一些银行的数据中心的利用率大概在 5% 左右 。
而造成利用率比较低的原因主要有以下三个方面:
不同类型的业务划分了独立的服务器资源池
绝大多数企业在构建数据中心或者机房的时候,对于在线服务(latency-sensitive service)和离线服务(batch job)是单独采购机器并且分开管理部署的,各自采用独立的资源调度管理系统(比如离线业务使用 Yarn 调度,在线业务 Mesos 调度),从服务器采购、规划到业务调度层面都是完全隔离的。
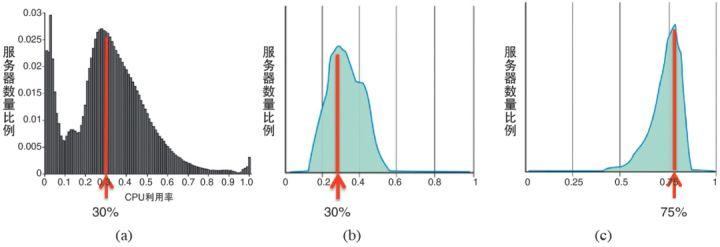 图 1 Google 数据中心资源使用情况
图 1 Google 数据中心资源使用情况
图 1(b) 是 Google 专门运行在线应用的 2 万台服务器 CPU 利用率分布图,大部分处于 30% 左右。图 1© 是 Google 专门运行批处理作业的 2 万台服务器 CPU 利用率分布图,大部分在 75% 左右。
在线业务 SLO 要求较高,为了保证服务的性能和可靠性,通常会申请大量的冗余资源,因此,会导致资源利用率很低、浪费比较严重。而离线业务,通常关注吞吐量,SLO 要求不高,容忍一定的失败,资源利用率很高。
假如将离线业务跑在在线业务的机器上,充分利用在线业务的空闲资源,那是不是就能节省下离线业务的服务器成本了呢?
服务的 reserved 资源和实际 used 资源存在较大 Gap,通常 overprovision
业务通常是有波峰和波谷的,用户在部署服务时,为了保证服务的性能和稳定性通常都会按照波峰申请资源,即 provision resource for the peek load,但是波峰的时间可能很短。另外,也有相当一部分用户对于自己服务的资源使用情况不是很了解,在申请资源时具有较大盲目性,但是通常也是申请过量资源而不是申请的过少。
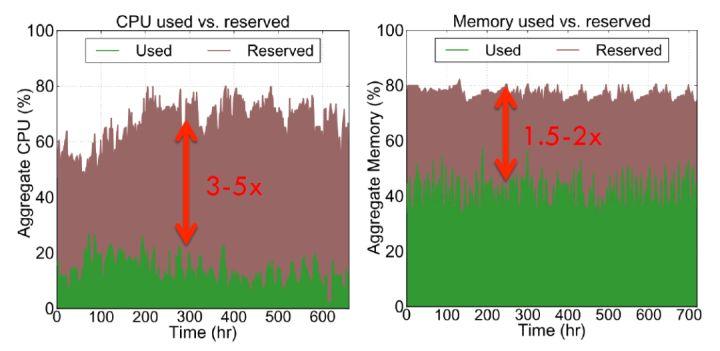 图 2 推特数据中心资源使用情况
图 2 推特数据中心资源使用情况
图 2 是推特数据中心资源使用情况,可以看到 cpu 利用率大约在 20% 左右,但是用户申请了 60% 左右的 cpu 资源;内存利用率在 40% 左右,但是用户申请了 80% 左右的内存资源 。
服务 A 已申请的但是实际没有使用的资源,即使是空闲的,其他服务也是不能够使用的。Reserved - Used差值越大,资源浪费越多。所以我们应该如何去缩小Reserved - Used的差值,从而提高业务部署密度和资源利用率呢?
业务负载具有明显的时间上的波峰波谷,处于波谷时,空闲资源其他服务无法使用
很多面向用户的在线服务具有明显的波峰波谷,比如白天用户使用量较多,资源利用率相应较高,但是夜间用户使用量较少,资源利用率相应较低。夜间空闲出来的资源,其实都是浪费的。那夜间空闲出来的这部分资源是不是也可以用来跑离线业务呢?
在 / 离线业务混部
在线业务(latency-sensitive service):和用户存在交互的、并且对交互延时敏感的应用称为在线业务。例如:网络搜索服务、即时通讯服务、支付服务、游戏服务等,延迟对于这些服务的服务质量至关重要,故称为“延时敏感”,在线业务通常有着严格的 SLO(service-level objective)。
离线业务 (batch job):和用户不存在交互,对延时不敏感的应用称为离线业务。例如:Hadoop 生态下的 MapReduce 作业、Spark 作业、机器学习的训练作业、视频转码服务等。这些作业对于其完成时间的容忍度较高,故称为“延时不敏感”。离线业务通常没有严格的 SLO 。
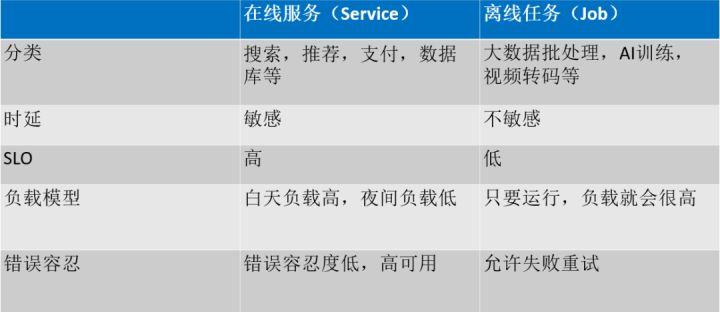 表 1 在线服务和离线服务对比
表 1 在线服务和离线服务对比
混合部署(co-location):是指将在线业务和离线业务混合部署在同一集群和服务器上。
传统的数据中心中,之所以将在 / 离线服务分开部署管理,实属无奈之举:
- 混部会带来底层共享资源(CPU、内存、网络、磁盘等)的竞争,会导致在线业务性能下降,并且这种下降是不可预测的
- 在 / 离线服务分属不同的研发、产品团队,成本管理是分开的
- 在 / 离线服务使用不同的资源调度管理系统,无法统一调度
如果能够将离线服务跑在在线服务的机器上,充分利用在线服务的空闲资源,则能够显著提升资源利用率降低服务器成本。
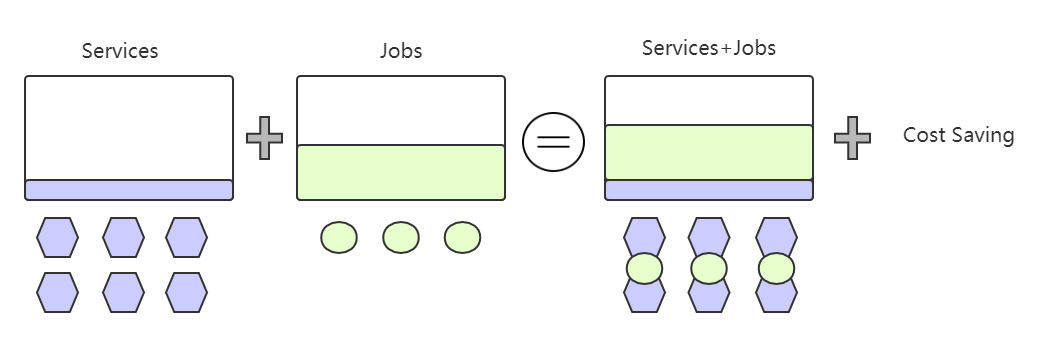 图 3 在 / 离线业务混部
图 3 在 / 离线业务混部
随着云原生理念、容器和微服务的普及,Kubernetes 逐步统治了容器编排领域,成为数据中心的基础设施。将在 / 离线业务统一使用 Kubernetes 调度管理,日渐成熟。
接下来,本章节会详细讲解如何基于 Kubernetes 实现在 / 离线业务的混部,在复杂的基础设施架构下,面对众多的共享资源,如何实现多维度的资源隔离,最小化在 / 离线业务之间的性能干扰,保证在线业务的运行性能、提升离线业务运行效率。
Kubernetes native feature
因为要基于 Kubernetes 实现在 / 离线业务的混部,所以需要先了解 Kubernetes 有哪些功能能够帮助实现混部,以及 Kubernetes 本身存在哪些问题。
Pod Priority
pod 是有优先级(pod priority)的,相应字段是pod.spec.priority,它表示了 pod 的重要程度,值越大优先级越高。调度器调度的时候会优先调度高优先级的 pod,Kubelet 在驱逐过载节点的 pod 时,会优先驱逐低优先级的 pod。
所以,可以将离线任务设置较小的 pod priority。
Pod QoS
Pod 有三种 QoS class:
Best Effort:如果 pod 的 cpu/memory 资源的 request 和 limit 都没有设置,则该 pod 属于Best Effort类型Guaranteed:如果 pod 的 cpu/memory 资源的 request 和 limit 都设置了,并且每个资源的 request 值等于 limit 值,则该 pod 属于Guaranteed类型Burstable: 剩下的则是Burstable类型
其中,Guaranteed pod 对于 SLO 要求最高,有最高的资源保证;Burstable pod 对于 SLO 要求次之,仅保证 request 部分的资源;Best Effort pod 对于 SLO 要求最低,资源无法保证。
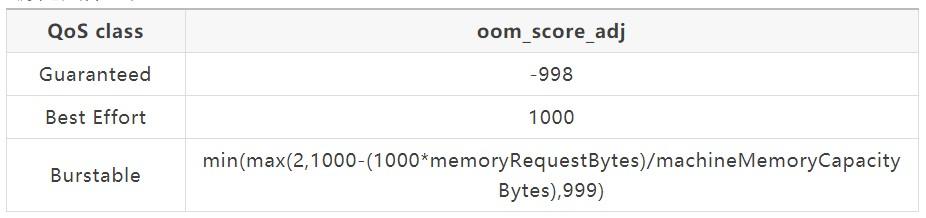 表 2 不同 QoS class pod 的 OOM Score
表 2 不同 QoS class pod 的 OOM Score
Best Effort类型 pod 的 OOM Score 是最大的,也就是说在发生系统 OOM 的时候,首先 kill 的就是Best Effort类型的 pod。
当节点上内存、磁盘等非可压缩资源负载过高时,kubelet 会驱逐上面的 pod,保证节点稳定性,驱逐的顺序是:Best Effort、Burstable、Guaranteed。
所以,是不是可以将离线任务归为Best Effort class 呢?
Kubelet CGroup Manager
Kubernetes 是使用 cgroups 来实现 pod 的资源限制的。
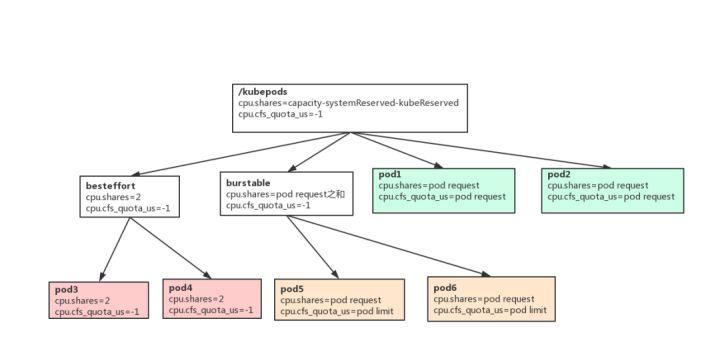 图 4 pod cpu cgroups
图 4 pod cpu cgroups
图 4 是 Kubernetes cpu cgroups 的层级,三种不同的颜色表示三种不同的 QoS class:
- kubepods 的 cpu.share 只在 kubelet 启动的时候设置一次
- besteffort 和 burstable 的 cpu.share,每隔 1 分钟更新一次. 有 pod 创建删除也会触发更新
- pod 的 cpu.share 和 cfs quota 只在创建时设置,后面不再更新
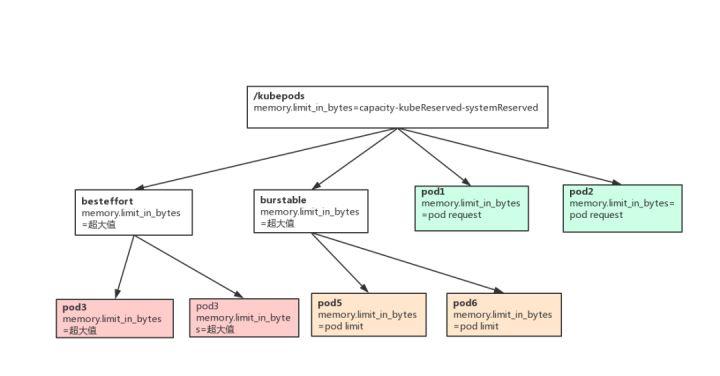 图 5 pod memory cgroups
图 5 pod memory cgroups
图 5 是 Kubernetes memory cgroups 的层级,三种不同的颜色表示三种不同的 QoS class:
- kubepods 的 memory.limit_in_bytes 只在 kubelet 启动时设置一次
- besteffort 和 burstable 的 memory.limit_in_bytes,后面不会更新
- pod 的 memory.limit_in_bytes 只在创建时设置,后面不会更新
之所以在这讲一下 Kubernetes pod cgroups 的层级组织结构和动态更新策略,是因为我们开发的资源隔离组件也是通过更改 cgroups 配置来实现资源隔离的。如果不知道 Kubernetes 原生的 cgroups 管理策略,很容易发生更新失效或者冲突,引发故障。
K8S 本身存在的问题
静态调度
Kubernetes 是使用的静态调度。静态调度是指根据容器的资源请求(resource request)进行调度,而不考虑节点的实际负载。所以,经常会发生节点负载很低,但是调度不了新的 pod 上去的情况。
Kubernetes 为什么会使用静态调度呢?因为要实现一个基于节点负载进行动态调度的通用框架是很困难的。而静态调度实现简单、管理方便,但是对于用户的要求要高一些,如果 resource request 配置的不合理,可能会导致节点之间负载不均衡以及利用率较低。
隔离性较弱
Kubernetes 是没有区分在线业务和离线业务的,当前的 cgroups 层级组织结构也很难将在 / 离线业务区分开,很难实现动态的资源分配和动态的资源隔离。所以,也无从谈起在 / 离线业务的性能隔离,顶多就是不同 pod 之间的隔离。
而 Kubernetes 对于 pod 之间的资源隔离也是很弱的,仅仅通过 cgroups 在 cpu 维度使用cpu.shares控制发生 cpu 争用时的时间片分配比例,使用cfs quota限制 cpu 使用上限;内存维度使用memory limit in bytes限制使用上限。
如果贸然将在 / 离线业务混部在同一台机器上,是无法保证在线业务的 SLO 的。
混部系统设计
我们基于 Kubernetes 实现了在 / 离线业务混部系统,遵循以下设计原则:
- 动态调度:根据节点的真实负载实现离线业务的动态调度
- 动态资源分配和隔离:根据在线业务的负载,动态调整分配给离线业务的资源量,动态执行资源隔离策略,降低甚至消除彼此之间的性能干扰
- 插件化:不对 k8s 做任何 in-tree 的侵入式改动,所有组件要基于 k8s 的扩展机制开发,并且混部系统本身扩展性强
- 及时响应:当混部节点资源利用率过高,或者对在线业务产生影响时,能够及时发现,并驱逐离线业务,以保证在线业务的 SLA
- 可运维、可观测:对用户和运维人员友好,接入成本低,使用成本低
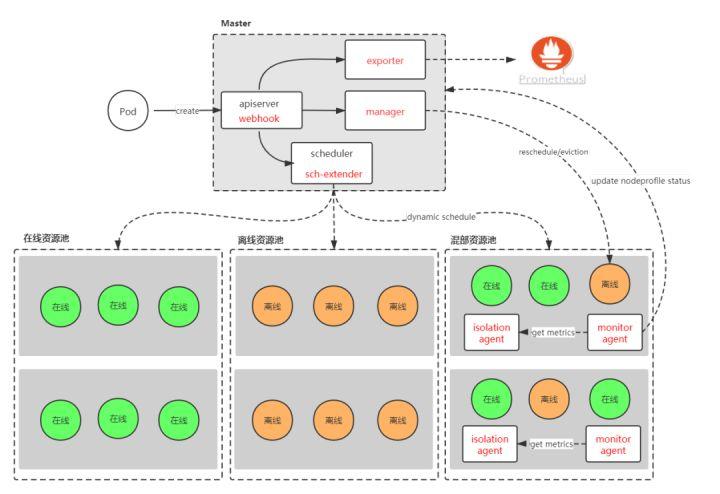 图 6 系统架构
图 6 系统架构
Resource Reclaim
Resource Reclaim 是指回收在线业务已申请的,但是目前还空闲的资源,然后给离线业务使用。这部分资源是low-quality的,没有太高的可用性保证.
我们自定义了扩展资源colocation/cpu和colocation/memory(分别对应原生的 cpu 和 memory),来表征上述 reclaimed resource,实现离线任务的动态调度。
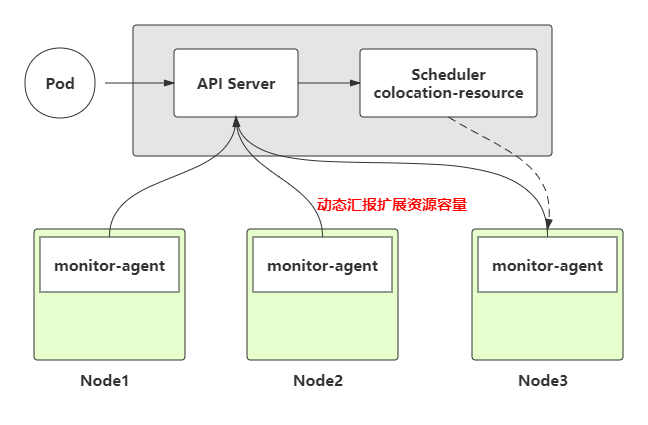 图 7 resource reclaim
图 7 resource reclaim
节点上在线业务 CPU Usage 高,则我们分配给离线业务的资源就会减少;在线业务 CPU Usage 低,则我们就可以将更多的资源分配给离线业务。
动态调度
基于扩展资源colocation/cpu和colocation/memory 实现离线任务的动态调度,优先将离线任务调度到节点负载较低、离线任务较少的混部节点上,均衡不同节点之间的负载、减少业务之间的资源竞争。
动态资源分配和动态资源隔离
Google 在数据中心资源管理领域,很多年以前就开始投入大量人力、物力。由于硬件在性能隔离上的局限性,Google 在软件层面做了大量的改造,率先提出了多项资源隔离技术,包括 cgroups、Container 等(内核的很多功能特性都是业务需求触发的,而不是凭空想象出来的)。我们对于在 / 离线业务的性能隔离也是主要通过 cgroup 来实现的。
kubelet cgroup manager 没有可扩展点,直接修改 kubelet 代码又会给后续的运维升级带来比较大的成本,因此我们单独开发了一个zeus-isolation-agent运行在每个混部节点上,通过定时动态更新 cgroup 来实现在 / 离线业务资源隔离。
 图 8 在 / 离线业务资源隔离
图 8 在 / 离线业务资源隔离
从 CPU、内存、缓存、磁盘到网络,我们实现了多维度的隔离策略,显著降低在 / 离线业务之间的互相干扰。以缓存为例,我们对内核进行了定制化改造,给在 / 离线业务设置不同的缓存回收优先级,优先回收离线业务使用的缓存。
离线业务的重调度
存在这样一种场景,刚开始时混部节点上的在线业务较少、负载较低,能够分配给离线业务的资源较多,因此用户能够调度较多的离线业务上去。但是,后来用户调度了更多的在线业务上来或者在线业务的流量飙升,导致节点上能够给离线业务的资源非常有限,离线任务执行效率会很低。假如此时,其他混部节点比较空闲,为了避免离线任务的饥饿、减小业务之间的资源竞争,我们会重调度离线任务到其他 node 上。
离线任务的重调度,主要有如下优点:
- 均衡各个混部节点的负载情况,避免有的节点负载较高而有的节点又过于空闲
- 避免某个节点负载过高,以至于影响到在线业务性能和稳定性
- 提高离线业务的执行效率
但是,重调度也有缺点,如果没有远程 checkpoint 机制,会导致重调度之前的算力被浪费。影响程度有多大,是跟单个任务的处理时长有关系的。如果处理一个任务的时长是秒级,那么重调度的影响是微乎其微的。如果处理一个任务的时长是天级别的,那么重调度的影响还是比较大的。因此,是否使用重调度功能、重调度的触发阈值等用户都是可以实现 workload 级别的配置的。
落地成果
上述在 / 离线业务混部方案已经集成到网易轻舟容器平台 NCS 中,在网易内部得到广泛应用,大幅提高了服务器资源利用率,取得显著成果。
以网易传媒为例,传媒将视频转码业务作为离线业务混部到了在线业务的机器上,混部后 CPU 利用率从 6%-15% 提高到 55% 左右。
先了解一下视频转码服务的特点:
- CPU 密集型,大量读写磁盘保存临时数据,有一定量网络 IO
- Long-running pod,而不是一个
run-to-complete类型的 pod,它会从队列中不断取视频任务进行转码处理,没有任务的话就空闲且保持运行 - 转码单个视频的时长在秒级,因此重调度对其影响是微乎其微的
Redis+ 视频转码
Redis 业务是对于时延比较敏感的在线业务,SLO 要求较高,但是其 CPU 利用率较低,因此我们尝试将视频转码业务混部到了 Redis 专属节点上,下面我们看一下这两个在 / 离业务混部的效果。
本文系作者在时代Java发表,未经许可,不得转载。
如有侵权,请联系nowjava@qq.com删除。
编辑于

关注时代Java
关注时代Java